3D-LLaVA: Towards Generalist 3D LMMs with Omni Superpoint Transformer
作者: Jiajun Deng, Tianyu He, Li Jiang, Tianyu Wang, Feras Dayoub, Ian Reid
分类: cs.CV
发布日期: 2025-01-02 (更新: 2025-04-24)
备注: Accepted by CVPR 2025
💡 一句话要点
3D-LLaVA:利用全能超点Transformer构建通用3D多模态大模型
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 3D多模态大模型 点云处理 Transformer 人机交互 场景理解
📋 核心要点
- 现有3D多模态大模型在细粒度场景理解和灵活人机交互方面仍面临挑战。
- 3D-LLaVA通过全能超点Transformer(OST)统一处理视觉特征选择、提示编码和掩码解码。
- 实验表明,3D-LLaVA在多个基准测试中表现出色,验证了其有效性。
📝 摘要(中文)
本文提出3D-LLaVA,一个简单而强大的3D多模态大模型,旨在作为智能助手理解、推理和交互3D世界。与依赖复杂流程(如离线多视角特征提取或特定任务头部)的现有方法不同,3D-LLaVA采用极简设计,集成架构,仅以点云作为输入。其核心是新的全能超点Transformer(OST),集成了三种功能:(1)视觉特征选择器,用于转换和选择视觉tokens;(2)视觉提示编码器,将交互式视觉提示嵌入到视觉token空间;(3)参考掩码解码器,基于文本描述生成3D掩码。这种多功能的OST通过混合预训练获得感知先验,并作为视觉连接器,将3D数据桥接到LLM。经过统一的指令微调后,3D-LLaVA在各种基准测试中取得了令人印象深刻的结果。
🔬 方法详解
问题定义:现有3D多模态模型通常依赖复杂的pipeline,例如离线多视角特征提取,或者需要针对特定任务设计额外的头部,这增加了模型的复杂性和训练成本。此外,如何实现细粒度的场景理解和灵活的人机交互仍然是一个挑战。
核心思路:3D-LLaVA的核心思路是采用一个极简的设计,直接以点云作为输入,并通过一个统一的Transformer结构(OST)来处理各种3D视觉任务。这种设计旨在简化模型结构,提高训练效率,并增强模型的通用性。
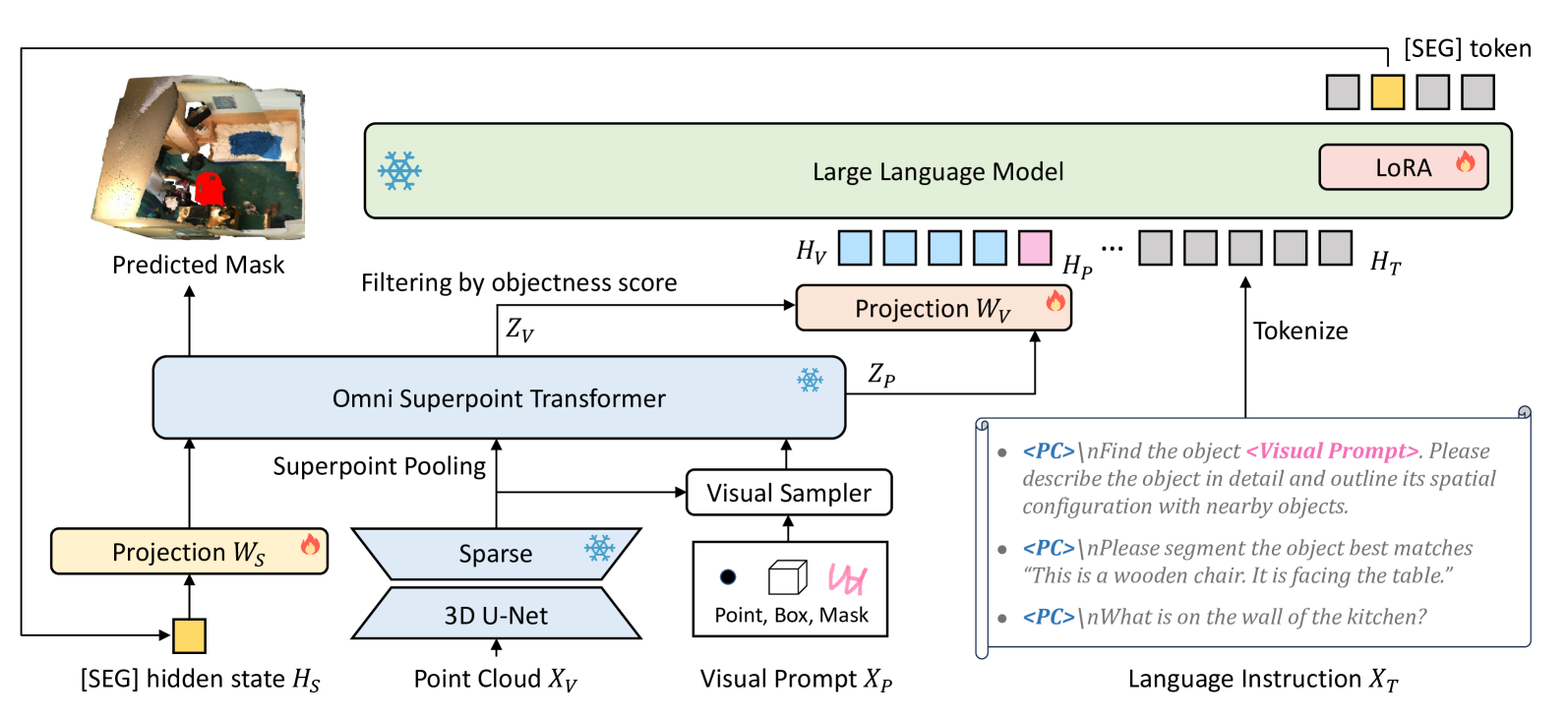
技术框架:3D-LLaVA的整体架构包括三个主要部分:点云输入、全能超点Transformer(OST)和大型语言模型(LLM)。点云数据直接输入到OST中,OST负责提取视觉特征、编码视觉提示和解码3D掩码。然后,OST的输出被连接到LLM,用于进行对话和推理。
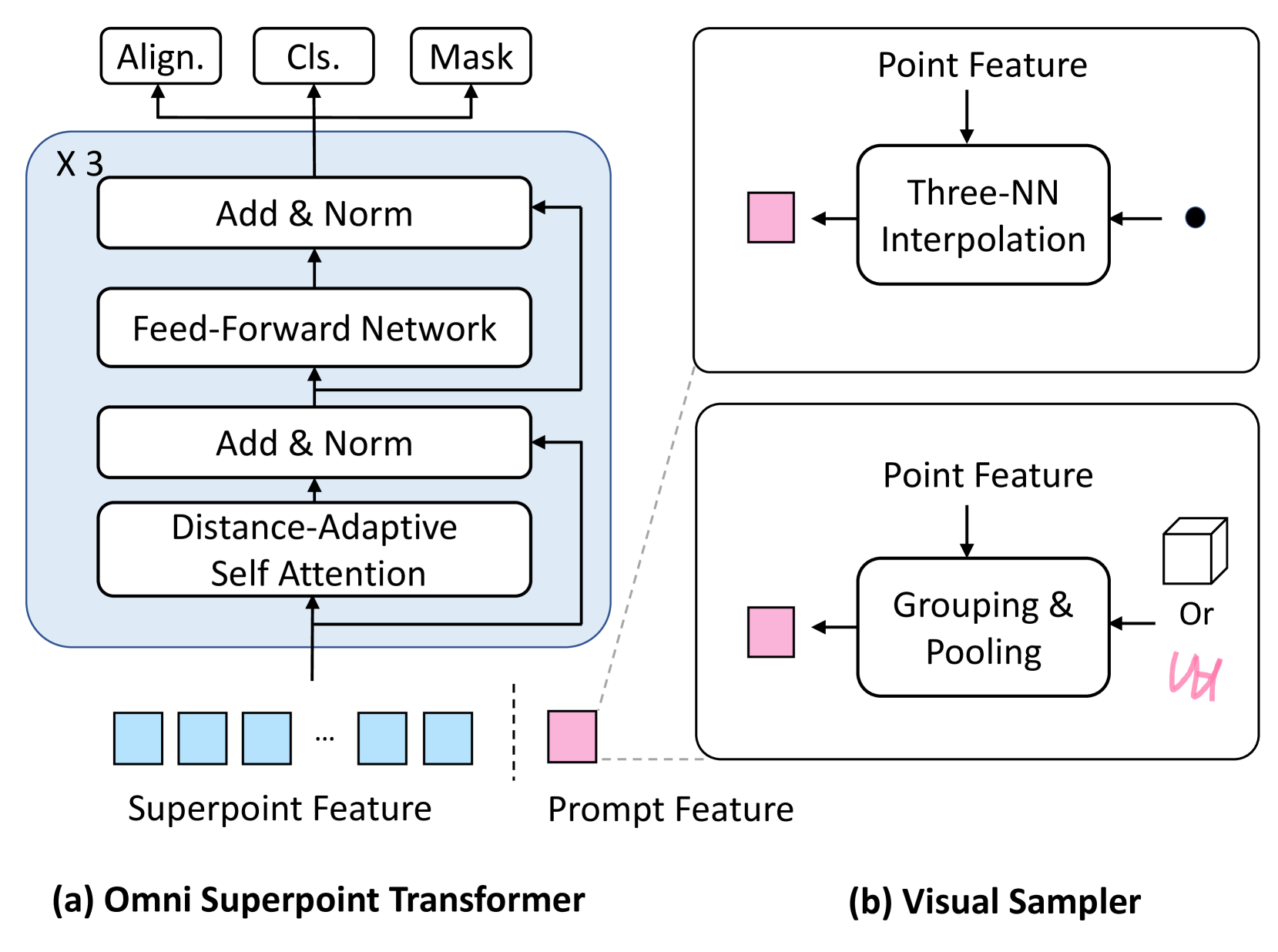
关键创新:最重要的技术创新点是全能超点Transformer(OST)。OST集成了视觉特征选择器、视觉提示编码器和参考掩码解码器三种功能,使得模型能够同时处理感知、交互和分割任务。这种统一的设计避免了传统方法中需要多个独立模块的问题,提高了模型的效率和通用性。
关键设计:OST的关键设计包括:(1) 使用Transformer结构来处理点云数据,能够捕捉点云之间的长程依赖关系;(2) 采用混合预训练策略,使得模型能够学习到丰富的3D视觉先验知识;(3) 使用统一的指令微调策略,使得模型能够适应各种不同的3D视觉任务。
🖼️ 关键图片
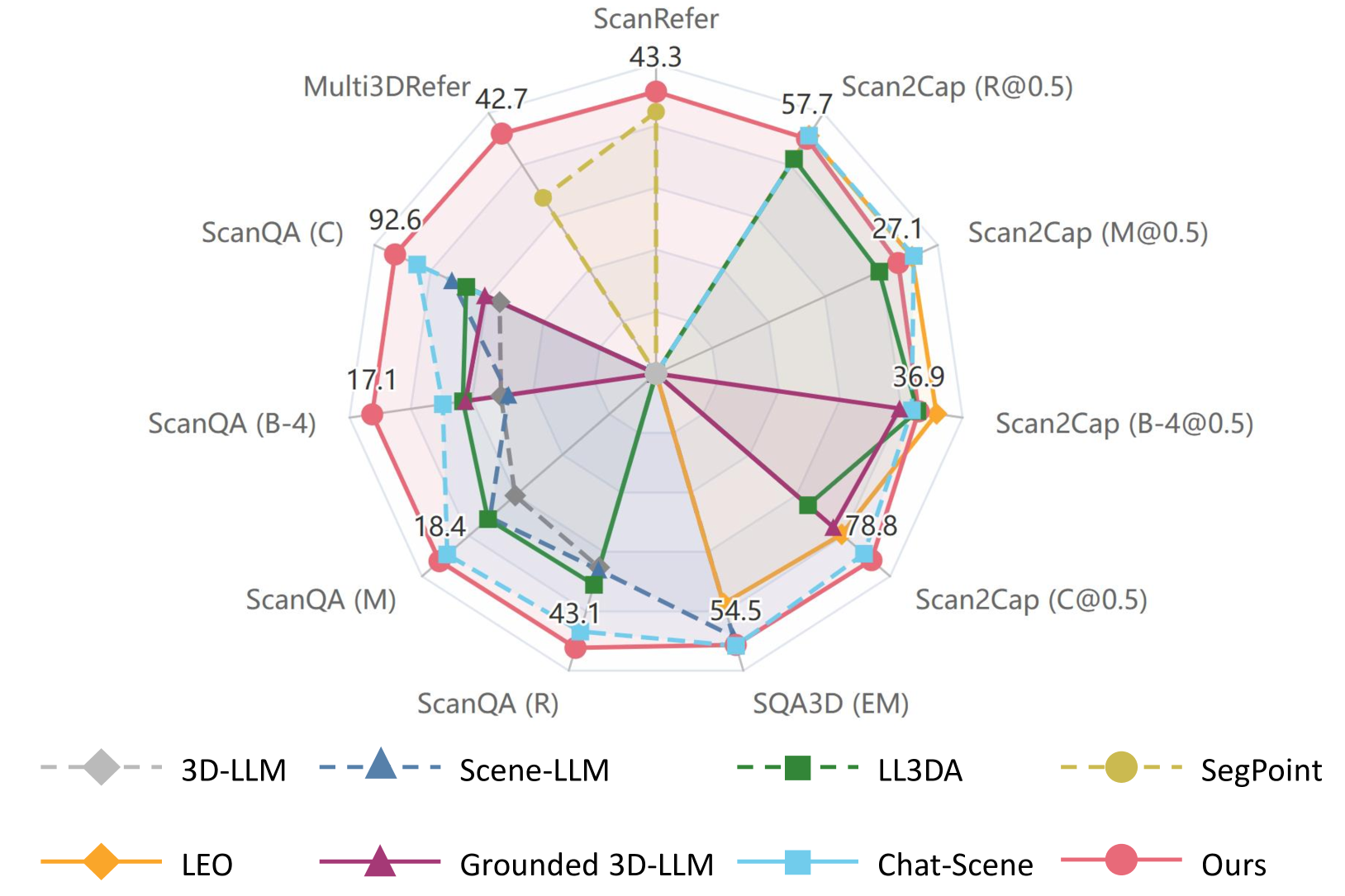
📊 实验亮点
3D-LLaVA在多个3D视觉基准测试中取得了显著成果,证明了其有效性。与现有方法相比,3D-LLaVA在不需要复杂pipeline和特定任务头部的情况下,实现了更高的性能。这表明3D-LLaVA具有更强的通用性和更高的效率。
🎯 应用场景
3D-LLaVA具有广泛的应用前景,例如智能家居、机器人导航、自动驾驶、虚拟现实和增强现实等领域。它可以作为智能助手,帮助人们理解和交互3D环境,从而提高工作效率和生活质量。未来,该模型有望应用于更复杂的3D场景理解和人机交互任务。
📄 摘要(原文)
Current 3D Large Multimodal Models (3D LMMs) have shown tremendous potential in 3D-vision-based dialogue and reasoning. However, how to further enhance 3D LMMs to achieve fine-grained scene understanding and facilitate flexible human-agent interaction remains a challenging problem. In this work, we introduce 3D-LLaVA, a simple yet highly powerful 3D LMM designed to act as an intelligent assistant in comprehending, reasoning, and interacting with the 3D world. Unlike existing top-performing methods that rely on complicated pipelines-such as offline multi-view feature extraction or additional task-specific heads-3D-LLaVA adopts a minimalist design with integrated architecture and only takes point clouds as input. At the core of 3D-LLaVA is a new Omni Superpoint Transformer (OST), which integrates three functionalities: (1) a visual feature selector that converts and selects visual tokens, (2) a visual prompt encoder that embeds interactive visual prompts into the visual token space, and (3) a referring mask decoder that produces 3D masks based on text description. This versatile OST is empowered by the hybrid pretraining to obtain perception priors and leveraged as the visual connector that bridges the 3D data to the LLM. After performing unified instruction tuning, our 3D-LLaVA reports impressive results on various benchmarks.