OV-HHIR: Open Vocabulary Human Interaction Recognition Using Cross-modal Integration of Large Language Models
作者: Lala Shakti Swarup Ray, Bo Zhou, Sungho Suh, Paul Lukowicz
分类: cs.CV, cs.LG
发布日期: 2024-12-31
备注: Accepted in IEEE ICASSP 2025
💡 一句话要点
提出OV-HHIR框架,利用大语言模型实现开放词汇的人际互动识别,适用于公共安全监控。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人际互动识别 开放词汇 大语言模型 跨模态融合 视频理解 公共安全 行为分析
📋 核心要点
- 传统活动识别系统受限于固定词汇表和预定义标签,难以适应真实世界中多样且不可预测的互动。
- OV-HHIR框架利用大型语言模型生成开放式文本描述,从而识别开放世界中已见和未见的人际互动。
- 实验结果表明,该方法优于传统固定词汇分类系统和现有跨模态语言模型,提升了视觉理解能力。
📝 摘要(中文)
本文提出了一种开放词汇人际互动识别(OV-HHIR)框架,该框架利用大型语言模型生成开放式的文本描述,用于识别开放世界环境中已见和未见的人际互动,不受固定词汇表的限制。此外,本文还通过标准化和整合现有的公共人际互动数据集,创建了一个全面的、大规模的人际互动数据集,作为统一的基准。大量的实验表明,该方法优于传统的固定词汇分类系统和现有的用于视频理解的跨模态语言模型,为监控及其他领域的更智能、更适应性强的视觉理解系统奠定了基础。
🔬 方法详解
问题定义:现有的人际互动识别系统依赖于固定的词汇表和预定义的标签,无法有效地处理真实世界中复杂多变的互动场景。这些系统通常需要精心编排的视频,并且忽略了并发的互动群体,导致其在实际应用中缺乏适应性和泛化能力。因此,需要一种能够识别开放词汇、处理复杂场景的人际互动识别方法。
核心思路:本文的核心思路是利用大型语言模型(LLM)的强大文本生成能力,将人际互动场景转化为开放式的文本描述。通过这种方式,模型不再受限于预定义的类别标签,而是可以根据场景的实际内容生成更具描述性和灵活性的识别结果。这种方法能够更好地适应真实世界中多样化和不可预测的互动模式。
技术框架:OV-HHIR框架主要包含以下几个关键模块:1) 视频特征提取模块,用于提取视频中的视觉特征;2) 文本特征提取模块,用于提取与人际互动相关的文本信息(例如,场景描述、参与者信息等);3) 跨模态融合模块,将视觉特征和文本特征进行融合,以获得更全面的场景表示;4) 大语言模型生成模块,利用融合后的特征作为输入,生成对人际互动的开放式文本描述。
关键创新:该方法最重要的创新点在于利用大语言模型进行开放词汇的人际互动识别。与传统的基于固定词汇表的分类方法不同,该方法能够生成更具描述性和灵活性的识别结果,从而更好地适应真实世界中复杂多变的互动场景。此外,该方法还通过跨模态融合,充分利用了视频和文本信息,提高了识别的准确性和鲁棒性。
关键设计:具体的模型结构和参数设置未知,但可以推测可能使用了预训练的大型语言模型,例如BERT、GPT等,并针对人际互动识别任务进行了微调。损失函数可能包括文本生成损失和跨模态对齐损失,以保证生成的文本描述的准确性和与视觉信息的对应性。网络结构可能采用了Transformer架构,以实现有效的跨模态融合和文本生成。
🖼️ 关键图片


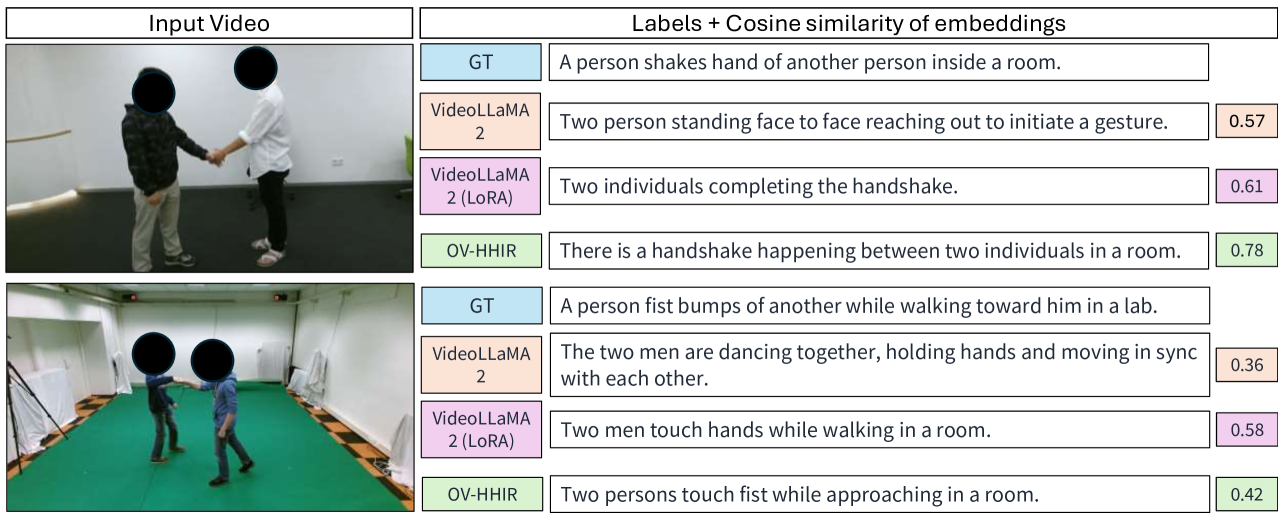
📊 实验亮点
实验结果表明,OV-HHIR框架在开放词汇人际互动识别任务上取得了显著的性能提升。该方法优于传统的固定词汇分类系统和现有的跨模态语言模型,证明了其在处理复杂、多变的互动场景方面的优势。具体的性能数据和提升幅度在论文中进行了详细的展示。
🎯 应用场景
该研究成果可广泛应用于公共安全监控、智能安防、人机交互等领域。例如,在公共场所,该系统可以自动识别潜在的危险行为或异常事件,并及时发出警报。在人机交互领域,该系统可以帮助机器人更好地理解人类的意图和行为,从而实现更自然、更智能的交互。未来,该技术有望在智慧城市、智能家居等领域发挥更大的作用。
📄 摘要(原文)
Understanding human-to-human interactions, especially in contexts like public security surveillance, is critical for monitoring and maintaining safety. Traditional activity recognition systems are limited by fixed vocabularies, predefined labels, and rigid interaction categories that often rely on choreographed videos and overlook concurrent interactive groups. These limitations make such systems less adaptable to real-world scenarios, where interactions are diverse and unpredictable. In this paper, we propose an open vocabulary human-to-human interaction recognition (OV-HHIR) framework that leverages large language models to generate open-ended textual descriptions of both seen and unseen human interactions in open-world settings without being confined to a fixed vocabulary. Additionally, we create a comprehensive, large-scale human-to-human interaction dataset by standardizing and combining existing public human interaction datasets into a unified benchmark. Extensive experiments demonstrate that our method outperforms traditional fixed-vocabulary classification systems and existing cross-modal language models for video understanding, setting the stage for more intelligent and adaptable visual understanding systems in surveillance and beyond.