Social-LLaVA: Enhancing Robot Navigation through Human-Language Reasoning in Social Spaces
作者: Amirreza Payandeh, Daeun Song, Mohammad Nazeri, Jing Liang, Praneel Mukherjee, Amir Hossain Raj, Yangzhe Kong, Dinesh Manocha, Xuesu Xiao
分类: cs.CV, cs.HC, cs.RO
发布日期: 2024-12-30
💡 一句话要点
Social-LLaVA:通过人类语言推理增强社交空间中机器人导航能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 社交机器人导航 视觉-语言模型 类人推理 SNEI数据集 人机交互
📋 核心要点
- 现有社交机器人导航方法依赖人工规则或演示,难以有效将感知转化为符合社会规范的动作。
- 论文提出利用语言作为桥梁,通过视觉-语言模型实现类人推理,从而指导机器人做出符合社会规范的动作。
- 构建了包含4万个VQA的数据集SNEI,并微调了Social-LLaVA模型,实验表明其性能优于GPT-4V和Gemini。
📝 摘要(中文)
现有的社交机器人导航技术大多依赖于手工规则或人类演示,将机器人感知与符合社会规范的动作联系起来。然而,在有效地将感知转化为符合社会规范的动作方面仍然存在显著差距,这与人类在动态环境中自然发生的推理方式不同。考虑到视觉-语言模型(VLM)的最新成功,我们提出使用语言来弥合感知和具有社会意识的机器人动作之间类人推理的差距。我们创建了一个视觉-语言数据集,即通过可解释交互的社交机器人导航(SNEI),其中包含4万个人工标注的视觉问答(VQA),这些问答基于在非结构化、拥挤的公共空间中进行的2千次人机社交互动,涵盖感知、预测、思维链推理、动作和解释。我们使用SNEI对VLM,Social-LLaVA进行微调,以展示我们数据集的实际应用。基于50个VQA上15个不同人类评委的平均得分,Social-LLaVA优于GPT-4V和Gemini等最先进的模型。Social-LLaVA部署在移动机器人上,实现了类人推理,标志着通过语言推理在动态公共空间中实现符合社会规范的机器人导航迈出了有希望的一步。
🔬 方法详解
问题定义:现有社交机器人导航方法主要依赖于手工设计的规则或人类的演示数据,缺乏像人类一样在复杂社交环境中进行推理的能力。这导致机器人难以理解和适应动态变化的社交场景,例如人群中的行走、避让行人等,从而影响了导航的效率和安全性。
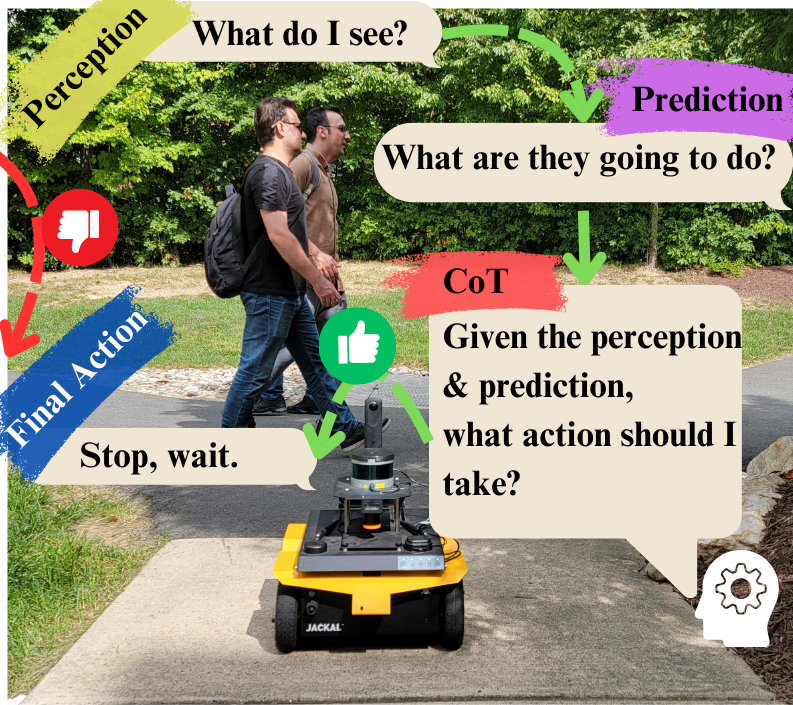
核心思路:论文的核心思路是利用大型视觉-语言模型(VLM)的强大推理能力,将机器人感知到的视觉信息与自然语言指令相结合,使机器人能够像人类一样进行思考和决策。通过语言这一媒介,机器人可以更好地理解社交环境的复杂性,并生成符合社会规范的导航行为。
技术框架:整体框架包含数据收集、模型训练和机器人部署三个主要阶段。首先,构建了SNEI数据集,包含大量人机交互场景的视觉数据和对应的语言描述。然后,使用SNEI数据集对预训练的VLM(LLaVA)进行微调,得到Social-LLaVA模型。最后,将Social-LLaVA部署到移动机器人上,使其能够根据视觉输入和语言指令进行导航。
关键创新:该论文的关键创新在于将视觉-语言模型应用于社交机器人导航领域,并提出了一个专门用于训练此类模型的数据集SNEI。通过这种方式,机器人能够利用语言进行推理,从而更好地理解和适应复杂的社交环境。此外,论文还通过实验证明了Social-LLaVA模型在社交导航任务上的优越性能。
关键设计:SNEI数据集包含4万个VQA,涵盖了感知、预测、思维链推理、动作和解释等多个方面。在模型训练方面,论文采用了微调策略,即在预训练的LLaVA模型的基础上,使用SNEI数据集进行训练。具体的损失函数和网络结构等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Social-LLaVA在社交机器人导航任务上取得了显著的性能提升,优于GPT-4V和Gemini等先进模型。具体而言,基于50个VQA上15个不同人类评委的平均得分,Social-LLaVA的性能超过了现有最佳模型,证明了其在理解和推理社交场景方面的优势。该结果表明,通过语言推理可以有效提升机器人在社交环境中的导航能力。
🎯 应用场景
该研究成果可应用于各种需要与人类进行交互的机器人应用场景,例如商场导览机器人、医院服务机器人、养老院陪伴机器人等。通过赋予机器人类人推理能力,可以提高其在复杂社交环境中的适应性和安全性,从而提升用户体验和工作效率。未来,该技术有望进一步发展,实现更加智能和自然的机器人人机交互。
📄 摘要(原文)
Most existing social robot navigation techniques either leverage hand-crafted rules or human demonstrations to connect robot perception to socially compliant actions. However, there remains a significant gap in effectively translating perception into socially compliant actions, much like how human reasoning naturally occurs in dynamic environments. Considering the recent success of Vision-Language Models (VLMs), we propose using language to bridge the gap in human-like reasoning between perception and socially aware robot actions. We create a vision-language dataset, Social robot Navigation via Explainable Interactions (SNEI), featuring 40K human-annotated Visual Question Answers (VQAs) based on 2K human-robot social interactions in unstructured, crowded public spaces, spanning perception, prediction, chain-of-thought reasoning, action, and explanation. We fine-tune a VLM, Social-LLaVA, using SNEI to demonstrate the practical application of our dataset. Social-LLaVA outperforms state-of-the-art models like GPT-4V and Gemini, based on the average of fifteen different human-judge scores across 50 VQA. Deployed onboard a mobile robot, Social-LLaVA enables human-like reasoning, marking a promising step toward socially compliant robot navigation in dynamic public spaces through language reasoning.