VideoRefer Suite: Advancing Spatial-Temporal Object Understanding with Video LLM
作者: Yuqian Yuan, Hang Zhang, Wentong Li, Zesen Cheng, Boqiang Zhang, Long Li, Xin Li, Deli Zhao, Wenqiao Zhang, Yueting Zhuang, Jianke Zhu, Lidong Bing
分类: cs.CV, cs.AI, cs.LG
发布日期: 2024-12-31 (更新: 2025-03-25)
备注: 17 pages, 14 figures, technical report
💡 一句话要点
提出VideoRefer Suite,增强Video LLM在时空对象理解方面的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频大语言模型 时空对象理解 视频引用 多模态学习 视频指令数据集
📋 核心要点
- 现有Video LLM在捕捉细粒度的时空细节方面存在不足,限制了其对象级别的理解能力。
- 论文提出VideoRefer Suite,包含数据集、模型和基准,旨在提升Video LLM对视频中对象的感知和推理能力。
- 实验结果表明,VideoRefer模型在视频引用基准上表现出色,并能促进通用视频理解能力的提升。
📝 摘要(中文)
视频大语言模型(Video LLM)最近在通用视频理解方面表现出卓越的能力。然而,它们主要侧重于整体理解,难以捕捉细粒度的时空细节。此外,缺乏高质量的对象级视频指令数据和一个全面的基准进一步阻碍了它们的发展。为了应对这些挑战,我们引入了VideoRefer Suite,以增强Video LLM在更精细的时空视频理解方面的能力,即实现对视频中任何对象的感知和推理。具体而言,我们从数据集、模型和基准三个关键方面全面开发了VideoRefer Suite。首先,我们引入了一个多智能体数据引擎,精心策划了一个大规模、高质量的对象级视频指令数据集,称为VideoRefer-700K。接下来,我们提出了VideoRefer模型,该模型配备了一个通用的时空对象编码器,以捕获精确的区域和序列表示。最后,我们精心创建了一个VideoRefer-Bench,以全面评估Video LLM的时空理解能力,从各个方面对其进行评估。大量的实验和分析表明,我们的VideoRefer模型不仅在视频引用基准上取得了有希望的性能,而且还有助于提高通用视频理解能力。
🔬 方法详解
问题定义:现有Video LLM虽然在通用视频理解上取得了进展,但难以精确捕捉视频中特定对象的时空信息,缺乏对细粒度对象级别理解的能力。同时,高质量的对象级视频指令数据和全面的评估基准的缺失,也阻碍了相关研究的深入发展。
核心思路:论文的核心思路是通过构建一个包含数据集、模型和基准的完整体系VideoRefer Suite,来提升Video LLM对视频中对象的时空理解能力。具体而言,通过大规模高质量的数据集训练模型,并使用全面的基准进行评估,从而促进模型在对象级别理解方面的提升。
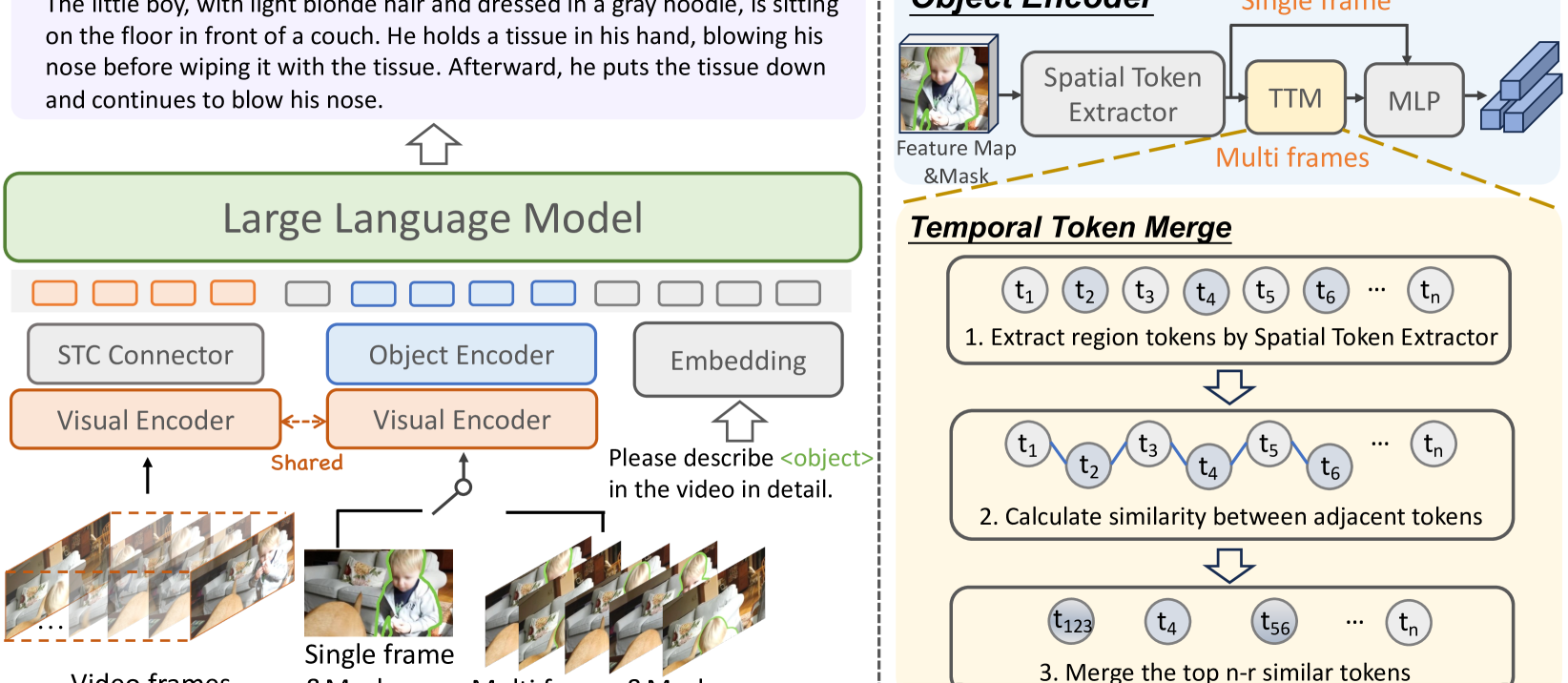
技术框架:VideoRefer Suite包含三个主要组成部分:1) VideoRefer-700K数据集:一个大规模、高质量的对象级视频指令数据集,用于训练模型。2) VideoRefer模型:一个配备通用时空对象编码器的Video LLM,用于捕获精确的区域和序列表示。3) VideoRefer-Bench:一个全面的基准,用于评估Video LLM的时空理解能力。整体流程是使用VideoRefer-700K训练VideoRefer模型,然后使用VideoRefer-Bench评估其性能。
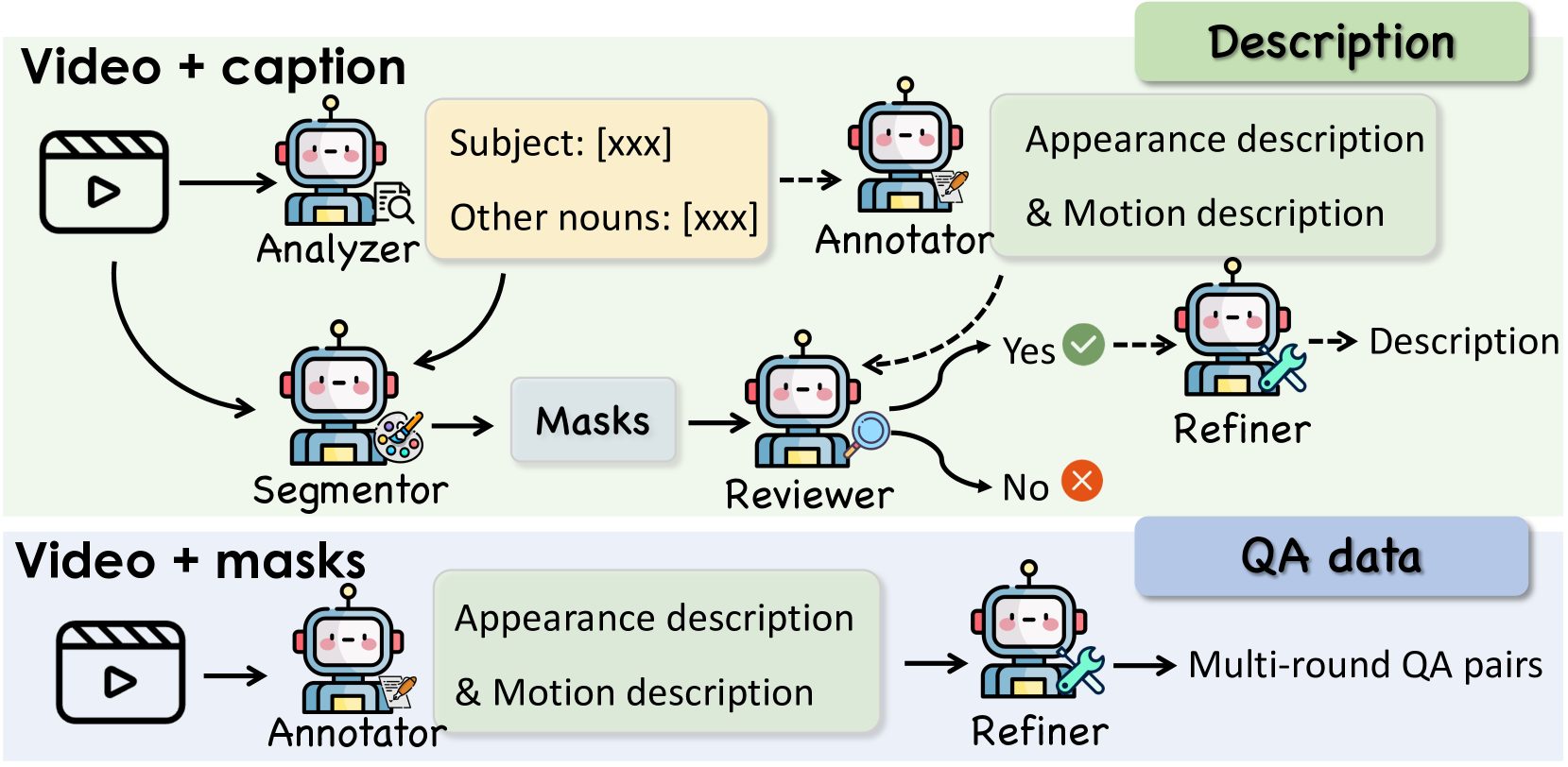
关键创新:论文的关键创新在于构建了一个完整的VideoRefer Suite,从数据、模型和基准三个方面全面提升Video LLM的时空对象理解能力。特别是,多智能体数据引擎的引入,能够高效地生成大规模、高质量的对象级视频指令数据,这对于训练高性能的Video LLM至关重要。
关键设计:VideoRefer模型的核心在于其通用的时空对象编码器,该编码器能够有效地提取视频中对象的区域和序列特征。具体的技术细节包括:编码器的具体网络结构(例如,Transformer或其他时序模型),损失函数的设计(例如,对比学习损失或交叉熵损失),以及训练策略(例如,预训练和微调)。数据集VideoRefer-700K包含多种类型的指令,例如,定位、跟踪和描述视频中的对象。
🖼️ 关键图片

📊 实验亮点
实验结果表明,VideoRefer模型在视频引用基准上取得了显著的性能提升,证明了其在时空对象理解方面的有效性。此外,该模型还展现出良好的通用视频理解能力,表明VideoRefer Suite不仅可以提升特定任务的性能,还能促进Video LLM的整体发展。具体的性能数据和对比基线在论文中有详细展示。
🎯 应用场景
该研究成果可应用于智能监控、自动驾驶、视频编辑、人机交互等领域。例如,在智能监控中,可以利用该技术实现对特定目标的精准跟踪和行为分析;在自动驾驶中,可以帮助车辆更好地理解周围环境,提高行驶安全性。未来,该技术有望进一步提升视频理解的智能化水平,为人们的生活带来更多便利。
📄 摘要(原文)
Video Large Language Models (Video LLMs) have recently exhibited remarkable capabilities in general video understanding. However, they mainly focus on holistic comprehension and struggle with capturing fine-grained spatial and temporal details. Besides, the lack of high-quality object-level video instruction data and a comprehensive benchmark further hinders their advancements. To tackle these challenges, we introduce the VideoRefer Suite to empower Video LLM for finer-level spatial-temporal video understanding, i.e., enabling perception and reasoning on any objects throughout the video. Specially, we thoroughly develop VideoRefer Suite across three essential aspects: dataset, model, and benchmark. Firstly, we introduce a multi-agent data engine to meticulously curate a large-scale, high-quality object-level video instruction dataset, termed VideoRefer-700K. Next, we present the VideoRefer model, which equips a versatile spatial-temporal object encoder to capture precise regional and sequential representations. Finally, we meticulously create a VideoRefer-Bench to comprehensively assess the spatial-temporal understanding capability of a Video LLM, evaluating it across various aspects. Extensive experiments and analyses demonstrate that our VideoRefer model not only achieves promising performance on video referring benchmarks but also facilitates general video understanding capabilities.