VisionReward: Fine-Grained Multi-Dimensional Human Preference Learning for Image and Video Generation
作者: Jiazheng Xu, Yu Huang, Jiale Cheng, Yuanming Yang, Jiajun Xu, Yuan Wang, Wenbo Duan, Shen Yang, Qunlin Jin, Shurun Li, Jiayan Teng, Zhuoyi Yang, Wendi Zheng, Xiao Liu, Dan Zhang, Ming Ding, Xiaohan Zhang, Xiaotao Gu, Shiyu Huang, Minlie Huang, Jie Tang, Yuxiao Dong
分类: cs.CV
发布日期: 2024-12-30 (更新: 2026-01-05)
备注: 27 pages
🔗 代码/项目: GITHUB
💡 一句话要点
提出VisionReward框架以解决视觉生成中的人类偏好对齐问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视觉生成 人类偏好学习 强化学习 可解释性 多维策略
📋 核心要点
- 现有的视觉生成模型在与人类偏好对齐方面存在黑箱评分和意外偏见等挑战。
- 本文提出VisionReward框架,通过分层视觉评估和线性加权实现可解释的人类偏好学习。
- 实验结果显示,VisionReward在偏好预测准确性上超越VideoScore 17.2%,并提高文本到视频模型的配对胜率31.6%。
📝 摘要(中文)
视觉生成模型在合成逼真图像和视频方面取得了显著进展,但在多个关键维度上与人类偏好对齐仍然面临挑战。尽管基于人类反馈的强化学习提供了偏好对齐的潜力,但现有的视觉生成奖励模型存在黑箱评分、缺乏可解释性和可能导致意外偏见等局限性。本文提出了VisionReward,一个用于图像和视频生成的人类视觉偏好学习的通用框架。具体而言,我们采用分层视觉评估框架来捕捉细粒度的人类偏好,并利用线性加权实现可解释的偏好学习。此外,我们在使用VisionReward作为偏好优化的奖励模型时,提出了一种多维一致策略。实验表明,VisionReward在机器指标和人类评估上显著优于现有的图像和视频奖励模型。
🔬 方法详解
问题定义:本文旨在解决视觉生成模型在与人类偏好对齐时的不足,现有方法往往缺乏可解释性,且可能引入偏见。
核心思路:VisionReward框架通过分层视觉评估捕捉细粒度偏好,并采用线性加权实现可解释的偏好学习,从而提升生成模型的输出质量。
技术框架:该框架包括分层视觉评估模块、线性加权模块和多维一致策略,整体流程为:首先进行视觉偏好评估,然后通过线性加权整合偏好信息,最后在生成过程中应用多维一致策略进行优化。
关键创新:VisionReward的主要创新在于其分层视觉评估和线性加权机制,使得偏好学习过程更加透明和可解释,与传统黑箱模型形成鲜明对比。
关键设计:在参数设置上,采用了适应性线性加权策略,损失函数设计为结合人类反馈的多维损失,网络结构则基于现有的生成模型进行优化,确保兼容性和有效性。
🖼️ 关键图片

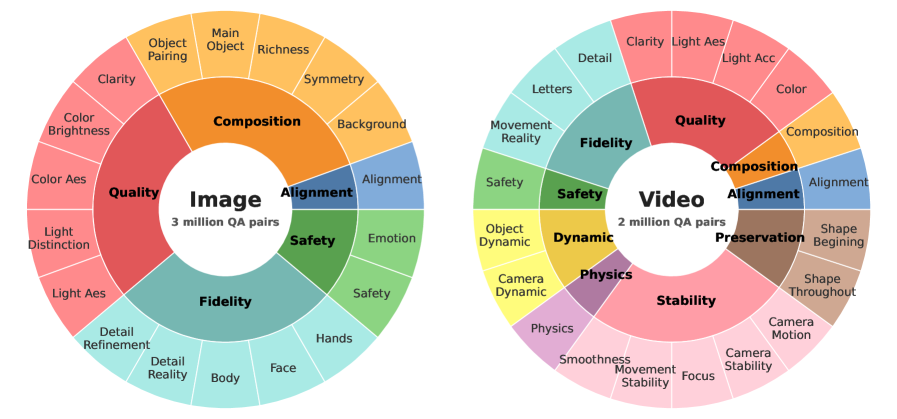
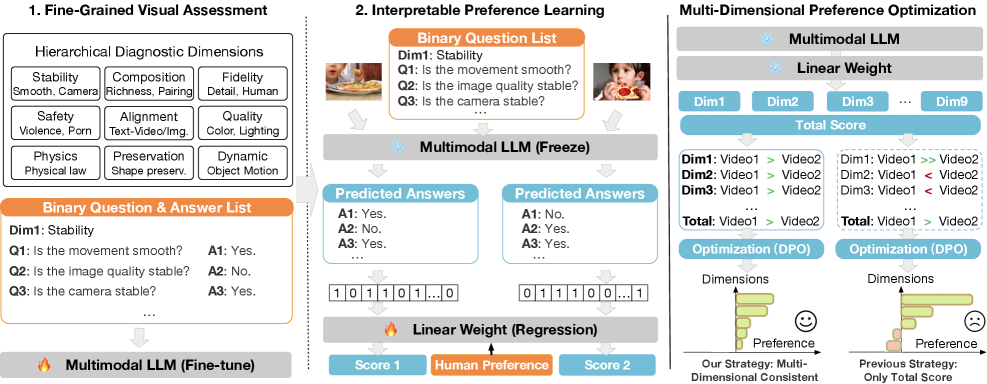
📊 实验亮点
实验结果表明,VisionReward在偏好预测准确性上超越了VideoScore 17.2%,并且在文本到视频生成任务中,使用VisionReward的模型相比使用VideoScore的模型,配对胜率提高了31.6%。这些结果表明VisionReward在视觉生成领域的显著优势。
🎯 应用场景
VisionReward框架具有广泛的应用潜力,特别是在图像和视频生成领域。其可解释的偏好学习机制能够帮助生成模型更好地满足用户需求,提升用户体验,未来可应用于广告、娱乐和教育等多个行业。
📄 摘要(原文)
Visual generative models have achieved remarkable progress in synthesizing photorealistic images and videos, yet aligning their outputs with human preferences across critical dimensions remains a persistent challenge. Though reinforcement learning from human feedback offers promise for preference alignment, existing reward models for visual generation face limitations, including black-box scoring without interpretability and potentially resultant unexpected biases. We present VisionReward, a general framework for learning human visual preferences in both image and video generation. Specifically, we employ a hierarchical visual assessment framework to capture fine-grained human preferences, and leverages linear weighting to enable interpretable preference learning. Furthermore, we propose a multi-dimensional consistent strategy when using VisionReward as a reward model during preference optimization for visual generation. Experiments show that VisionReward can significantly outperform existing image and video reward models on both machine metrics and human evaluation. Notably, VisionReward surpasses VideoScore by 17.2% in preference prediction accuracy, and text-to-video models with VisionReward achieve a 31.6% higher pairwise win rate compared to the same models using VideoScore. All code and datasets are provided at https://github.com/THUDM/VisionReward.