Transferability of Adversarial Attacks in Video-based MLLMs: A Cross-modal Image-to-Video Approach
作者: Linhao Huang, Xue Jiang, Zhiqiang Wang, Wentao Mo, Xi Xiao, Yong-Jie Yin, Bo Han, Feng Zheng
分类: cs.CV, cs.CR, cs.LG
发布日期: 2025-01-02 (更新: 2026-01-09)
💡 一句话要点
提出I2V-MLLM攻击,提升视频多模态大模型对抗样本的黑盒迁移性
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频多模态大模型 对抗攻击 黑盒攻击 迁移学习 跨模态攻击
📋 核心要点
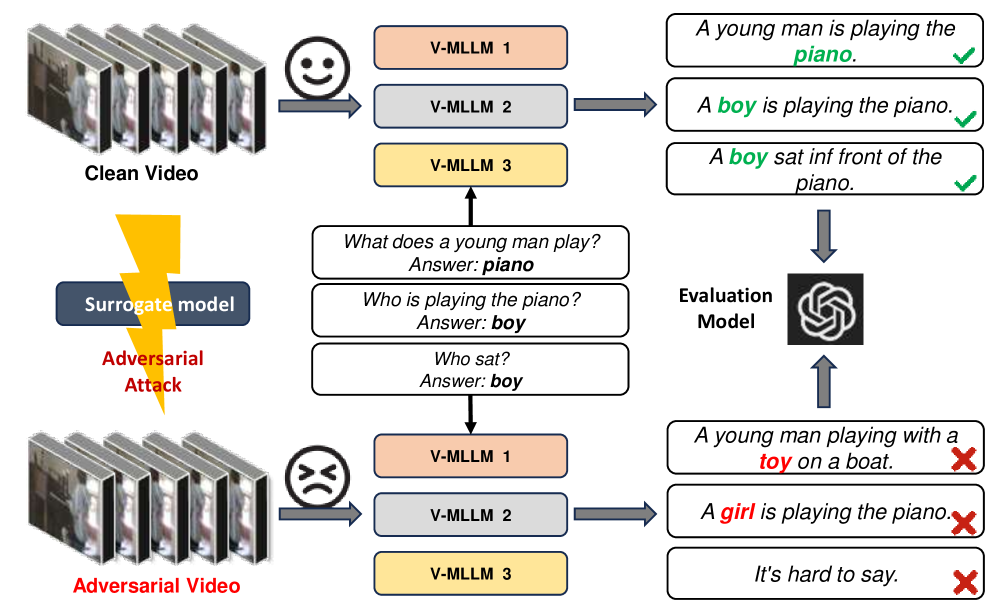
- 现有视频多模态大模型对抗攻击方法在黑盒场景下迁移性差,无法有效攻击未知的目标模型。
- 提出I2V-MLLM攻击,利用图像多模态大模型作为替代模型,结合多模态信息和时空扰动生成更具迁移性的对抗样本。
- 实验表明,I2V-MLLM在黑盒攻击下,对多个视频-文本任务和不同的V-MLLM都表现出强大的迁移性,攻击成功率接近白盒攻击。
📝 摘要(中文)
本文首次探索了视频多模态大语言模型(V-MLLMs)对抗样本的黑盒迁移性问题。研究发现,现有对抗攻击方法在V-MLLMs的黑盒攻击场景中存在泛化性不足、仅关注稀疏关键帧以及未能有效整合多模态信息等局限性。为了解决这些问题,并加深对V-MLLM在黑盒场景下脆弱性的理解,本文提出了一种Image-to-Video MLLM (I2V-MLLM)攻击方法。I2V-MLLM利用图像多模态大语言模型(I-MLLM)作为替代模型来生成对抗视频样本,通过整合多模态交互和时空信息来扰乱潜在空间中的视频表示,从而提高对抗迁移性。此外,还引入了一种扰动传播技术来处理不同的未知帧采样策略。实验结果表明,该方法生成的对抗样本在多个视频-文本多模态任务上,对不同的V-MLLM表现出很强的迁移性。与在这些模型上进行的白盒攻击相比,我们的黑盒攻击(使用BLIP-2作为替代模型)取得了具有竞争力的性能,在Zero-Shot VideoQA任务中,在MSVD-QA和MSRVTT-QA上的平均攻击成功率(AASR)分别为57.98%和58.26%。
🔬 方法详解
问题定义:现有针对视频多模态大语言模型(V-MLLMs)的对抗攻击方法,在黑盒场景下,即攻击者无法访问目标模型的内部参数和结构时,其生成的对抗样本难以迁移到其他未知的V-MLLMs上。现有方法通常存在视频特征扰动泛化性不足、仅关注少量关键帧以及忽略多模态信息融合等问题,导致攻击效果不佳。
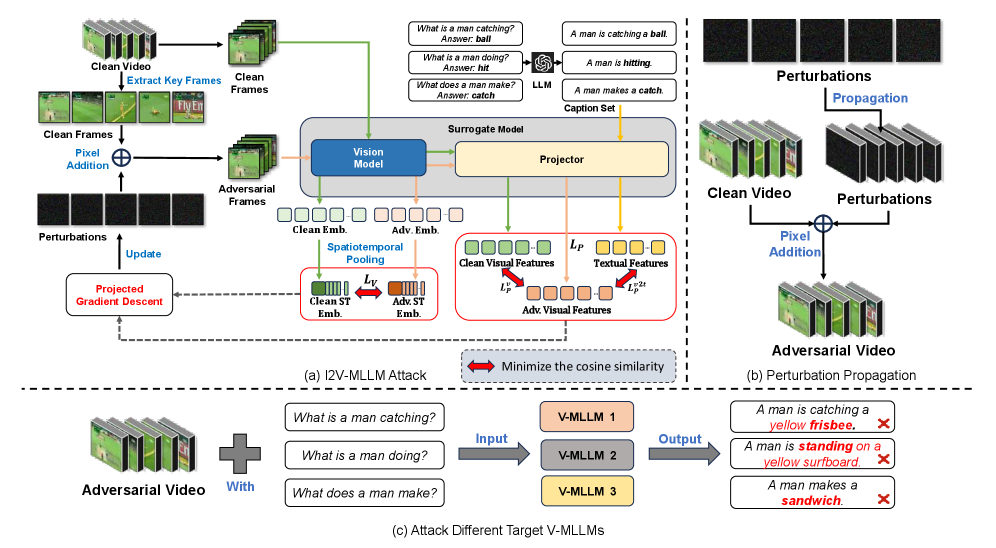
核心思路:本文的核心思路是利用图像多模态大语言模型(I-MLLM)作为替代模型,生成更具泛化性的对抗视频样本。通过在图像模态上进行对抗扰动,并将扰动信息有效地传播到视频模态,从而提高对抗样本在不同V-MLLMs之间的迁移能力。这种方法的核心在于利用I-MLLM对多模态信息的理解能力,以及图像模态相对成熟的对抗攻击技术。
技术框架:I2V-MLLM攻击框架主要包含以下几个阶段:1) 选择一个I-MLLM作为替代模型;2) 利用I-MLLM生成对抗图像;3) 将对抗图像转化为对抗视频,并进行时空扰动;4) 使用扰动传播技术,处理不同V-MLLM的帧采样策略。整体流程旨在生成能够欺骗目标V-MLLM,使其产生错误输出的对抗视频。
关键创新:本文最重要的技术创新点在于提出了跨模态的对抗样本生成方法,即利用图像模态的对抗攻击经验来提升视频模态的对抗攻击效果。通过I-MLLM作为桥梁,将图像模态的对抗扰动迁移到视频模态,从而克服了现有方法在视频对抗攻击中泛化性不足的问题。此外,扰动传播技术也是一个创新点,它能够有效应对不同V-MLLM的帧采样策略,进一步提升了对抗样本的迁移性。
关键设计:在I2V-MLLM中,关键的设计包括:1) 如何选择合适的I-MLLM作为替代模型;2) 如何将对抗图像有效地转化为对抗视频,并保持时空一致性;3) 如何设计扰动传播技术,以适应不同的帧采样策略。具体而言,可以使用现有的图像对抗攻击方法(如PGD)生成对抗图像,然后通过插值或生成模型将对抗图像扩展为对抗视频。扰动传播技术可以通过学习一个映射函数,将对抗图像的扰动信息传播到视频的每一帧。
🖼️ 关键图片
📊 实验亮点
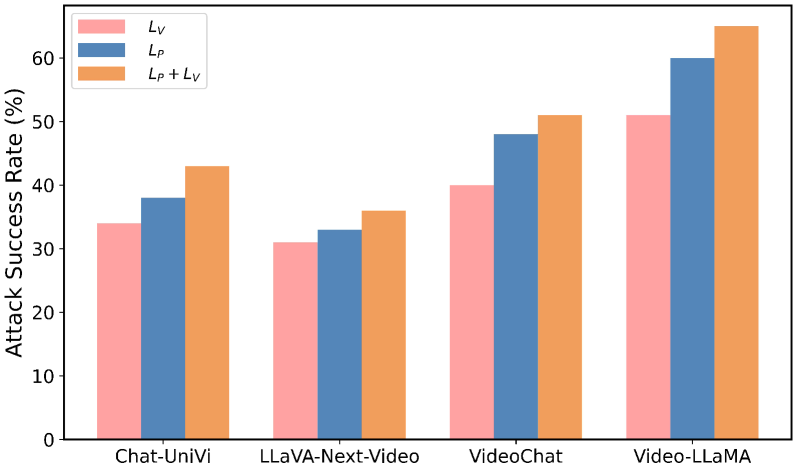
实验结果表明,I2V-MLLM攻击在MSVD-QA和MSRVTT-QA数据集上的Zero-Shot VideoQA任务中,使用BLIP-2作为替代模型时,平均攻击成功率(AASR)分别达到了57.98%和58.26%。这一结果与直接在目标模型上进行的白盒攻击相比,具有竞争力的性能,证明了I2V-MLLM攻击在黑盒场景下具有很强的迁移性。
🎯 应用场景
该研究成果可应用于评估和提升视频多模态大模型的安全性。通过分析对抗样本的生成和迁移过程,可以更好地理解V-MLLM的脆弱性,并开发更鲁棒的模型。此外,该方法还可以用于防御对抗攻击,例如通过对抗训练提高模型的鲁棒性。该研究对于推动安全可靠的多模态人工智能系统的发展具有重要意义。
📄 摘要(原文)
Video-based multimodal large language models (V-MLLMs) have shown vulnerability to adversarial examples in video-text multimodal tasks. However, the transferability of adversarial videos to unseen models - a common and practical real-world scenario - remains unexplored. In this paper, we pioneer an investigation into the transferability of adversarial video samples across V-MLLMs. We find that existing adversarial attack methods face significant limitations when applied in black-box settings for V-MLLMs, which we attribute to the following shortcomings: (1) lacking generalization in perturbing video features, (2) focusing only on sparse key-frames, and (3) failing to integrate multimodal information. To address these limitations and deepen the understanding of V-MLLM vulnerabilities in black-box scenarios, we introduce the Image-to-Video MLLM (I2V-MLLM) attack. In I2V-MLLM, we utilize an image-based multimodal large language model (I-MLLM) as a surrogate model to craft adversarial video samples. Multimodal interactions and spatiotemporal information are integrated to disrupt video representations within the latent space, improving adversarial transferability. Additionally, a perturbation propagation technique is introduced to handle different unknown frame sampling strategies. Experimental results demonstrate that our method can generate adversarial examples that exhibit strong transferability across different V-MLLMs on multiple video-text multimodal tasks. Compared to white-box attacks on these models, our black-box attacks (using BLIP-2 as a surrogate model) achieve competitive performance, with average attack success rate (AASR) of 57.98% on MSVD-QA and 58.26% on MSRVTT-QA for Zero-Shot VideoQA tasks, respectively.