ViGiL3D: A Linguistically Diverse Dataset for 3D Visual Grounding
作者: Austin T. Wang, ZeMing Gong, Angel X. Chang
分类: cs.CV, cs.AI, cs.CL
发布日期: 2025-01-02 (更新: 2025-07-07)
备注: 24 pages with 8 figures and 14 tables; updated for ACL 2025 camera-ready with additional discussion and figures
💡 一句话要点
ViGiL3D:一个语言多样化的3D视觉定位数据集,用于提升模型泛化性。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D视觉定位 数据集 语言多样性 自然语言理解 具身智能
📋 核心要点
- 现有3D视觉定位数据集在语言多样性方面存在不足,无法充分覆盖真实场景中可能出现的各种自然语言描述。
- ViGiL3D数据集通过语言分析框架,构建了包含多种语言模式的3D视觉定位提示,旨在诊断现有方法的局限性。
- 实验表明,现有开放词汇3D视觉定位方法在处理ViGiL3D数据集中更具挑战性的提示时,性能显著下降。
📝 摘要(中文)
3D视觉定位(3DVG)是指在3D场景中定位自然语言文本所指代的实体。这种模型对于具身智能和场景检索应用非常有用,这些应用涉及使用自然语言描述来搜索对象或模式。虽然最近的工作主要集中在使用LLM来扩展3DVG数据集,但这些数据集并未涵盖英语中可能出现的全部提示范围。为了确保我们能够扩展并测试一个有用且具有代表性的提示集合,我们提出了一个语言分析框架,并引入了ViGiL3D(Visual Grounding with Diverse Language in 3D),这是一个诊断数据集,用于评估视觉定位方法在各种语言模式下的性能。我们评估了现有的开放词汇3DVG方法,结果表明这些方法尚未熟练地理解和识别更具挑战性的、分布外的提示目标,这对于实际应用至关重要。
🔬 方法详解
问题定义:论文旨在解决现有3D视觉定位(3DVG)数据集缺乏语言多样性的问题。现有数据集无法充分覆盖真实世界应用中可能出现的各种自然语言描述,导致模型在处理分布外(out-of-distribution)的提示时性能下降。这限制了3DVG模型在具身智能和场景检索等实际应用中的有效性。
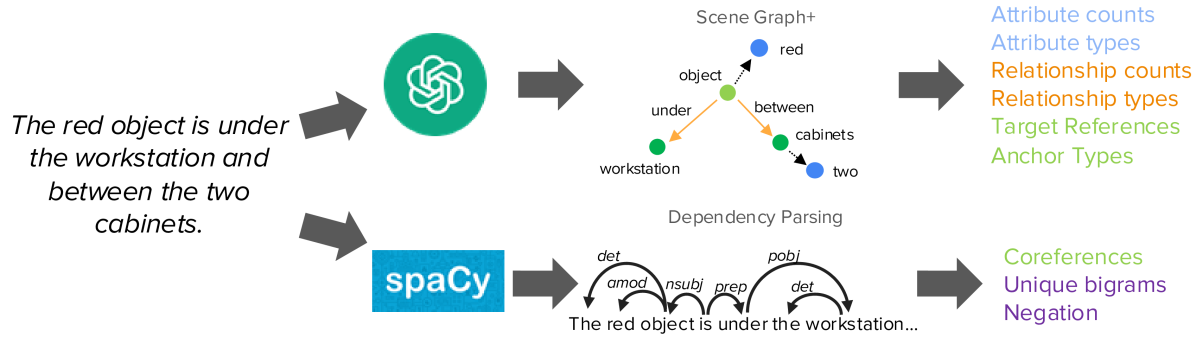
核心思路:论文的核心思路是构建一个语言多样化的3DVG数据集,即ViGiL3D。通过对自然语言进行语言学分析,识别出不同的语言模式,并针对这些模式设计相应的3D视觉定位提示。这样可以更全面地评估和提升3DVG模型对各种语言表达的理解能力。
技术框架:ViGiL3D的构建框架主要包含以下几个阶段:1) 语言分析:对自然语言进行分析,识别出不同的语言模式,例如比较、否定、属性描述等。2) 提示生成:根据识别出的语言模式,生成相应的3D视觉定位提示。3) 数据标注:对生成的提示进行标注,确定3D场景中对应的目标对象。4) 数据集构建:将生成的提示和标注信息整合,构建成ViGiL3D数据集。
关键创新:ViGiL3D的关键创新在于其语言多样性。与现有数据集相比,ViGiL3D包含了更广泛的语言模式,能够更全面地评估3DVG模型对自然语言的理解能力。这种语言多样性是通过对自然语言进行语言学分析,并针对不同的语言模式设计提示来实现的。
关键设计:论文中没有明确给出关键的参数设置、损失函数或网络结构等技术细节。ViGiL3D的主要贡献在于数据集本身,以及构建数据集的语言分析框架。数据集的质量和多样性是其关键设计。
🖼️ 关键图片


📊 实验亮点
论文通过在ViGiL3D数据集上评估现有开放词汇3D视觉定位方法,发现这些方法在处理更具挑战性的、分布外的提示时性能显著下降。这表明现有方法在语言理解方面仍存在局限性,需要进一步改进。ViGiL3D数据集的发布为研究人员提供了一个评估和改进3D视觉定位模型的有效工具。
🎯 应用场景
ViGiL3D数据集可用于训练和评估3D视觉定位模型,提升其在具身智能、场景检索、机器人导航等领域的性能。该数据集能够帮助研究人员开发更鲁棒、更通用的3D视觉定位系统,从而推动相关技术在智能家居、自动驾驶、虚拟现实等领域的应用。
📄 摘要(原文)
3D visual grounding (3DVG) involves localizing entities in a 3D scene referred to by natural language text. Such models are useful for embodied AI and scene retrieval applications, which involve searching for objects or patterns using natural language descriptions. While recent works have focused on LLM-based scaling of 3DVG datasets, these datasets do not capture the full range of potential prompts which could be specified in the English language. To ensure that we are scaling up and testing against a useful and representative set of prompts, we propose a framework for linguistically analyzing 3DVG prompts and introduce Visual Grounding with Diverse Language in 3D (ViGiL3D), a diagnostic dataset for evaluating visual grounding methods against a diverse set of language patterns. We evaluate existing open-vocabulary 3DVG methods to demonstrate that these methods are not yet proficient in understanding and identifying the targets of more challenging, out-of-distribution prompts, toward real-world applications.