A Novel Convolution and Attention Mechanism-based Model for 6D Object Pose Estimation
作者: Alexander Du, Xiujin Liu
分类: cs.CV, cs.LG
发布日期: 2024-12-31 (更新: 2026-01-07)
备注: 6 pages, 2 figures, 3 tables
💡 一句话要点
PoseLecTr:结合Legendre卷积与注意力机制的6D物体姿态估计方法
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱七:动作重定向 (Motion Retargeting)
关键词: 6D姿态估计 图卷积网络 Legendre卷积 注意力机制 单目视觉 物体识别 机器人抓取
📋 核心要点
- 传统方法在复杂场景下建模图像特征间高阶和长程依赖关系的能力有限,影响了姿态估计的准确性。
- PoseLecTr通过构建图表示显式建模空间关系,并结合Legendre卷积和注意力机制增强特征选择。
- 实验结果表明,PoseLecTr在多个数据集上表现出竞争力的性能,并在不同复杂度的场景中均有提升。
📝 摘要(中文)
本文提出了一种名为PoseLecTr的基于图的编码器-解码器框架,该框架集成了新型Legendre卷积和注意力机制,用于从单目RGB图像中进行六自由度(6-DOF)物体姿态估计。传统的基于学习的方法主要依赖于网格结构的卷积,这限制了它们对图像特征之间的高阶和长程依赖关系进行建模的能力,尤其是在杂乱或遮挡的场景中。PoseLecTr通过从图像特征构建图表示来解决这一限制,其中空间关系通过图连接显式建模。所提出的框架包含一个Legendre卷积层,以提高图卷积中的数值稳定性,以及空间注意力和自注意力蒸馏,以增强特征选择。在LINEMOD、Occluded LINEMOD和YCB-VIDEO数据集上进行的实验表明,我们的方法实现了有竞争力的性能,并在各种物体和场景复杂性中显示出持续的改进。
🔬 方法详解
问题定义:论文旨在解决单目RGB图像的6D物体姿态估计问题。现有方法,特别是基于网格卷积的方法,在处理遮挡、杂乱等复杂场景时,难以有效建模图像特征之间的高阶和长程依赖关系,导致姿态估计精度下降。
核心思路:论文的核心思路是将图像特征表示为图结构,利用图卷积神经网络(GCN)来显式地建模特征之间的空间关系。通过引入Legendre卷积,提升图卷积的数值稳定性。同时,结合空间注意力和自注意力蒸馏机制,增强特征选择能力,从而提高姿态估计的准确性。
技术框架:PoseLecTr采用编码器-解码器框架。编码器部分将RGB图像转换为图表示,其中节点表示图像特征,边表示特征之间的空间关系。编码器包含Legendre卷积层、空间注意力模块和自注意力蒸馏模块。解码器部分利用编码器的输出进行姿态估计。整体流程为:输入RGB图像 -> 特征提取 -> 图构建 -> Legendre卷积 + 注意力机制 -> 姿态估计。
关键创新:论文的关键创新在于以下几点:1) 引入Legendre卷积,提升图卷积的数值稳定性,使其能够处理更复杂的图结构;2) 结合空间注意力和自注意力蒸馏,增强特征选择能力,抑制噪声特征的干扰;3) 将图像特征表示为图结构,显式地建模特征之间的空间关系,克服了传统网格卷积的局限性。与现有方法的本质区别在于,PoseLecTr不再局限于网格结构,而是利用图结构来表示和处理图像特征。
关键设计:Legendre卷积的具体实现方式未知,需要查阅论文细节。空间注意力模块和自注意力蒸馏模块的具体结构也未知,需要查阅论文细节。损失函数的设计目标是最小化预测姿态与真实姿态之间的差异,具体形式未知,需要查阅论文细节。图的构建方式,例如节点和边的选择标准,也需要查阅论文细节。
🖼️ 关键图片

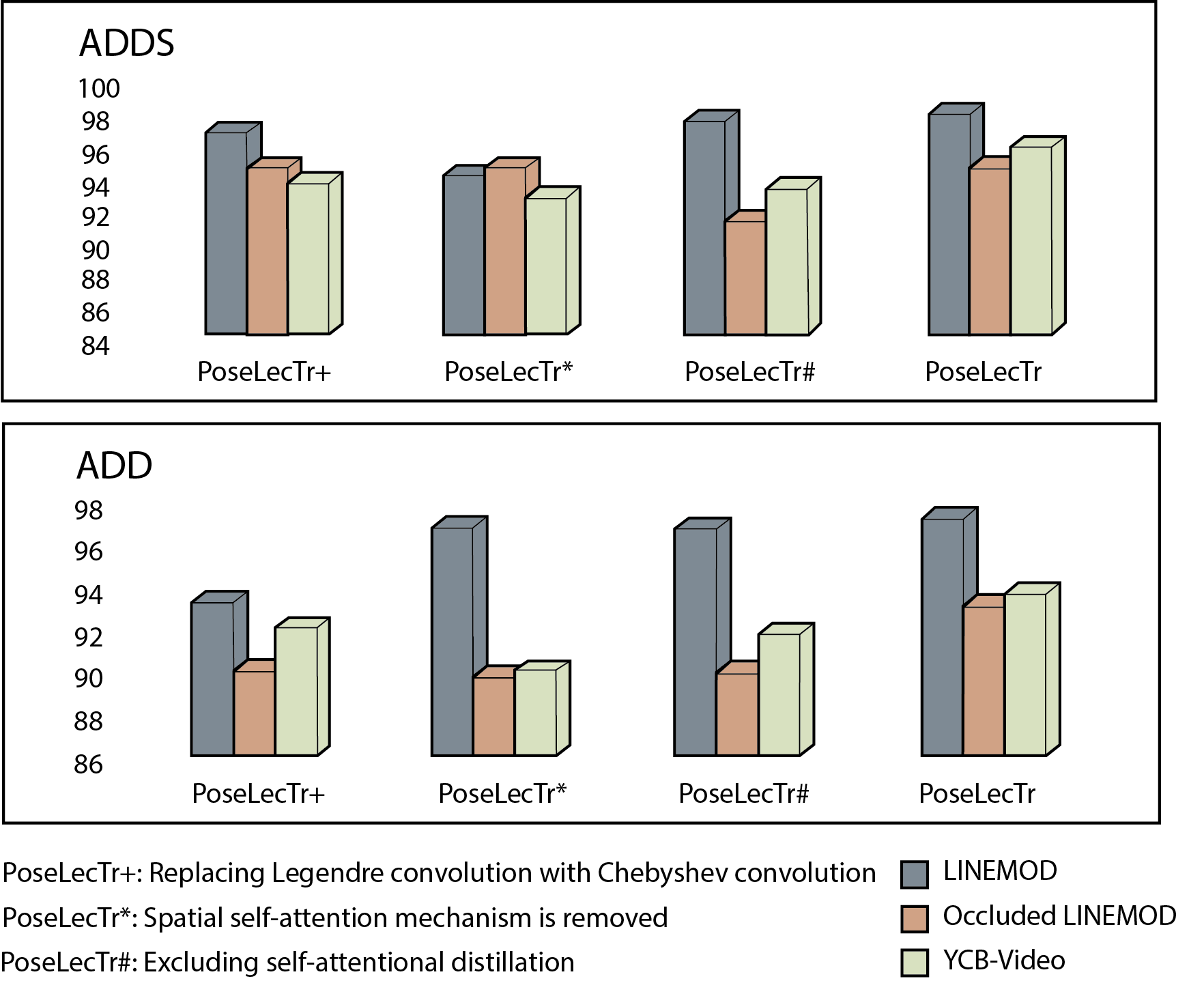
📊 实验亮点
实验结果表明,PoseLecTr在LINEMOD、Occluded LINEMOD和YCB-VIDEO数据集上取得了有竞争力的性能。具体提升幅度未知,需要查阅论文原文。该方法在处理遮挡和杂乱场景时表现出更强的鲁棒性,证明了其有效性。
🎯 应用场景
该研究成果可应用于机器人抓取、增强现实、自动驾驶等领域。在机器人抓取中,可以帮助机器人准确识别和定位目标物体,从而实现精确抓取。在增强现实中,可以实现虚拟物体与真实场景的自然融合。在自动驾驶中,可以提高车辆对周围环境的感知能力,从而提升驾驶安全性。
📄 摘要(原文)
This paper proposes PoseLecTr, a graph-based encoder-decoder framework that integrates a novel Legendre convolution with attention mechanisms for six-degree-of-freedom (6-DOF) object pose estimation from monocular RGB images. Conventional learning-based approaches predominantly rely on grid-structured convolutions, which can limit their ability to model higher-order and long-range dependencies among image features, especially in cluttered or occluded scenes. PoseLecTr addresses this limitation by constructing a graph representation from image features, where spatial relationships are explicitly modeled through graph connectivity. The proposed framework incorporates a Legendre convolution layer to improve numerical stability in graph convolution, together with spatial-attention and self-attention distillation to enhance feature selection. Experiments conducted on the LINEMOD, Occluded LINEMOD, and YCB-VIDEO datasets demonstrate that our method achieves competitive performance and shows consistent improvements across a wide range of objects and scene complexities.