VideoChat-Flash: Hierarchical Compression for Long-Context Video Modeling
作者: Xinhao Li, Yi Wang, Jiashuo Yu, Xiangyu Zeng, Yuhan Zhu, Haian Huang, Jianfei Gao, Kunchang Li, Yinan He, Chenting Wang, Yu Qiao, Yali Wang, Limin Wang
分类: cs.CV, cs.LG
发布日期: 2024-12-31 (更新: 2025-07-13)
💡 一句话要点
VideoChat-Flash:通过分层压缩实现长上下文视频建模,显著降低计算成本。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长视频理解 分层压缩 多模态学习 大型语言模型 视频问答
📋 核心要点
- 现有MLLM处理长视频时,难以高效理解极长的视频上下文,导致计算成本高昂。
- 论文提出分层视频token压缩(HiCo)方法,通过压缩视频token,降低计算量,同时保留关键细节。
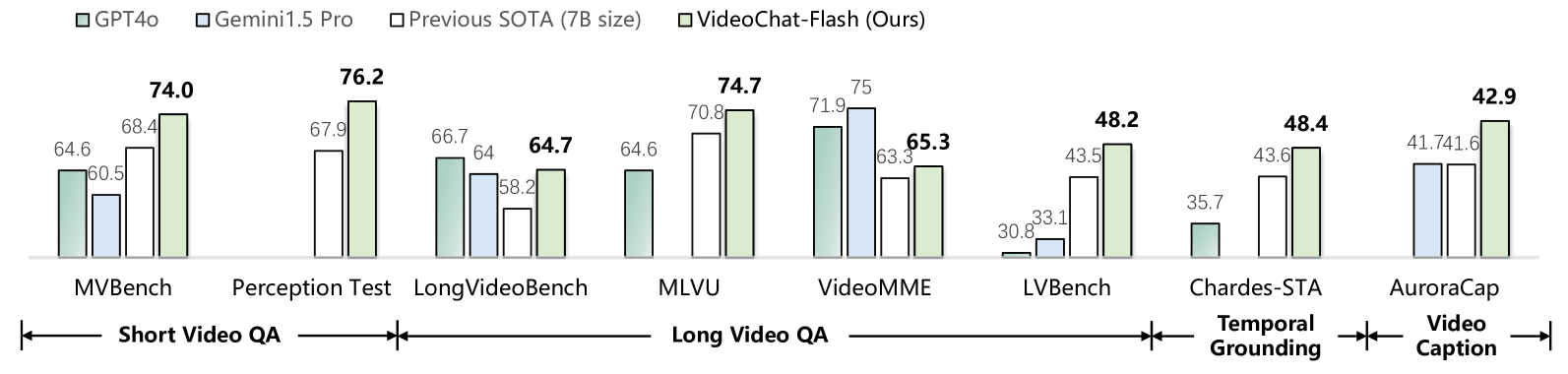
- VideoChat-Flash在长短视频基准测试中表现领先,并在NIAH基准测试中取得了优异的准确率。
📝 摘要(中文)
本文旨在解决多模态大型语言模型(MLLM)处理长视频时面临的效率挑战。为此,论文从模型架构、训练数据、训练策略和评估基准四个方面入手。首先,提出了一种新颖的分层视频token压缩(HiCo)方法,该方法利用长视频中的视觉冗余,将长视频上下文从Clip级别压缩到Video级别,在几乎不损失性能的情况下,显著降低计算量,实现了约1/50的极高压缩率。其次,引入了多阶段短到长学习方案、一个名为LongVid的大规模真实长视频数据集,以及一个具有挑战性的“视频干草堆中的多跳寻针”基准。最后,构建了一个强大的视频MLLM——VideoChat-Flash,在2B和7B模型规模下,在主流长短视频基准测试中均表现出领先的性能。在开源模型中,它首次在NIAH的10,000帧上获得了99.1%的准确率。
🔬 方法详解
问题定义:现有方法在处理长视频时,由于视频帧数量巨大,导致计算复杂度呈指数级增长,难以高效地提取和利用长视频中的信息。这限制了MLLM在处理电影、在线视频流等长视频场景中的应用。现有方法通常无法在计算效率和性能之间取得良好的平衡。
核心思路:论文的核心思路是利用长视频中存在的视觉冗余信息,通过分层压缩视频token,减少需要处理的token数量,从而降低计算成本。这种分层压缩旨在保留关键信息,同时去除冗余信息,以在性能损失最小化的前提下实现高效计算。
技术框架:VideoChat-Flash的整体框架包含以下几个主要阶段:1) 视频编码:使用预训练的视觉模型(如CLIP)将视频帧编码为clip-level的视觉token。2) 分层压缩(HiCo):将clip-level的token进一步压缩为video-level的token,显著减少token数量。3) 多模态融合:将压缩后的视频token与文本信息进行融合。4) 语言模型:使用大型语言模型(LLM)处理融合后的信息,生成文本回复。
关键创新:HiCo是该论文最重要的技术创新点。与传统的视频token处理方法不同,HiCo采用分层压缩策略,首先将视频帧编码为clip-level的token,然后利用视频内的冗余信息,将多个clip-level的token压缩为一个video-level的token。这种分层压缩方式能够更有效地减少token数量,同时保留视频的关键信息。
关键设计:HiCo的关键设计包括:1) Clip-level编码器的选择:使用预训练的CLIP模型提取视觉特征。2) Video-level压缩策略:使用自注意力机制学习clip之间的关系,并将多个clip压缩为一个video-level token。3) 损失函数设计:采用对比学习损失和语言模型损失,以保证压缩后的视频token能够保留关键信息,并与文本信息对齐。4) 多阶段训练策略:采用短到长的训练策略,逐步增加视频长度,以提高模型处理长视频的能力。
🖼️ 关键图片


📊 实验亮点
VideoChat-Flash在多个长短视频基准测试中取得了领先的性能。特别是在NIAH基准测试中,VideoChat-Flash在10,000帧的视频上获得了99.1%的准确率,显著优于其他开源模型。HiCo方法实现了约1/50的极高压缩率,同时几乎没有性能损失,证明了其在降低计算成本方面的有效性。
🎯 应用场景
该研究成果可广泛应用于视频理解、视频问答、视频摘要、视频编辑等领域。例如,可以用于构建智能视频客服系统,自动生成电影剧情摘要,或者辅助视频创作者进行内容创作。通过降低长视频处理的计算成本,该研究有望推动MLLM在更多实际场景中的应用。
📄 摘要(原文)
Long-context video modeling is critical for multimodal large language models (MLLMs), enabling them to process movies, online video streams, and so on. Despite its advances, handling long videos remains challenging due to the difficulty in efficiently understanding the extremely long video context. This paper aims to address this issue from aspects of model architecture, training data, training strategy and evaluation benchmark. First, we propose a novel Hierarchical video token Compression (HiCo) method, which leverages visual redundancy in long videos to compress long video context from Clip-level to Video-level, reducing the computation significantly while preserving essential details, achieving an extreme compression ratio of approximately 1/50 with almost no performance loss. Second, we introduce a multi-stage short-to-long learning scheme, a large-scale dataset of real-world long videos named LongVid, and a challenging ``Multi-Hop Needle-In-A-Video-Haystack'' benchmark. Finally, we build a powerful video MLLM named VideoChat-Flash, which shows a leading performance on both mainstream long and short video benchmarks at the 2B and 7B model scale. It first gets 99.1% accuracy over 10,000 frames in NIAH among open-source models.