Leverage Cross-Attention for End-to-End Open-Vocabulary Panoptic Reconstruction
作者: Xuan Yu, Yuxuan Xie, Yili Liu, Haojian Lu, Rong Xiong, Yiyi Liao, Yue Wang
分类: cs.CV, cs.RO
发布日期: 2025-01-02 (更新: 2025-11-23)
备注: 18 pages, 10 figures
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
PanopticRecon++:利用交叉注意力实现端到端开放词汇全景重建
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 全景重建 开放词汇 交叉注意力 3D高斯 端到端学习
📋 核心要点
- 现有全景重建方法通常分离查询和键的优化,或忽略空间邻近性,导致重建效果受限。
- PanopticRecon++提出使用可学习的3D高斯分布作为实例查询,注入3D空间先验,实现端到端优化。
- 实验表明,PanopticRecon++在3D和2D分割、重建性能上表现出色,并可应用于机器人模拟。
📝 摘要(中文)
本文提出PanopticRecon++,一种端到端的开放词汇全景重建方法,它通过新颖的交叉注意力视角来构建全景重建。该视角通过注意力图对3D实例(作为查询)和场景的3D嵌入场(作为键)之间的关系进行建模。与现有方法分离查询和键的优化或忽略空间邻近性不同,PanopticRecon++引入可学习的3D高斯分布作为实例查询,注入3D空间先验以保持邻近性,同时保持端到端的可优化性。此外,这种查询公式通过利用最优线性分配和从查询渲染的实例掩码,促进了跨帧的2D开放词汇实例ID的对齐。此外,我们通过在由全景损失监督的新型全景头中融合基于查询的实例分割概率和语义概率,来确保语义-实例分割的一致性。在训练期间,实例查询token的数量动态适应以匹配对象的数量。PanopticRecon++在模拟和真实世界数据集上展示了在3D和2D分割和重建性能方面的竞争性能,并展示了作为机器人模拟器的用例。我们的项目网站是:https://yuxuan1206.github.io/panopticrecon_pp/
🔬 方法详解
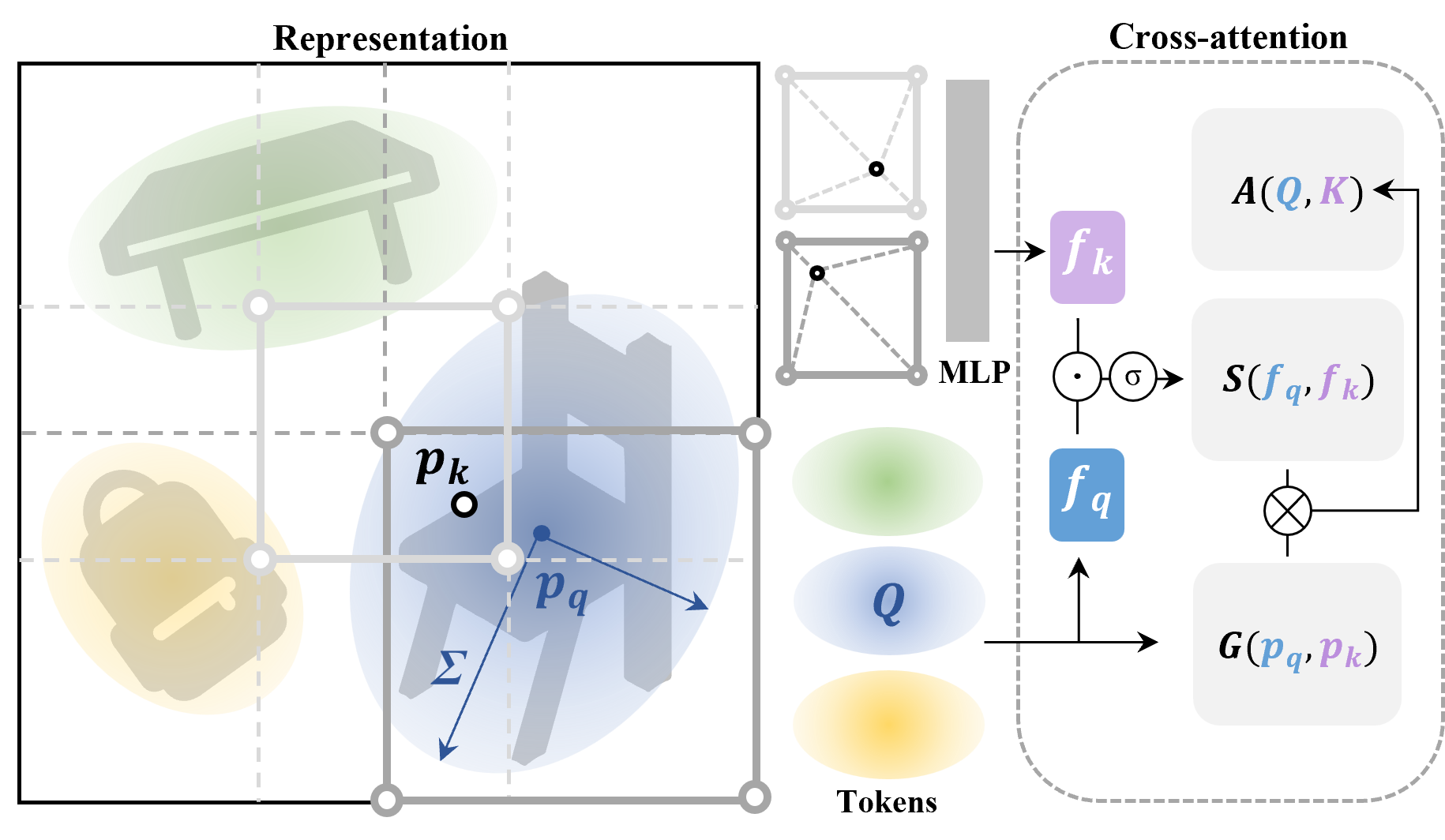
问题定义:现有开放词汇全景重建方法通常存在以下痛点:一是将查询(实例)和键(3D嵌入场)的优化过程分离,导致信息传递不充分;二是忽略了实例之间的空间邻近性,使得重建结果在空间上不连贯。这些问题限制了全景重建的精度和泛化能力。
核心思路:PanopticRecon++的核心思路是利用交叉注意力机制,将3D实例(作为查询)和场景的3D嵌入场(作为键)关联起来,并通过注意力图建模它们之间的关系。为了解决现有方法的不足,该方法引入了可学习的3D高斯分布作为实例查询,从而在优化过程中注入3D空间先验,保持实例的空间邻近性,并实现端到端的优化。
技术框架:PanopticRecon++的整体框架包含以下几个主要模块:1) 3D嵌入场:用于表示场景的几何和语义信息;2) 实例查询:使用可学习的3D高斯分布表示每个实例;3) 交叉注意力模块:计算实例查询和3D嵌入场之间的注意力图,从而建立实例之间的关系;4) 全景头:融合基于查询的实例分割概率和语义概率,生成最终的全景分割结果;5) 动态查询数量调整模块:根据场景中对象的数量动态调整实例查询token的数量。
关键创新:PanopticRecon++最重要的技术创新点在于引入了可学习的3D高斯分布作为实例查询。与现有方法中使用的固定查询或随机查询相比,3D高斯分布能够更好地表示实例的空间信息,并注入3D空间先验,从而提高重建的精度和空间一致性。此外,端到端的优化方式也使得各个模块能够协同工作,进一步提升整体性能。
关键设计:在关键设计方面,PanopticRecon++采用了以下策略:1) 使用最优线性分配算法对齐跨帧的2D开放词汇实例ID,保证了时间一致性;2) 设计了一个新型全景头,融合了基于查询的实例分割概率和语义概率,确保了语义-实例分割的一致性;3) 采用动态查询数量调整策略,根据场景中对象的数量动态调整实例查询token的数量,提高了模型的效率和泛化能力。
🖼️ 关键图片


📊 实验亮点
PanopticRecon++在模拟和真实世界数据集上都取得了具有竞争力的性能。具体来说,该方法在3D和2D分割和重建任务上都优于现有方法。此外,该论文还展示了PanopticRecon++作为机器人模拟器的用例,验证了其在实际应用中的潜力。
🎯 应用场景
PanopticRecon++在机器人导航、场景理解、虚拟现实和增强现实等领域具有广泛的应用前景。它可以为机器人提供更全面的场景理解能力,帮助机器人更好地进行导航和交互。此外,该方法还可以用于生成逼真的虚拟场景,为虚拟现实和增强现实应用提供高质量的内容。
📄 摘要(原文)
Open-vocabulary panoptic reconstruction offers comprehensive scene understanding, enabling advances in embodied robotics and photorealistic simulation. In this paper, we propose PanopticRecon++, an end-to-end method that formulates panoptic reconstruction through a novel cross-attention perspective. This perspective models the relationship between 3D instances (as queries) and the scene's 3D embedding field (as keys) through their attention map. Unlike existing methods that separate the optimization of queries and keys or overlook spatial proximity, PanopticRecon++ introduces learnable 3D Gaussians as instance queries. This formulation injects 3D spatial priors to preserve proximity while maintaining end-to-end optimizability. Moreover, this query formulation facilitates the alignment of 2D open-vocabulary instance IDs across frames by leveraging optimal linear assignment with instance masks rendered from the queries. Additionally, we ensure semantic-instance segmentation consistency by fusing query-based instance segmentation probabilities with semantic probabilities in a novel panoptic head supervised by a panoptic loss. During training, the number of instance query tokens dynamically adapts to match the number of objects. PanopticRecon++ shows competitive performance in terms of 3D and 2D segmentation and reconstruction performance on both simulation and real-world datasets, and demonstrates a user case as a robot simulator. Our project website is at: https://yuxuan1206.github.io/panopticrecon_pp/