Reconstruction vs. Generation: Taming Optimization Dilemma in Latent Diffusion Models
作者: Jingfeng Yao, Bin Yang, Xinggang Wang
分类: cs.CV, cs.LG
发布日期: 2025-01-02 (更新: 2025-03-10)
备注: Models and codes are available at: https://github.com/hustvl/LightningDiT
🔗 代码/项目: GITHUB
💡 一句话要点
提出VA-VAE对齐预训练视觉模型,加速潜空间扩散模型训练并提升生成质量。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 潜空间扩散模型 图像生成 变分自编码器 视觉基础模型 Transformer 训练效率 高维潜空间
📋 核心要点
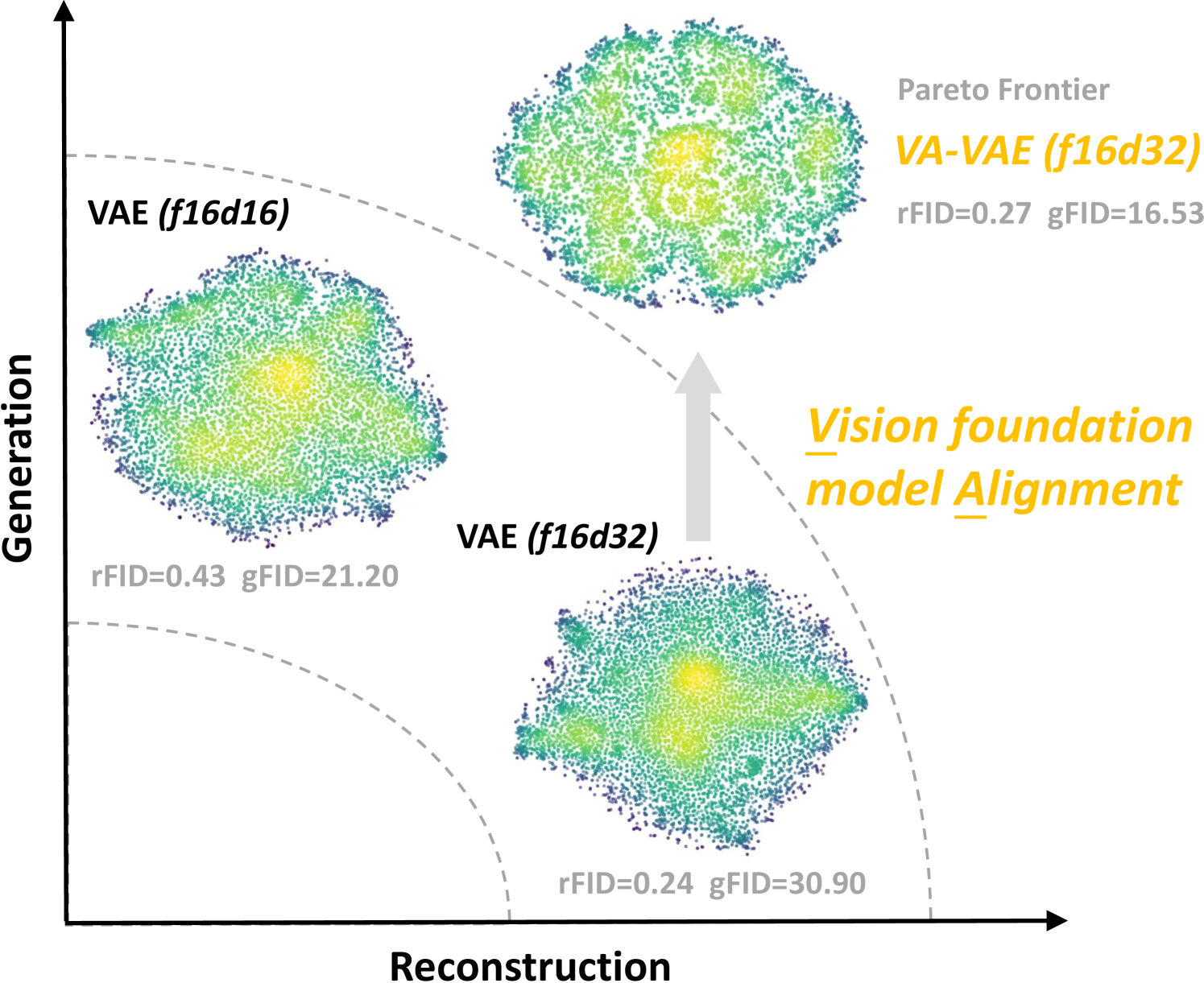
- 现有潜空间扩散模型在重建质量和生成性能之间存在优化困境,高维特征虽提升重建,但增加训练难度。
- 论文提出VA-VAE,通过对齐预训练视觉基础模型来约束潜空间,从而简化高维潜空间的学习。
- 实验表明,VA-VAE显著提升了扩散模型的训练效率和生成质量,在ImageNet 256x256上取得了SOTA结果。
📝 摘要(中文)
Transformer架构的潜空间扩散模型在生成高保真图像方面表现出色。然而,最近的研究表明,这种两阶段设计存在优化困境:增加视觉tokenizer中每个token的特征维度可以提高重建质量,但需要更大的扩散模型和更多的训练迭代才能达到相当的生成性能。因此,现有系统通常采用次优解决方案,要么由于tokenizer中的信息丢失而产生视觉伪影,要么由于昂贵的计算成本而无法完全收敛。作者认为,这种困境源于学习无约束高维潜空间的内在困难。为了解决这个问题,作者提出在训练视觉tokenizer时,将潜空间与预训练的视觉基础模型对齐。提出的VA-VAE(Vision foundation model Aligned Variational AutoEncoder)显著扩展了潜空间扩散模型的重建-生成边界,从而能够更快地在高维潜空间中收敛扩散Transformer(DiT)。为了充分利用VA-VAE的潜力,作者构建了一个增强的DiT基线,具有改进的训练策略和架构设计,称为LightningDiT。该集成系统在ImageNet 256x256生成上实现了最先进的(SOTA)性能,FID分数为1.35,同时表现出卓越的训练效率,仅用64个epoch就达到了2.11的FID分数——与原始DiT相比,收敛速度提高了21倍以上。模型和代码可在https://github.com/hustvl/LightningDiT 获取。
🔬 方法详解
问题定义:现有潜空间扩散模型在视觉tokenizer的设计上存在优化困境。为了提高图像重建质量,需要增加tokenizer中每个token的特征维度,但这会导致潜空间维度过高,使得后续的扩散模型训练更加困难,需要更大的模型和更长的训练时间才能达到理想的生成效果。现有的方法要么牺牲重建质量,要么面临巨大的计算开销。
核心思路:论文的核心思路是通过将潜空间与预训练的视觉基础模型对齐,来约束潜空间的结构,从而降低学习高维潜空间的难度。具体来说,就是利用预训练的视觉模型作为先验知识,引导tokenizer的学习,使得tokenizer生成的潜空间特征更具有语义信息,更容易被扩散模型学习。
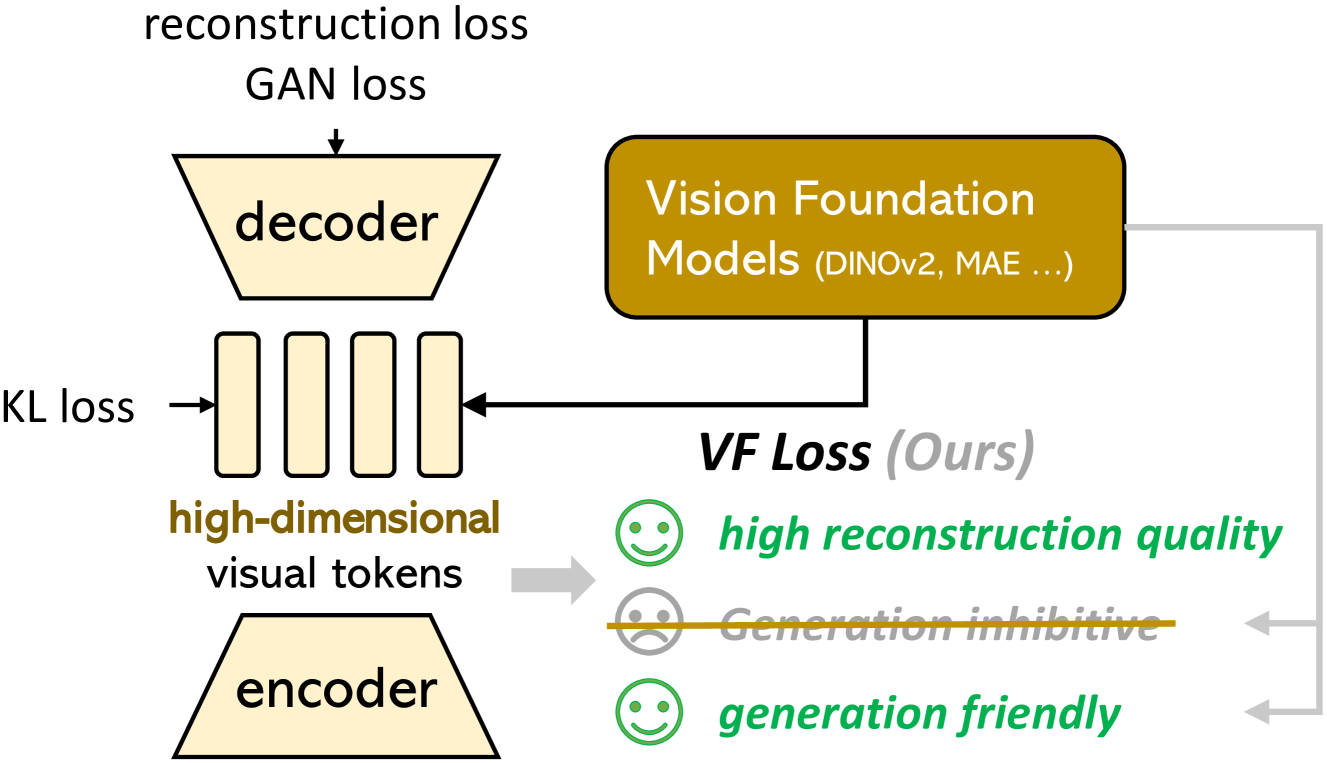
技术框架:整体框架包含两个主要阶段:1) 训练VA-VAE:使用预训练的视觉基础模型作为指导,训练一个变分自编码器(VAE),将图像编码到与视觉基础模型对齐的潜空间中。2) 训练LightningDiT:使用VA-VAE编码器将图像编码到潜空间,然后训练一个扩散Transformer(DiT)模型,学习潜空间中的噪声分布,用于生成图像。
关键创新:最重要的技术创新点是VA-VAE,即Vision foundation model Aligned Variational AutoEncoder。它通过引入预训练的视觉基础模型,将潜空间与视觉语义对齐,从而简化了高维潜空间的学习。与传统的VAE相比,VA-VAE的潜空间更具有结构性,更容易被扩散模型学习。
关键设计:VA-VAE的关键设计包括:1) 使用预训练的视觉基础模型(如CLIP)的特征作为正则化项,引导VAE的编码器学习与视觉基础模型相似的特征表示。2) 设计了一种新的损失函数,包括重建损失、KL散度损失和对齐损失,其中对齐损失用于衡量潜空间特征与视觉基础模型特征之间的相似度。3) LightningDiT在DiT的基础上进行了改进,包括使用更大的模型容量、更有效的训练策略和更优化的网络结构。
🖼️ 关键图片
📊 实验亮点
实验结果表明,提出的VA-VAE和LightningDiT在ImageNet 256x256图像生成任务上取得了SOTA性能,FID分数为1.35。与原始DiT相比,LightningDiT的训练效率显著提高,仅用64个epoch就达到了2.11的FID分数,收敛速度提高了21倍以上。这些结果表明,该方法能够有效提高扩散模型的生成质量和训练效率。
🎯 应用场景
该研究成果可广泛应用于图像生成、图像编辑、图像修复等领域。通过对齐预训练视觉模型,可以生成更高质量、更逼真的图像,并降低训练成本。此外,该方法还可以应用于其他模态的数据生成,例如文本生成、音频生成等,具有广阔的应用前景。
📄 摘要(原文)
Latent diffusion models with Transformer architectures excel at generating high-fidelity images. However, recent studies reveal an optimization dilemma in this two-stage design: while increasing the per-token feature dimension in visual tokenizers improves reconstruction quality, it requires substantially larger diffusion models and more training iterations to achieve comparable generation performance. Consequently, existing systems often settle for sub-optimal solutions, either producing visual artifacts due to information loss within tokenizers or failing to converge fully due to expensive computation costs. We argue that this dilemma stems from the inherent difficulty in learning unconstrained high-dimensional latent spaces. To address this, we propose aligning the latent space with pre-trained vision foundation models when training the visual tokenizers. Our proposed VA-VAE (Vision foundation model Aligned Variational AutoEncoder) significantly expands the reconstruction-generation frontier of latent diffusion models, enabling faster convergence of Diffusion Transformers (DiT) in high-dimensional latent spaces. To exploit the full potential of VA-VAE, we build an enhanced DiT baseline with improved training strategies and architecture designs, termed LightningDiT. The integrated system achieves state-of-the-art (SOTA) performance on ImageNet 256x256 generation with an FID score of 1.35 while demonstrating remarkable training efficiency by reaching an FID score of 2.11 in just 64 epochs--representing an over 21 times convergence speedup compared to the original DiT. Models and codes are available at: https://github.com/hustvl/LightningDiT.