Towards Interactive Deepfake Analysis
作者: Lixiong Qin, Ning Jiang, Yang Zhang, Yuhan Qiu, Dingheng Zeng, Jiani Hu, Weihong Deng
分类: cs.CV
发布日期: 2025-01-02
🔗 代码/项目: GITHUB
💡 一句话要点
提出DFA-GPT交互式深度伪造分析系统,提升深度伪造检测与分析能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 深度伪造检测 多模态大语言模型 指令微调 交互式分析 数据增强
📋 核心要点
- 现有深度伪造分析方法依赖判别模型,缺乏交互性和泛化能力,限制了应用场景。
- 论文提出基于多模态大语言模型的指令微调方法,构建交互式深度伪造分析系统DFA-GPT。
- 构建DFA-Instruct数据集和DFA-Bench基准,并使用LoRA优化,为社区提供强大基线。
📝 摘要(中文)
现有的深度伪造分析方法主要基于判别模型,这极大地限制了它们的应用场景。本文旨在通过对多模态大型语言模型(MLLM)进行指令微调,探索交互式深度伪造分析。这项工作面临数据集和基准的缺乏以及训练效率低下的挑战。为了解决这些问题,我们引入了:(1)一个GPT辅助的数据构建过程,产生一个名为DFA-Instruct的指令跟随数据集;(2)一个名为DFA-Bench的基准,旨在全面评估MLLM在深度伪造检测、深度伪造分类和伪影描述方面的能力;(3)构建了一个名为DFA-GPT的交互式深度伪造分析系统,作为社区的强大基线,并使用了低秩适应(LoRA)模块。数据集和代码将在https://github.com/lxq1000/DFA-Instruct上提供,以促进进一步的研究。
🔬 方法详解
问题定义:现有深度伪造分析方法主要依赖判别模型,缺乏与用户的交互能力,难以进行深入分析和解释。此外,缺乏专门用于评估多模态大语言模型在深度伪造分析方面能力的基准数据集。
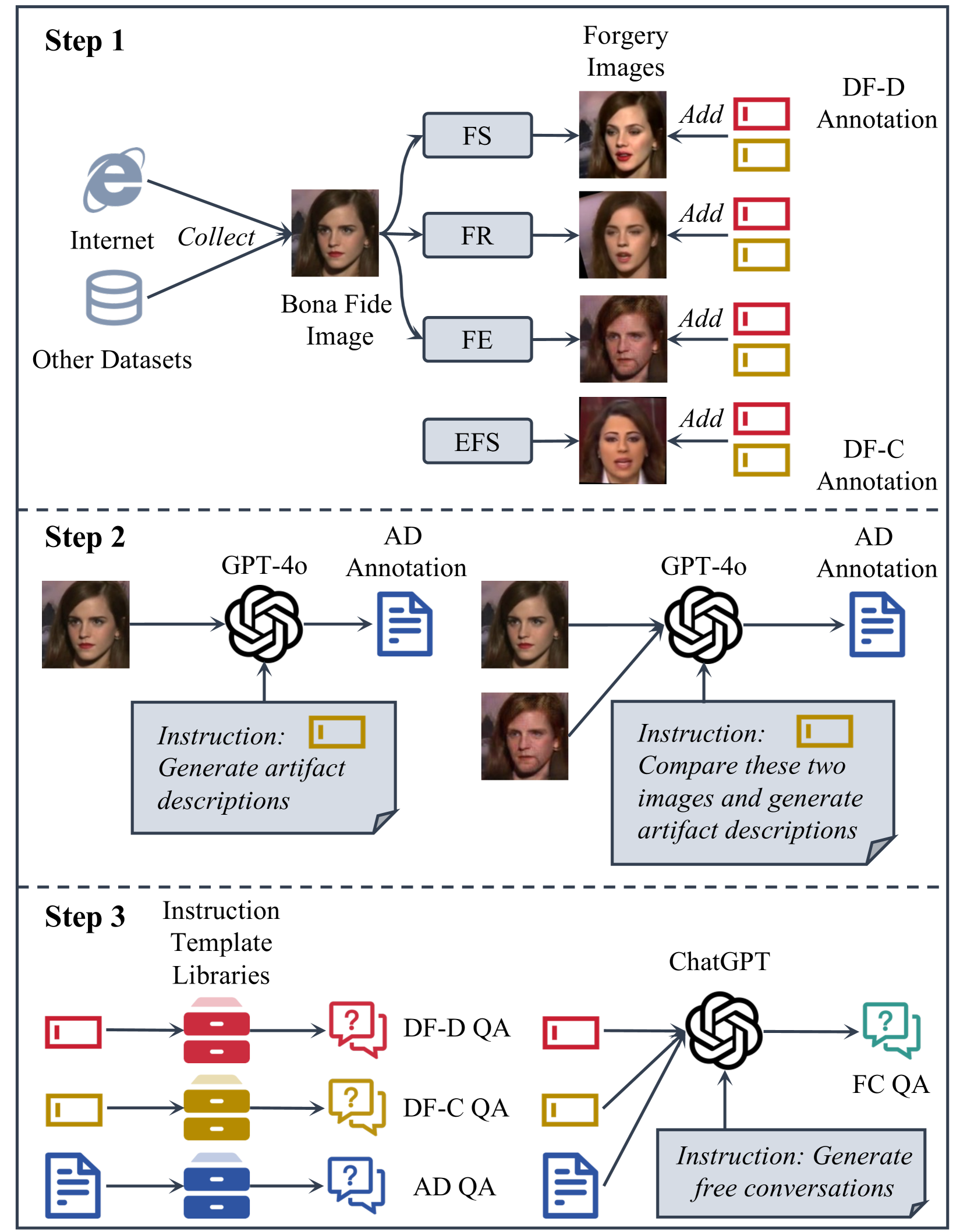
核心思路:利用多模态大语言模型(MLLM)的强大理解和生成能力,通过指令微调使其能够理解用户指令,并进行深度伪造检测、分类和伪影描述等任务。通过GPT辅助的数据生成,解决数据集匮乏的问题。
技术框架:DFA-GPT系统基于MLLM,采用指令微调的方式进行训练。整体流程包括:1) 使用GPT辅助生成DFA-Instruct数据集,包含深度伪造检测、分类和伪影描述等任务的指令和答案;2) 在DFA-Instruct数据集上,使用LoRA对MLLM进行指令微调;3) 构建DFA-Bench基准,用于评估DFA-GPT以及其他MLLM在深度伪造分析方面的性能。
关键创新:核心创新在于将多模态大语言模型引入深度伪造分析领域,并利用指令微调实现交互式分析。与传统的判别模型相比,DFA-GPT能够理解用户指令,并生成自然语言描述,提供更丰富的分析结果。GPT辅助的数据生成方法,有效解决了数据集匮乏的问题。
关键设计:DFA-Instruct数据集包含多种类型的深度伪造图像和视频,以及对应的指令和答案。指令涵盖深度伪造检测(判断真伪)、分类(识别伪造类型)和伪影描述(描述伪造痕迹)等任务。LoRA模块用于降低训练成本,提高训练效率。DFA-Bench基准包含多个评估指标,用于全面评估MLLM在深度伪造分析方面的能力。
🖼️ 关键图片


📊 实验亮点
论文构建了DFA-Instruct数据集和DFA-Bench基准,为深度伪造分析领域的研究提供了重要资源。DFA-GPT系统在DFA-Bench上取得了显著的性能,证明了多模态大语言模型在深度伪造分析方面的潜力。LoRA的使用有效降低了训练成本,提高了训练效率。
🎯 应用场景
该研究成果可应用于社交媒体平台的内容审核、新闻媒体的真实性验证、以及安全领域的身份认证等方面。通过交互式分析,可以更有效地检测和识别深度伪造内容,减少虚假信息传播,维护社会安全和稳定。未来可进一步扩展到其他类型的多媒体内容分析,例如语音和文本。
📄 摘要(原文)
Existing deepfake analysis methods are primarily based on discriminative models, which significantly limit their application scenarios. This paper aims to explore interactive deepfake analysis by performing instruction tuning on multi-modal large language models (MLLMs). This will face challenges such as the lack of datasets and benchmarks, and low training efficiency. To address these issues, we introduce (1) a GPT-assisted data construction process resulting in an instruction-following dataset called DFA-Instruct, (2) a benchmark named DFA-Bench, designed to comprehensively evaluate the capabilities of MLLMs in deepfake detection, deepfake classification, and artifact description, and (3) construct an interactive deepfake analysis system called DFA-GPT, as a strong baseline for the community, with the Low-Rank Adaptation (LoRA) module. The dataset and code will be made available at https://github.com/lxq1000/DFA-Instruct to facilitate further research.