Unifying Specialized Visual Encoders for Video Language Models
作者: Jihoon Chung, Tyler Zhu, Max Gonzalez Saez-Diez, Juan Carlos Niebles, Honglu Zhou, Olga Russakovsky
分类: cs.CV, cs.CL, cs.LG
发布日期: 2025-01-02 (更新: 2025-06-15)
备注: Accepted to ICML 2025 as a Poster. Project page: https://tylerzhu.com/merv/
💡 一句话要点
MERV:统一多个视觉编码器,提升视频语言模型的理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频语言模型 多模态融合 视觉编码器 视频理解 时空对齐 知识迁移 多专家系统
📋 核心要点
- 现有VideoLLM依赖单一视觉编码器,限制了视觉信息的多样性和模型性能。
- MERV利用多个冻结的视觉编码器,统一视频表示,提供专业视觉知识。
- 实验表明,MERV在多个视频理解任务上超越现有技术,且训练效率更高。
📝 摘要(中文)
大型语言模型(LLM)的出现为视频领域带来了强大的推理能力,催生了视频大型语言模型(VideoLLM)。然而,现有的VideoLLM通常依赖于单一视觉编码器进行所有视觉处理,限制了传递给LLM的视觉信息量和类型。本文提出了一种名为MERV(Multi-Encoder Representation of Videos,视频多编码器表示)的方法,它利用多个冻结的视觉编码器来创建视频的统一表示,为VideoLLM提供全面的专业视觉知识。通过对齐来自每个编码器的时空特征,MERV能够处理更广泛的开放式和多项选择视频理解问题,并优于现有技术。在标准视频理解基准测试中,MERV的准确率比Video-LLaVA高出3.7%,并且具有更好的Video-ChatGPT评分。此外,MERV在零样本感知测试准确率上比之前的最佳模型SeViLA提高了2.2%。MERV引入的额外参数极少,训练速度比同等单编码器方法更快,同时实现了视觉处理的并行化。定性分析表明,MERV成功地从每个编码器中捕获了领域知识。这些结果为利用多个视觉编码器进行全面的视频理解提供了有希望的方向。
🔬 方法详解
问题定义:现有VideoLLM使用单一视觉编码器,无法充分利用不同视觉模型的优势,限制了模型对视频内容的理解能力,尤其是在需要专业领域知识的任务中。现有方法难以兼顾性能和效率,训练成本高昂。
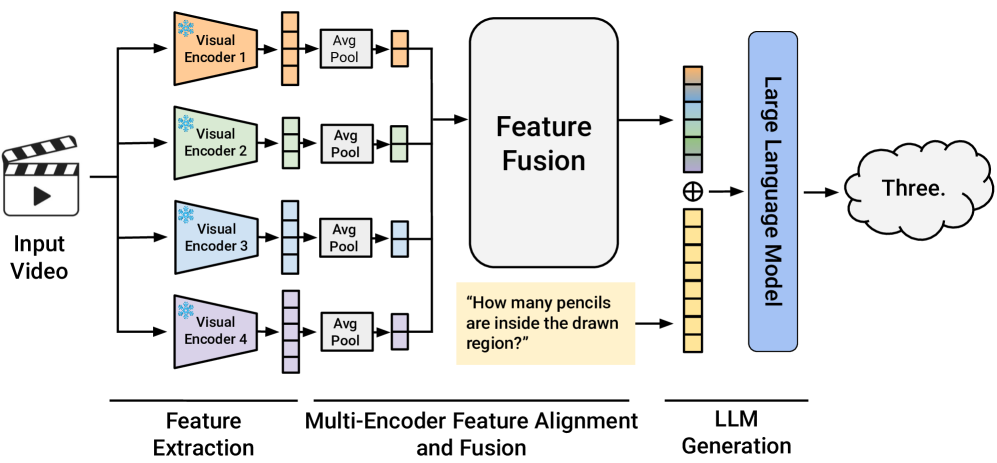
核心思路:MERV的核心思路是利用多个预训练好的、具有不同专业知识的视觉编码器,提取视频的不同方面的特征,并将这些特征融合起来,为LLM提供更全面、更丰富的视频表示。通过冻结视觉编码器,减少了训练参数,提高了训练效率。
技术框架:MERV包含多个并行的视觉编码器分支,每个分支使用一个预训练的视觉模型(例如,用于目标检测、场景识别等)。每个编码器提取视频帧的时空特征。然后,使用时空对齐模块将不同编码器的特征对齐到统一的时空坐标系中。最后,将对齐后的特征融合,输入到LLM中进行视频理解和推理。
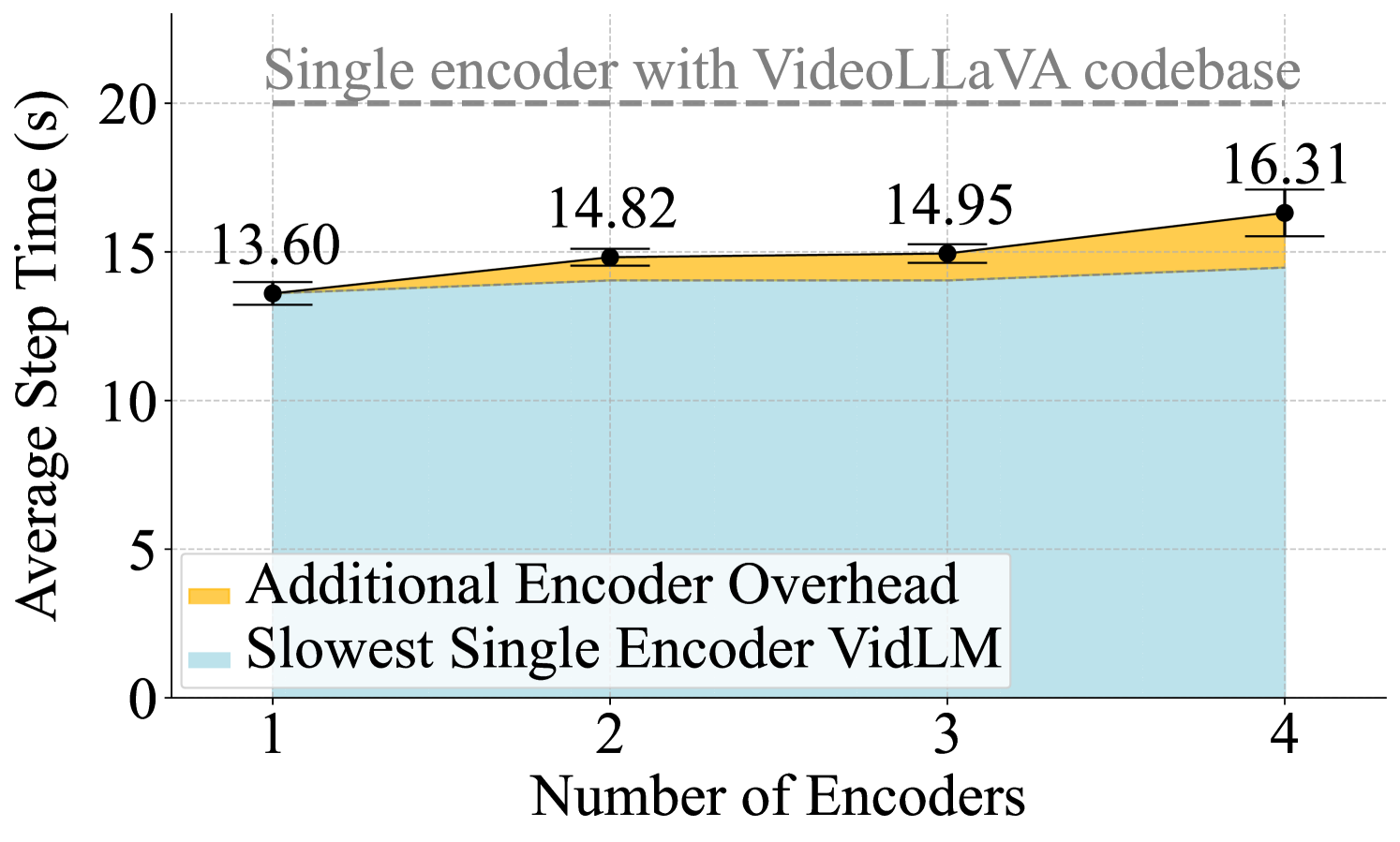
关键创新:MERV的关键创新在于利用多个预训练的视觉编码器,并设计了一种有效的时空对齐和融合机制,从而能够将不同视觉模型的优势结合起来,提高视频理解的准确性和鲁棒性。与现有方法相比,MERV不需要从头训练视觉编码器,大大降低了训练成本。
关键设计:MERV的关键设计包括:1) 选择具有不同专业知识的视觉编码器;2) 设计有效的时空对齐模块,例如使用可学习的变换矩阵或注意力机制;3) 设计合适的特征融合策略,例如使用加权平均或拼接操作;4) 使用冻结的视觉编码器,只训练对齐和融合模块,以提高训练效率。
🖼️ 关键图片

📊 实验亮点
MERV在标准视频理解基准测试中,准确率比Video-LLaVA提高了3.7%,在Video-ChatGPT评分上也有所提升。在零样本感知测试中,MERV比之前的最佳模型SeViLA提高了2.2%。此外,MERV的训练速度更快,参数量更少,表明其具有更高的效率和可扩展性。定性分析表明,MERV能够有效捕获来自不同编码器的领域知识。
🎯 应用场景
MERV具有广泛的应用前景,例如智能监控、自动驾驶、视频搜索、视频内容分析和生成等。它可以帮助机器更好地理解视频内容,从而实现更智能、更高效的视频处理和应用。例如,在智能监控中,MERV可以用于识别异常行为和事件;在自动驾驶中,MERV可以用于感知周围环境和预测交通状况。
📄 摘要(原文)
The recent advent of Large Language Models (LLMs) has ushered sophisticated reasoning capabilities into the realm of video through Video Large Language Models (VideoLLMs). However, VideoLLMs currently rely on a single vision encoder for all of their visual processing, which limits the amount and type of visual information that can be conveyed to the LLM. Our method, MERV, Multi-Encoder Representation of Videos, instead leverages multiple frozen visual encoders to create a unified representation of a video, providing the VideoLLM with a comprehensive set of specialized visual knowledge. Spatio-temporally aligning the features from each encoder allows us to tackle a wider range of open-ended and multiple-choice video understanding questions and outperform prior state-of-the-art works. MERV is up to 3.7% better in accuracy than Video-LLaVA across the standard suite video understanding benchmarks, while also having a better Video-ChatGPT score. We also improve upon SeViLA, the previous best on zero-shot Perception Test accuracy, by 2.2%. MERV introduces minimal extra parameters and trains faster than equivalent single-encoder methods while parallelizing the visual processing. Finally, we provide qualitative evidence that MERV successfully captures domain knowledge from each of its encoders. Our results offer promising directions in utilizing multiple vision encoders for comprehensive video understanding.