Source-free Semantic Regularization Learning for Semi-supervised Domain Adaptation
作者: Xinyang Huang, Chuang Zhu, Ruiying Ren, Shengjie Liu, Tiejun Huang
分类: cs.CV
发布日期: 2025-01-02
💡 一句话要点
提出SERL框架,通过语义正则化学习提升半监督领域自适应性能
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction)
关键词: 半监督领域自适应 语义正则化 对比学习 混合样本 伪标签
📋 核心要点
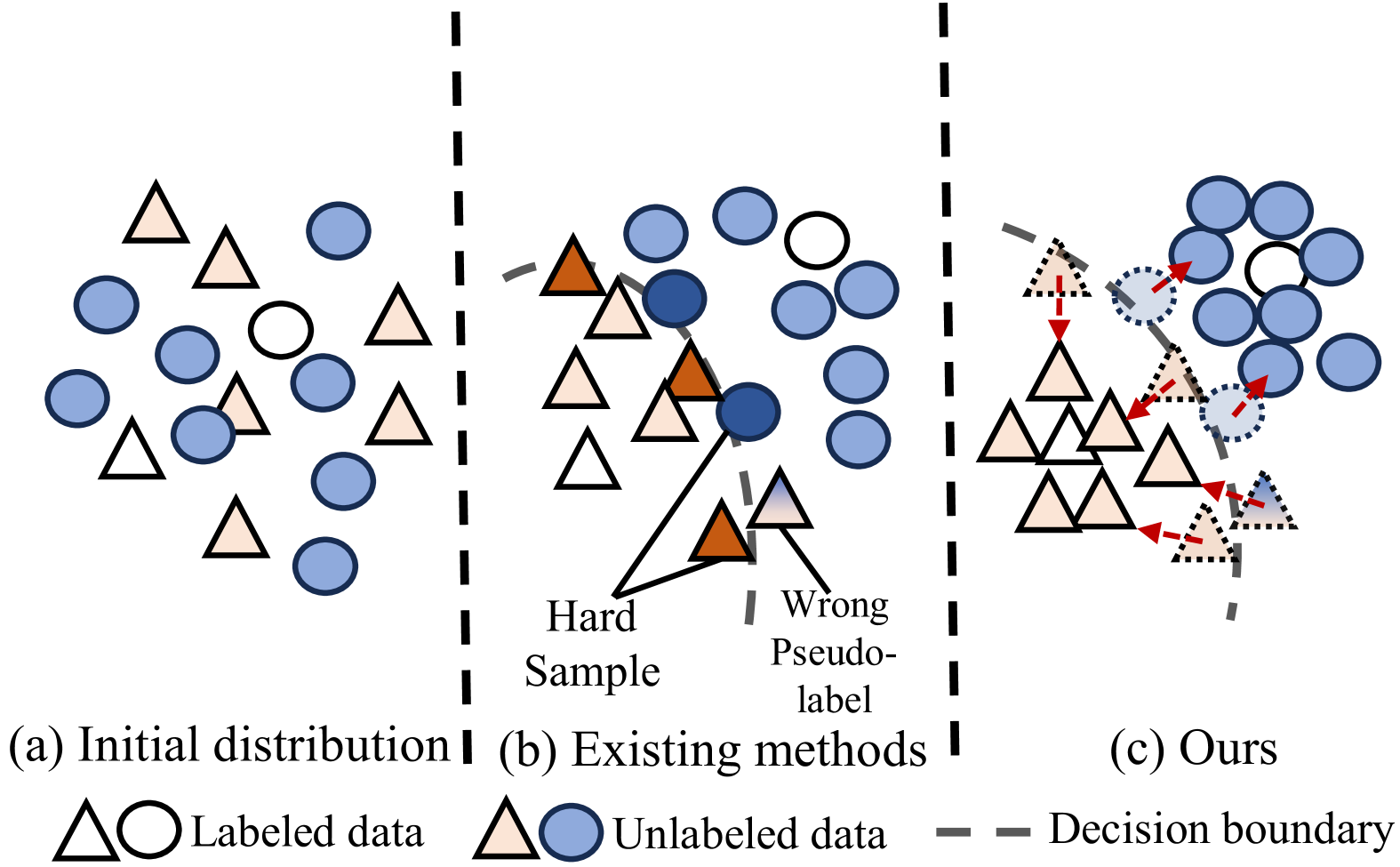
- 现有SSDA方法难以充分学习目标域丰富而复杂的语义信息和关系,导致模型无法有效适应目标域。
- SERL框架通过语义概率对比正则化、难样本混合正则化和目标预测正则化,从多角度捕获目标域语义信息。
- 在多个基准数据集上的实验表明,SERL方法显著提升了SSDA的性能,达到了state-of-the-art水平。
📝 摘要(中文)
本文提出了一种新颖的半监督领域自适应(SSDA)学习框架,称为语义正则化学习(SERL),旨在通过多角度的正则化学习捕获目标域的语义信息,从而实现源域预训练模型在目标域上的自适应微调。SERL包含三种鲁棒的语义正则化技术。首先,语义概率对比正则化(SPCR)从概率角度利用目标域的语义信息,学习更具区分性的特征表示,理解样本间的相似性和差异性,并自适应地调整权重以正确学习语义分布。其次,引入难样本混合正则化(HMR),利用简单样本作为指导,挖掘难样本中蕴含的潜在目标知识,从而学习更完整和复杂的目标语义知识。最后,目标预测正则化(TPR)通过最大化当前预测与过去学习目标之间的相关性来约束模型的预测,从而减轻错误伪标签导致的语义信息误导。在三个基准数据集上的大量实验表明,SERL方法实现了最先进的性能。
🔬 方法详解
问题定义:半监督领域自适应(SSDA)旨在利用少量目标域的标注数据,提升模型在目标域上的泛化能力。现有方法的痛点在于,难以充分挖掘和利用目标域的语义信息,导致模型无法有效地从源域迁移到目标域,尤其是在目标域数据分布复杂的情况下。
核心思路:本文的核心思路是通过引入多种语义正则化技术,从不同角度约束模型学习目标域的语义信息。具体来说,通过概率对比学习样本间的关系,利用简单样本指导学习难样本,以及约束目标域预测的一致性,从而更全面、准确地学习目标域的语义分布。这样设计的目的是为了克服现有方法在目标域语义信息挖掘上的不足,提升模型的自适应能力。
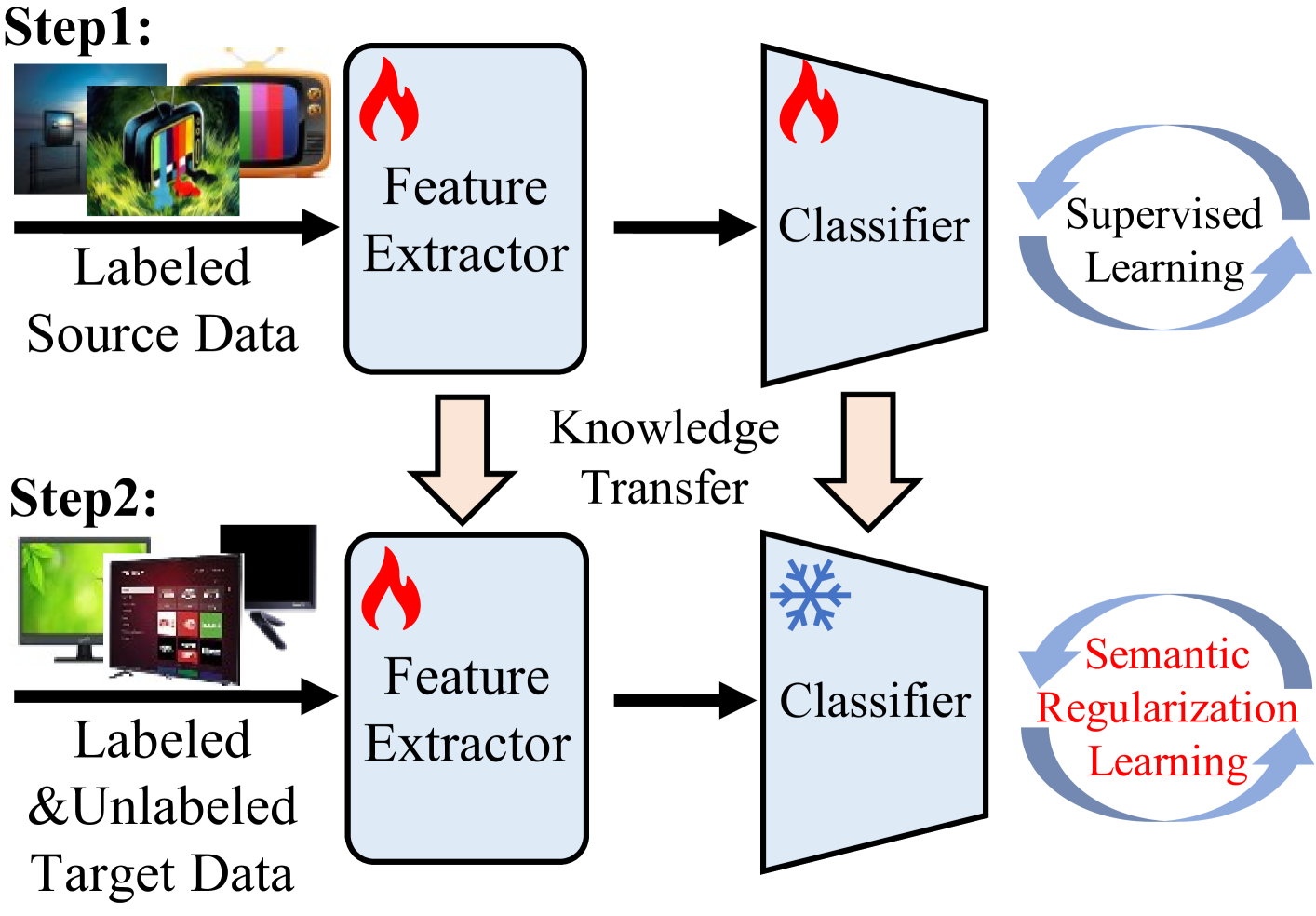
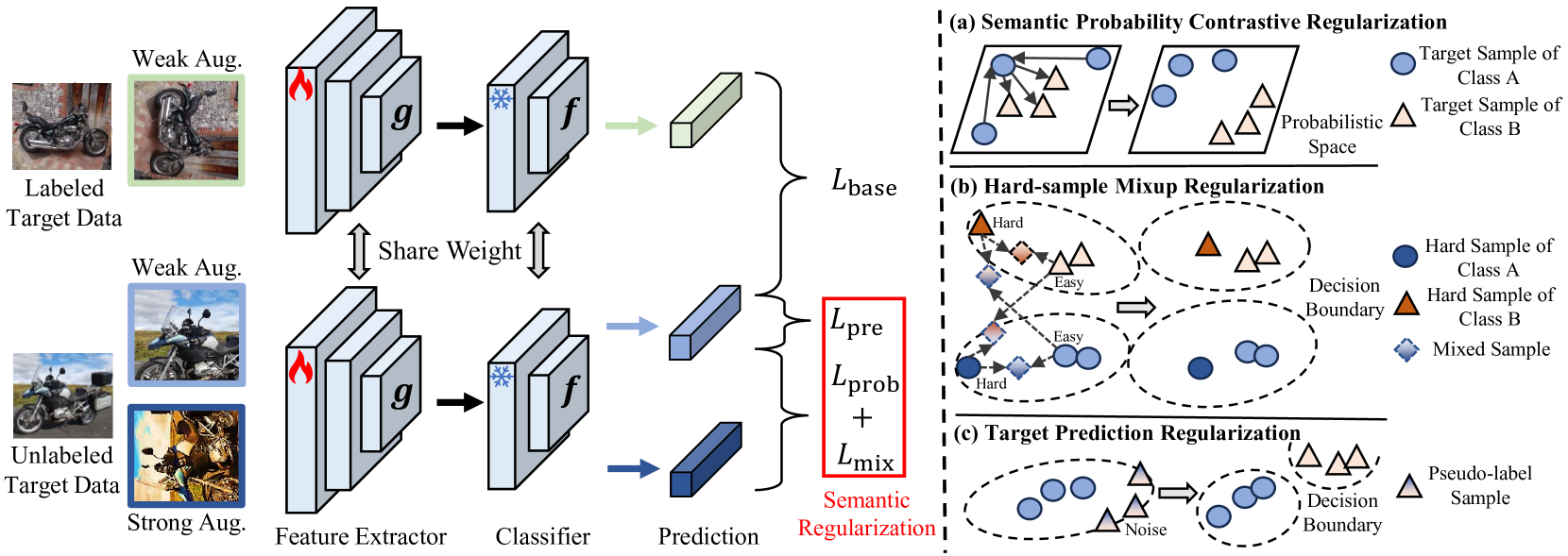
技术框架:SERL框架主要包含三个模块:语义概率对比正则化(SPCR)、难样本混合正则化(HMR)和目标预测正则化(TPR)。首先,SPCR从概率角度对比样本特征,学习样本间的相似性和差异性。然后,HMR利用简单样本的知识指导模型学习难样本的潜在知识。最后,TPR通过约束模型预测的一致性,减少错误伪标签的影响。这三个模块相互配合,共同提升模型对目标域语义信息的理解。
关键创新:SERL的关键创新在于提出了一个多角度的语义正则化学习框架,它不是单一地依赖某种正则化方法,而是综合利用了概率对比学习、混合样本学习和预测一致性约束等多种技术,从而更全面、更鲁棒地学习目标域的语义信息。与现有方法相比,SERL能够更好地适应目标域的数据分布,提升模型的泛化能力。
关键设计:SPCR中,自适应权重用于调整不同样本对损失函数的贡献,帮助模型正确学习语义分布。HMR中,混合比例的选择影响着简单样本对难样本的指导作用,需要仔细调整。TPR中,过去学习目标的表示方式以及相关性度量方式都会影响正则化的效果。损失函数由三部分组成,分别是SPCR损失、HMR损失和TPR损失,通过调整各个损失的权重来平衡不同正则化项的作用。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SERL在三个基准数据集上均取得了state-of-the-art的性能。例如,在Office-Home数据集上,SERL相比于现有最佳方法提升了超过2个百分点。消融实验也验证了各个模块的有效性,证明了多角度语义正则化的优势。
🎯 应用场景
该研究成果可广泛应用于图像分类、目标检测、语义分割等计算机视觉任务中,尤其是在标注数据稀缺的场景下。例如,在医学图像分析中,可以利用少量标注的病灶图像,将模型从大量标注的自然图像迁移到医学图像领域,辅助医生进行疾病诊断。此外,该方法还可应用于机器人领域,提升机器人在新环境中的适应能力。
📄 摘要(原文)
Semi-supervised domain adaptation (SSDA) has been extensively researched due to its ability to improve classification performance and generalization ability of models by using a small amount of labeled data on the target domain. However, existing methods cannot effectively adapt to the target domain due to difficulty in fully learning rich and complex target semantic information and relationships. In this paper, we propose a novel SSDA learning framework called semantic regularization learning (SERL), which captures the target semantic information from multiple perspectives of regularization learning to achieve adaptive fine-tuning of the source pre-trained model on the target domain. SERL includes three robust semantic regularization techniques. Firstly, semantic probability contrastive regularization (SPCR) helps the model learn more discriminative feature representations from a probabilistic perspective, using semantic information on the target domain to understand the similarities and differences between samples. Additionally, adaptive weights in SPCR can help the model learn the semantic distribution correctly through the probabilities of different samples. To further comprehensively understand the target semantic distribution, we introduce hard-sample mixup regularization (HMR), which uses easy samples as guidance to mine the latent target knowledge contained in hard samples, thereby learning more complete and complex target semantic knowledge. Finally, target prediction regularization (TPR) regularizes the target predictions of the model by maximizing the correlation between the current prediction and the past learned objective, thereby mitigating the misleading of semantic information caused by erroneous pseudo-labels. Extensive experiments on three benchmark datasets demonstrate that our SERL method achieves state-of-the-art performance.