LTX-Video: Realtime Video Latent Diffusion
作者: Yoav HaCohen, Nisan Chiprut, Benny Brazowski, Daniel Shalem, Dudu Moshe, Eitan Richardson, Eran Levin, Guy Shiran, Nir Zabari, Ori Gordon, Poriya Panet, Sapir Weissbuch, Victor Kulikov, Yaki Bitterman, Zeev Melumian, Ofir Bibi
分类: cs.CV
发布日期: 2024-12-30
💡 一句话要点
LTX-Video:一种用于实时视频生成的基于Transformer的潜在扩散模型
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation)
关键词: 视频生成 潜在扩散模型 Transformer Video-VAE 实时视频生成
📋 核心要点
- 现有视频生成方法通常将Video-VAE和去噪Transformer视为独立组件,忽略了它们之间的交互优化。
- LTX-Video通过优化Video-VAE和去噪Transformer的交互,并在高压缩潜在空间中进行时空自注意力,实现高效高质量的视频生成。
- LTX-Video在Nvidia H100 GPU上实现了快于实时的视频生成,性能优于同等规模的现有模型,并开源了代码和预训练模型。
📝 摘要(中文)
LTX-Video是一种基于Transformer的潜在扩散模型,它采用整体方法进行视频生成,无缝集成了Video-VAE和去噪Transformer的功能。与现有方法将这些组件视为独立组件不同,LTX-Video旨在优化它们的交互以提高效率和质量。其核心是一个精心设计的Video-VAE,实现了1:192的高压缩比,每个token具有32 x 32 x 8像素的时空下采样,这通过将patchifying操作从Transformer的输入转移到VAE的输入来实现。在这种高度压缩的潜在空间中运行,使Transformer能够有效地执行完整的时空自注意力,这对于生成具有时间一致性的高分辨率视频至关重要。然而,高压缩固有地限制了对精细细节的表示。为了解决这个问题,我们的VAE解码器负责潜在到像素的转换和最终的去噪步骤,直接在像素空间中产生清晰的结果。这种方法保留了生成精细细节的能力,而不会产生单独上采样模块的运行时成本。我们的模型支持多种用例,包括文本到视频和图像到视频的生成,这两种能力同时进行训练。它实现了快于实时的生成速度,在Nvidia H100 GPU上仅需2秒即可生成5秒的24 fps、768x512分辨率的视频,优于所有类似规模的现有模型。源代码和预训练模型已公开提供,为可访问和可扩展的视频生成设置了新的基准。
🔬 方法详解
问题定义:现有视频生成方法通常将视频变分自编码器(Video-VAE)和去噪Transformer作为独立的模块进行设计和训练,忽略了它们之间的协同优化。这种分离的设计可能导致信息瓶颈,限制了生成视频的质量和效率。此外,现有方法在处理高分辨率视频时,计算复杂度高,难以实现实时生成。
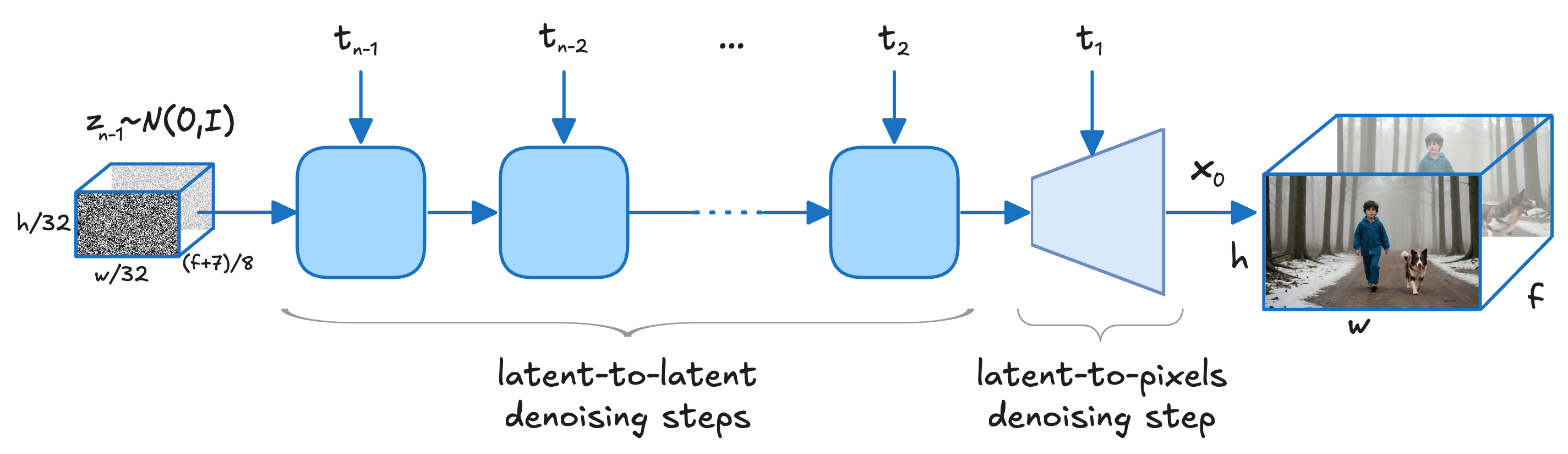
核心思路:LTX-Video的核心思路是将Video-VAE和去噪Transformer的功能进行整合,通过联合优化这两个模块,提高视频生成的效率和质量。具体来说,该方法将patchifying操作从Transformer的输入转移到VAE的输入,从而实现更高的压缩比,并在高度压缩的潜在空间中进行时空自注意力。同时,VAE解码器负责潜在到像素的转换和最终的去噪步骤,从而保留了生成精细细节的能力。
技术框架:LTX-Video的整体架构包括一个Video-VAE和一个Transformer。Video-VAE负责将视频压缩到潜在空间,并从潜在空间重建视频。Transformer在潜在空间中进行时空自注意力,以生成具有时间一致性的视频。VAE解码器则负责将潜在表示转换为像素空间,并进行最终的去噪。整个框架采用端到端的方式进行训练,以优化Video-VAE和Transformer之间的交互。
关键创新:LTX-Video最重要的技术创新点在于其整体性的设计理念,即将Video-VAE和去噪Transformer的功能进行整合,并通过联合优化这两个模块来提高视频生成的效率和质量。与现有方法将这两个模块视为独立组件不同,LTX-Video通过优化它们之间的交互,实现了更高的压缩比和更好的视频质量。此外,该方法还将patchifying操作从Transformer的输入转移到VAE的输入,从而进一步提高了压缩比。
关键设计:LTX-Video的关键设计包括:1)采用高压缩比的Video-VAE,实现32 x 32 x 8像素/token的时空下采样;2)在高度压缩的潜在空间中进行完整的时空自注意力;3)VAE解码器同时负责潜在到像素的转换和最终的去噪;4)采用端到端的训练方式,联合优化Video-VAE和Transformer。具体的损失函数和网络结构等细节在论文中进行了详细描述。
🖼️ 关键图片


📊 实验亮点
LTX-Video在Nvidia H100 GPU上实现了快于实时的视频生成,仅需2秒即可生成5秒的24 fps、768x512分辨率的视频。该模型优于所有类似规模的现有模型,并在文本到视频和图像到视频生成任务上都取得了良好的效果。此外,该研究还开源了源代码和预训练模型,为可访问和可扩展的视频生成设置了新的基准。
🎯 应用场景
LTX-Video具有广泛的应用前景,包括:文本到视频生成、图像到视频生成、视频编辑、虚拟现实、游戏开发等。该模型可以用于生成各种类型的视频内容,例如:动画、电影、广告等。由于其高效的生成速度,LTX-Video还可以用于实时视频应用,例如:视频会议、直播等。该研究的开源代码和预训练模型将促进视频生成技术的发展,并为相关领域的研究人员和开发者提供有价值的资源。
📄 摘要(原文)
We introduce LTX-Video, a transformer-based latent diffusion model that adopts a holistic approach to video generation by seamlessly integrating the responsibilities of the Video-VAE and the denoising transformer. Unlike existing methods, which treat these components as independent, LTX-Video aims to optimize their interaction for improved efficiency and quality. At its core is a carefully designed Video-VAE that achieves a high compression ratio of 1:192, with spatiotemporal downscaling of 32 x 32 x 8 pixels per token, enabled by relocating the patchifying operation from the transformer's input to the VAE's input. Operating in this highly compressed latent space enables the transformer to efficiently perform full spatiotemporal self-attention, which is essential for generating high-resolution videos with temporal consistency. However, the high compression inherently limits the representation of fine details. To address this, our VAE decoder is tasked with both latent-to-pixel conversion and the final denoising step, producing the clean result directly in pixel space. This approach preserves the ability to generate fine details without incurring the runtime cost of a separate upsampling module. Our model supports diverse use cases, including text-to-video and image-to-video generation, with both capabilities trained simultaneously. It achieves faster-than-real-time generation, producing 5 seconds of 24 fps video at 768x512 resolution in just 2 seconds on an Nvidia H100 GPU, outperforming all existing models of similar scale. The source code and pre-trained models are publicly available, setting a new benchmark for accessible and scalable video generation.