Vinci: A Real-time Embodied Smart Assistant based on Egocentric Vision-Language Model
作者: Yifei Huang, Jilan Xu, Baoqi Pei, Yuping He, Guo Chen, Lijin Yang, Xinyuan Chen, Yaohui Wang, Zheng Nie, Jinyao Liu, Guoshun Fan, Dechen Lin, Fang Fang, Kunpeng Li, Chang Yuan, Yali Wang, Yu Qiao, Limin Wang
分类: cs.CV
发布日期: 2024-12-30
🔗 代码/项目: GITHUB
💡 一句话要点
Vinci:基于第一视角视觉-语言模型的实时具身智能助手
🎯 匹配领域: 支柱六:视频提取与匹配 (Video Extraction)
关键词: 具身智能 第一视角视觉 视觉-语言模型 实时推理 任务规划
📋 核心要点
- 现有具身智能助手难以在便携设备上实时处理长视频流,限制了其在实际场景中的应用。
- Vinci通过第一视角视觉-语言模型,实现对环境的持续观察和理解,并提供自然对话交互。
- Vinci集成了视频生成模块,为用户提供任务的逐步可视化演示,提升了可用性。
📝 摘要(中文)
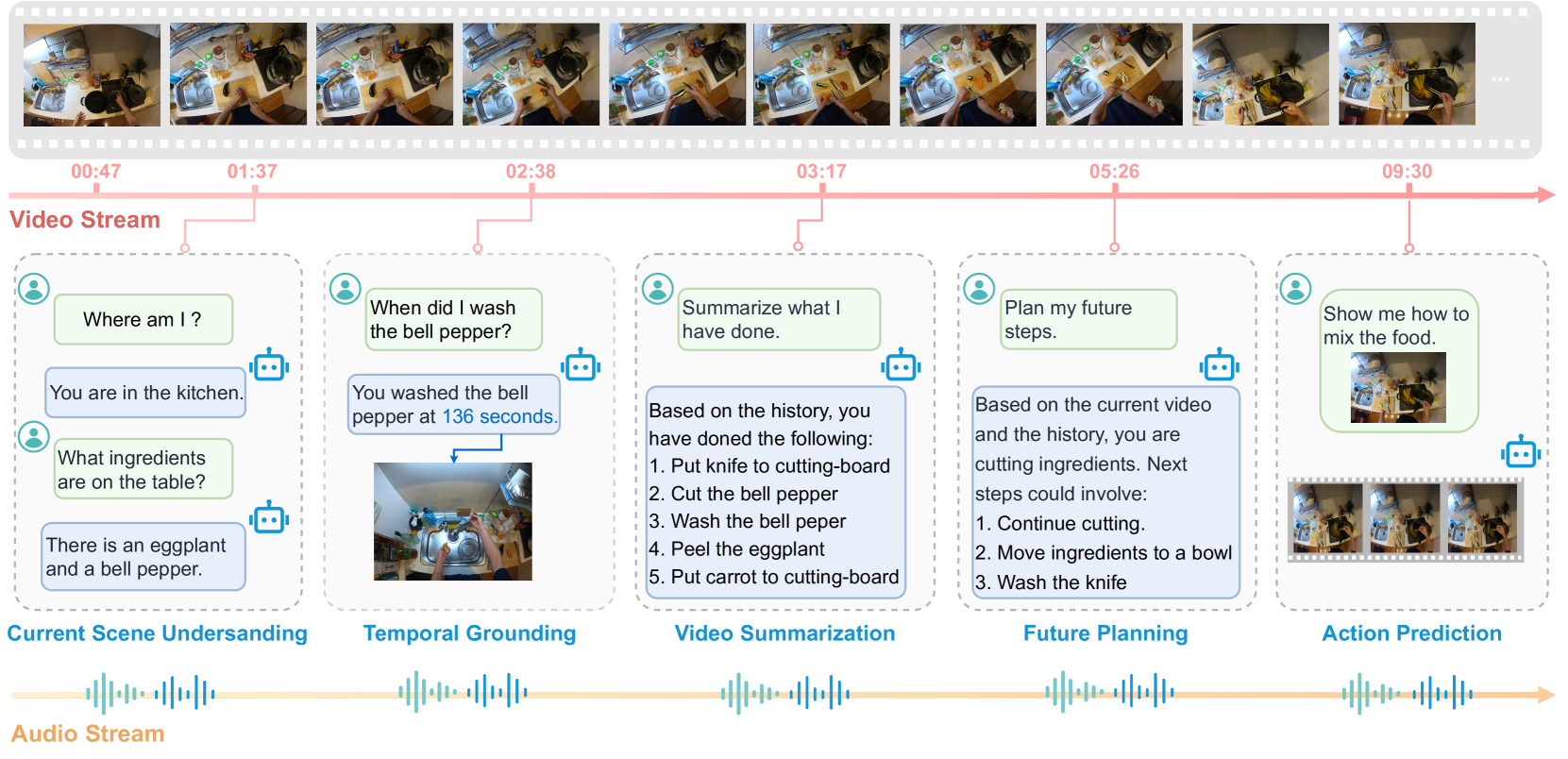
本文介绍Vinci,一个基于第一视角视觉-语言模型的实时具身智能助手。Vinci旨在部署在智能手机和可穿戴相机等便携设备上,以“始终在线”模式运行,持续观察环境,提供无缝交互和帮助。用户可以通过自然对话唤醒系统并提问或寻求帮助,系统通过音频提供免提回复。凭借实时处理长视频流的能力,Vinci可以回答用户关于当前观察和历史背景的查询,并根据过去的交互提供任务规划。为了进一步提高可用性,Vinci集成了一个视频生成模块,为需要详细指导的任务创建逐步的可视化演示。我们希望Vinci能够为便携式、实时第一视角人工智能系统建立一个强大的框架,使用户能够获得情境化和可操作的见解。我们发布了设备的完整实现,并提供了一个演示网络平台,用于测试上传的视频,地址为https://github.com/OpenGVLab/vinci。
🔬 方法详解
问题定义:论文旨在解决现有具身智能助手在便携设备上实时处理长视频流的难题。现有方法通常计算复杂度高,难以在资源受限的设备上实现实时推理,并且缺乏对历史信息的有效利用,导致无法进行复杂的任务规划和指导。
核心思路:论文的核心思路是利用第一视角视觉-语言模型,将视觉信息和语言信息进行有效融合,从而实现对环境的实时理解和交互。通过持续观察环境,系统可以积累历史信息,并根据用户的提问和需求,提供情境化的帮助和任务规划。
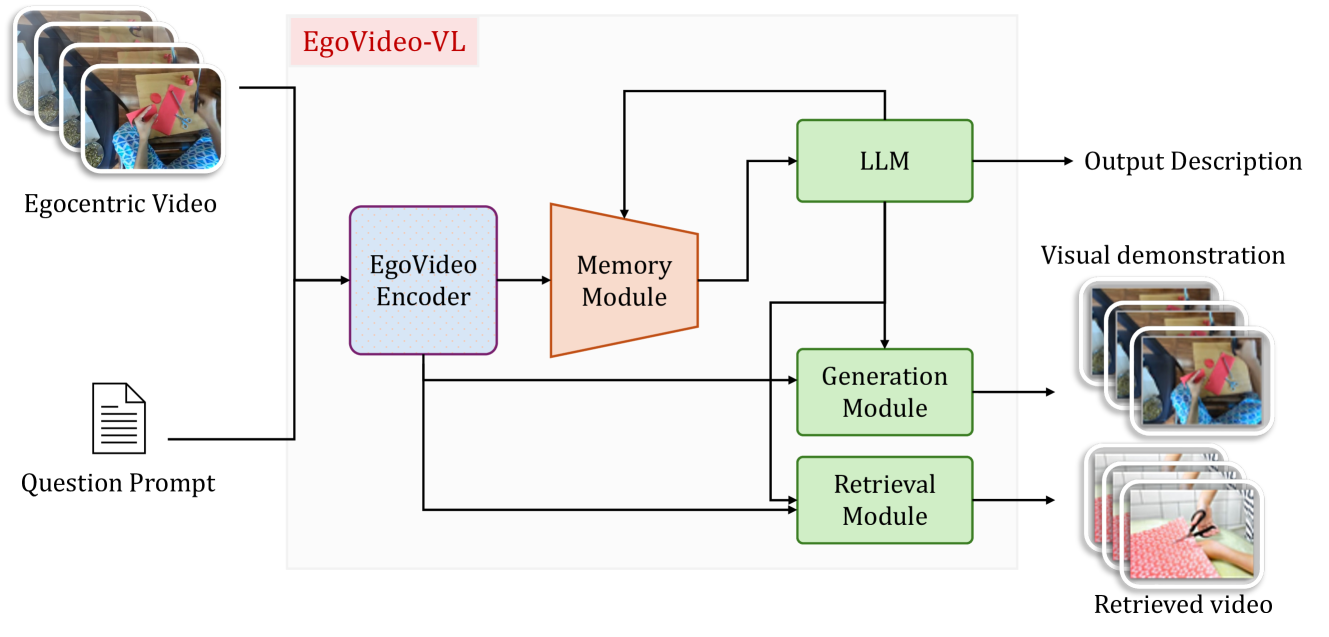
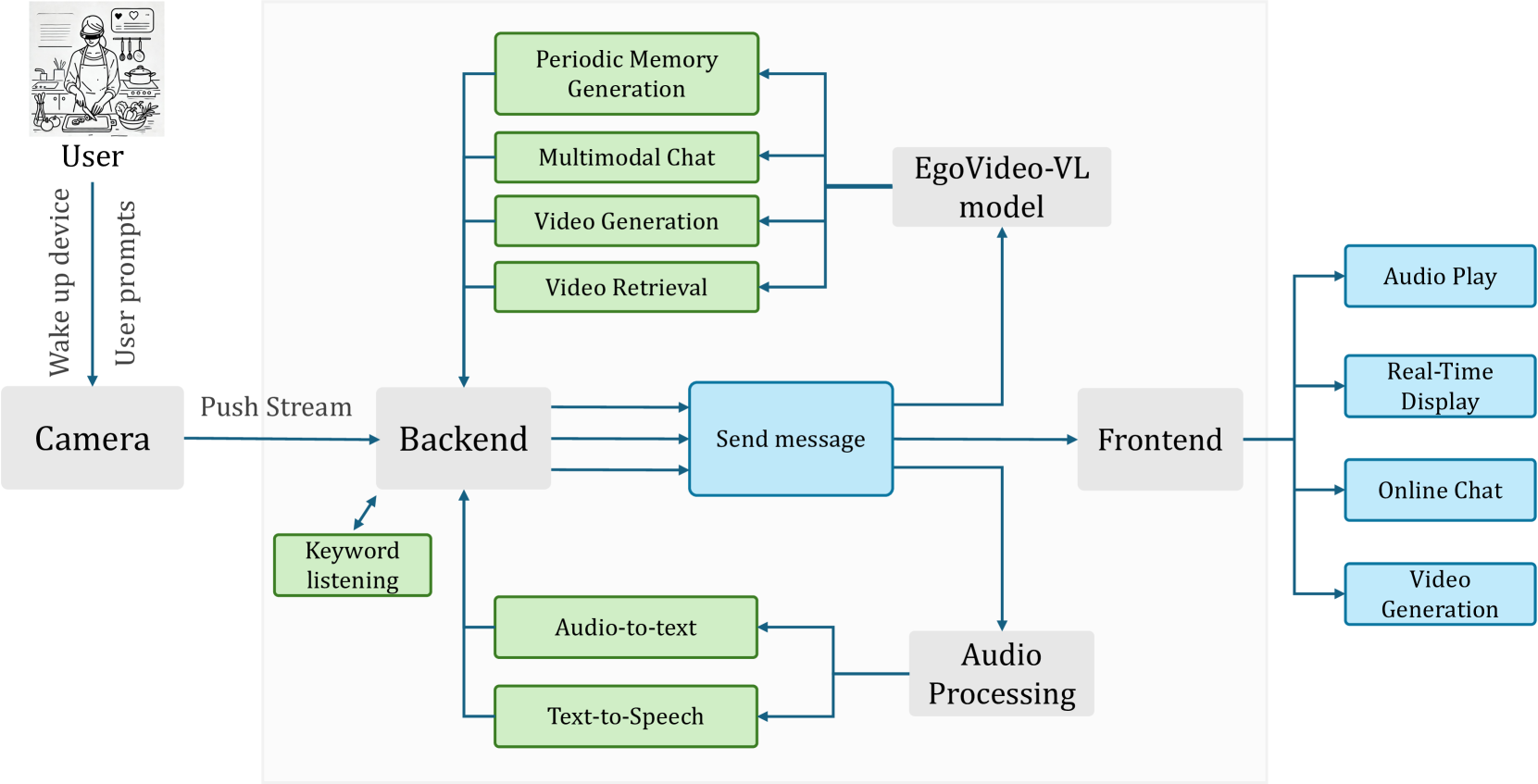
技术框架:Vinci的整体架构包含以下主要模块:1) 视频输入模块,负责接收来自摄像头的第一视角视频流;2) 视觉-语言模型,负责对视频流进行分析和理解,提取关键信息;3) 对话交互模块,负责与用户进行自然语言对话,理解用户意图;4) 任务规划模块,负责根据用户需求和历史信息,生成任务规划;5) 视频生成模块,负责生成任务的逐步可视化演示;6) 音频输出模块,负责将系统的回复以语音形式输出。
关键创新:Vinci的关键创新在于其集成了实时长视频理解、自然语言交互和视频生成功能,从而实现了一个完整的具身智能助手系统。与现有方法相比,Vinci能够更好地理解用户意图,并提供更具情境化的帮助和指导。此外,Vinci的视频生成模块可以为用户提供更直观的任务指导,提高了可用性。
关键设计:论文中没有详细描述具体的参数设置、损失函数和网络结构等技术细节。但是,可以推测视觉-语言模型可能采用了Transformer架构,并使用了对比学习等方法进行训练。视频生成模块可能采用了GAN或扩散模型等技术。
🖼️ 关键图片
📊 实验亮点
论文发布了Vinci的完整实现,并提供了一个演示网络平台,用户可以上传视频进行测试。虽然论文中没有提供具体的性能数据,但通过演示平台可以看出,Vinci能够实时处理长视频流,并根据用户提问提供合理的回复和任务规划。这表明Vinci在便携式具身智能助手领域具有很大的潜力。
🎯 应用场景
Vinci具有广泛的应用前景,例如智能家居控制、远程协助、教育培训和医疗保健等领域。它可以帮助用户更方便地控制智能设备,获取远程专家的指导,学习新的技能,以及进行健康监测和管理。未来,Vinci有望成为人们日常生活中不可或缺的智能助手。
📄 摘要(原文)
We introduce Vinci, a real-time embodied smart assistant built upon an egocentric vision-language model. Designed for deployment on portable devices such as smartphones and wearable cameras, Vinci operates in an "always on" mode, continuously observing the environment to deliver seamless interaction and assistance. Users can wake up the system and engage in natural conversations to ask questions or seek assistance, with responses delivered through audio for hands-free convenience. With its ability to process long video streams in real-time, Vinci can answer user queries about current observations and historical context while also providing task planning based on past interactions. To further enhance usability, Vinci integrates a video generation module that creates step-by-step visual demonstrations for tasks that require detailed guidance. We hope that Vinci can establish a robust framework for portable, real-time egocentric AI systems, empowering users with contextual and actionable insights. We release the complete implementation for the development of the device in conjunction with a demo web platform to test uploaded videos at https://github.com/OpenGVLab/vinci.