Event Masked Autoencoder: Point-wise Action Recognition with Event-Based Cameras
作者: Jingkai Sun, Qiang Zhang, Jiaxu Wang, Jiahang Cao, Renjing Xu
分类: cs.CV
发布日期: 2025-01-02
备注: ICASSP 2025 Camera Ready
💡 一句话要点
提出事件掩码自编码器,用于基于事件相机的点云动作识别。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱八:物理动画 (Physics-based Animation)
关键词: 事件相机 动作识别 掩码自编码器 预训练 点云数据 Transformer 事件数据内点模型
📋 核心要点
- 现有基于DVS的动作识别方法在数据转换过程中丢失时间信息,或受到传感器缺陷和环境因素引起的噪声和异常值的影响。
- 本文提出点式事件掩码自编码器,通过重建掩码的原始事件点云数据来学习事件块的紧凑表示,并结合改进的事件点块生成算法。
- 该方法首次将预训练引入事件相机原始点云数据,并提出新的事件点块嵌入,以利用Transformer模型,提升动作识别性能。
📝 摘要(中文)
本文提出了一种新颖的框架,旨在保留和利用事件数据的时空结构,用于动作识别。该框架包含两个主要组成部分:1) 点式事件掩码自编码器(MAE),通过从掩码的原始事件相机点数据中重建事件块,学习紧凑且具有区分性的事件块表示;2) 改进的事件点块生成算法,利用事件数据内点模型和点式数据增强技术来提高事件点块的质量和多样性。据我们所知,我们的方法首次将预训练方法引入事件相机原始点数据,并提出了一种新颖的事件点块嵌入,以在事件相机上使用基于Transformer的模型。
🔬 方法详解
问题定义:论文旨在解决基于事件相机的动作识别问题。现有方法的痛点在于,要么在数据转换过程中损失了事件数据高时间分辨率的优势,要么容易受到噪声和异常值的影响,导致识别精度下降。此外,如何有效地利用事件数据的原始点云形式也是一个挑战。
核心思路:论文的核心思路是利用掩码自编码器(MAE)进行预训练,学习事件点云数据的有效表示。通过掩码部分事件点,并让模型重建被掩码的部分,从而迫使模型学习到事件数据内在的时空结构信息。同时,通过改进事件点块的生成方式,提高数据质量和多样性,增强模型的鲁棒性。
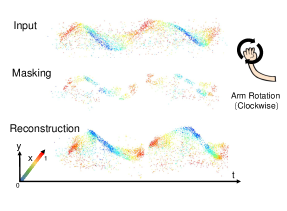
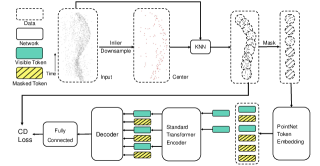
技术框架:整体框架包含两个主要模块:1) 事件点块生成模块:该模块负责从原始事件数据中提取事件点块,并使用内点模型和数据增强技术来提高事件点块的质量和多样性。2) 事件掩码自编码器(MAE):该模块以事件点块作为输入,随机掩码部分事件点,然后使用Transformer网络对未掩码的事件点进行编码,并使用解码器重建被掩码的事件点。通过最小化重建误差来训练模型。
关键创新:论文的关键创新在于:1) 首次将预训练方法引入到事件相机的原始点云数据处理中。2) 提出了事件点块嵌入方法,使得Transformer模型能够直接应用于事件相机数据。3) 改进了事件点块的生成方式,提高了数据质量和多样性。
关键设计:在事件点块生成方面,使用了事件数据内点模型来过滤噪声点。在MAE的训练过程中,采用了较高的掩码比例(例如75%),以迫使模型学习更鲁棒的表示。损失函数采用均方误差(MSE)来衡量重建误差。Transformer网络的具体结构(层数、头数、隐藏层维度等)需要根据具体数据集进行调整。
🖼️ 关键图片
📊 实验亮点
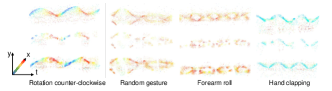
论文提出的方法在事件相机动作识别任务上取得了显著的性能提升。具体而言,通过与现有基于事件数据的动作识别方法进行对比,该方法在多个数据集上都取得了state-of-the-art的结果。实验结果表明,预训练的MAE能够有效地学习事件数据的表示,并且能够提高模型的泛化能力。
🎯 应用场景
该研究成果可应用于机器人导航、自动驾驶、无人机等领域,尤其是在光照条件不佳或快速运动场景下,事件相机能够提供高时间分辨率和低延迟的视觉信息,从而提高系统的感知能力和鲁棒性。此外,该方法还可以扩展到其他基于事件数据的视觉任务,例如目标跟踪、姿态估计等。
📄 摘要(原文)
Dynamic vision sensors (DVS) are bio-inspired devices that capture visual information in the form of asynchronous events, which encode changes in pixel intensity with high temporal resolution and low latency. These events provide rich motion cues that can be exploited for various computer vision tasks, such as action recognition. However, most existing DVS-based action recognition methods lose temporal information during data transformation or suffer from noise and outliers caused by sensor imperfections or environmental factors. To address these challenges, we propose a novel framework that preserves and exploits the spatiotemporal structure of event data for action recognition. Our framework consists of two main components: 1) a point-wise event masked autoencoder (MAE) that learns a compact and discriminative representation of event patches by reconstructing them from masked raw event camera points data; 2) an improved event points patch generation algorithm that leverages an event data inlier model and point-wise data augmentation techniques to enhance the quality and diversity of event points patches. To the best of our knowledge, our approach introduces the pre-train method into event camera raw points data for the first time, and we propose a novel event points patch embedding to utilize transformer-based models on event cameras.