ReTaKe: Reducing Temporal and Knowledge Redundancy for Long Video Understanding
作者: Xiao Wang, Qingyi Si, Jianlong Wu, Shiyu Zhu, Li Cao, Liqiang Nie
分类: cs.CV, cs.CL, cs.MM
发布日期: 2024-12-29 (更新: 2025-03-24)
备注: Rewrite the methods section. Add more ablation studies and results in LongVideoBench. Update metadata
🔗 代码/项目: GITHUB
💡 一句话要点
ReTaKe:通过减少时序和知识冗余提升长视频理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长视频理解 视频大语言模型 时序冗余 知识冗余 视频压缩 关键帧选择 注意力机制
📋 核心要点
- 现有VideoLLM处理长视频时受限于LLM骨干网络的内存和计算能力,长度外推和视觉token压缩方法存在局限。
- ReTaKe通过DPSelect和PivotKV模块,联合减少时序视觉冗余和知识冗余,实现更高效的视频压缩。
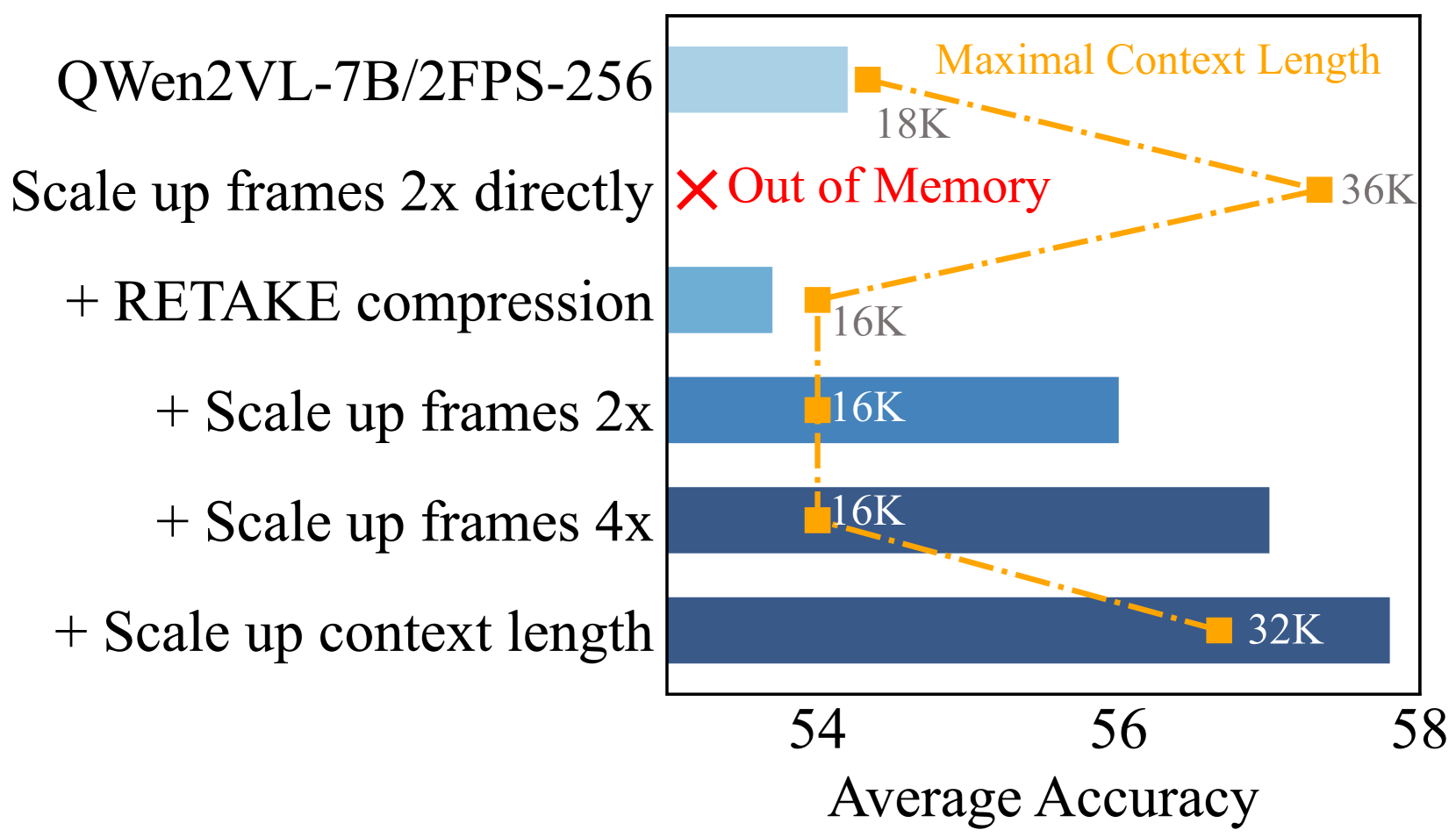
- 实验表明,ReTaKe能处理更长的视频帧,并在多个长视频理解benchmark上超越同等规模甚至更大规模的模型。
📝 摘要(中文)
视频大语言模型(VideoLLMs)在视频理解方面取得了显著进展,但由于其骨干LLM的限制,在处理长视频时面临挑战。现有解决方案依赖于长度外推(受内存限制)或视觉token压缩(主要利用低级时序冗余,忽略了更有效的高级知识冗余)。为了解决这个问题,我们提出ReTaKe,一种无需训练的方法,包含两个新颖的模块DPSelect和PivotKV,用于联合减少视频压缩的时序视觉冗余和知识冗余。为了与人类的时间感知方式对齐,DPSelect基于帧间距离峰值识别关键帧。为了利用LLM学习到的先验知识,PivotKV将关键帧标记为支点,并通过修剪非支点帧KV缓存中的低注意力token来压缩非支点帧。ReTaKe使VideoLLM能够处理8倍长的帧(高达2048帧),在VideoMME、MLVU、LongVideoBench和LVBench上,性能优于类似规模的模型3-5%,甚至可以与更大的模型相媲美。此外,通过将压缩操作与预填充重叠,ReTaKe仅引入约10%的预填充延迟开销,同时将解码延迟降低约20%。我们的代码可在https://github.com/SCZwangxiao/video-ReTaKe 获取。
🔬 方法详解
问题定义:现有VideoLLM在处理长视频时,面临着计算资源和内存的瓶颈。简单地扩展视频长度会导致内存溢出,而现有的视觉token压缩方法主要关注低层次的时序冗余,忽略了高层次的知识冗余,导致压缩效率不高。因此,需要一种更有效的视频压缩方法,能够在有限的资源下处理更长的视频,并保持较高的理解性能。
核心思路:ReTaKe的核心思路是同时减少视频中的时序冗余和知识冗余。通过DPSelect模块选择关键帧,减少时序上的冗余;通过PivotKV模块,利用LLM的先验知识,压缩非关键帧的KV缓存,减少知识上的冗余。这种联合压缩的方式能够更有效地利用计算资源,提高长视频理解的效率。
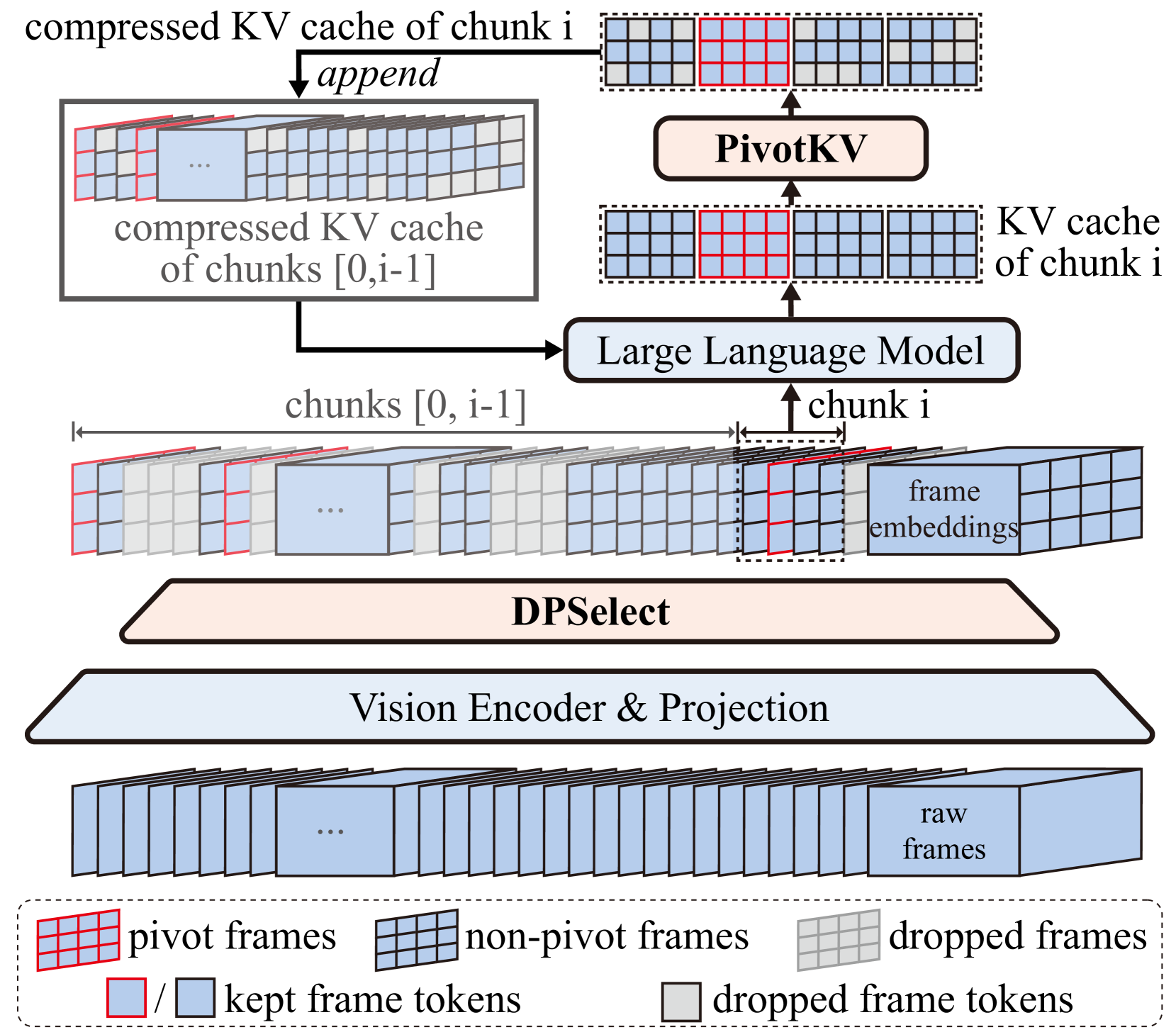
技术框架:ReTaKe的整体框架包含两个主要模块:DPSelect和PivotKV。首先,DPSelect模块根据帧间距离的峰值选择关键帧,从而减少时序冗余。然后,PivotKV模块将关键帧标记为支点,并根据LLM的注意力机制,修剪非支点帧KV缓存中的低注意力token,从而减少知识冗余。这两个模块可以并行执行,进一步提高效率。压缩后的视频token被输入到VideoLLM中进行处理。
关键创新:ReTaKe的关键创新在于联合考虑了时序冗余和知识冗余,并提出了相应的DPSelect和PivotKV模块。与现有方法相比,ReTaKe不仅关注低层次的时序冗余,还利用LLM的先验知识,减少高层次的知识冗余,从而实现更高效的视频压缩。此外,ReTaKe是一种无需训练的方法,可以直接应用于现有的VideoLLM,具有很强的通用性。
关键设计:DPSelect模块使用动态规划算法选择关键帧,目标是最大化关键帧之间的距离,同时保证关键帧的数量满足要求。PivotKV模块使用LLM的注意力权重来评估token的重要性,并根据设定的阈值修剪低注意力token。压缩比例可以根据实际需求进行调整。为了减少延迟,压缩操作与预填充阶段重叠进行。
🖼️ 关键图片

📊 实验亮点
ReTaKe在多个长视频理解benchmark上取得了显著的性能提升。在VideoMME、MLVU、LongVideoBench和LVBench上,ReTaKe的性能优于类似规模的模型3-5%,甚至可以与更大的模型相媲美。此外,ReTaKe仅引入约10%的预填充延迟开销,同时将解码延迟降低约20%。这些实验结果表明,ReTaKe是一种高效且有效的长视频理解方法。
🎯 应用场景
ReTaKe具有广泛的应用前景,例如在视频监控、自动驾驶、在线教育等领域。它可以帮助VideoLLM处理更长的视频,从而提高视频分析和理解的准确性和效率。此外,ReTaKe还可以应用于视频摘要、视频检索等任务,为用户提供更便捷的视频服务。未来,ReTaKe有望成为长视频理解领域的重要技术。
📄 摘要(原文)
Video Large Language Models (VideoLLMs) have made significant strides in video understanding but struggle with long videos due to the limitations of their backbone LLMs. Existing solutions rely on length extrapolation, which is memory-constrained, or visual token compression, which primarily leverages low-level temporal redundancy while overlooking the more effective high-level knowledge redundancy. To address this, we propose $\textbf{ReTaKe}$, a training-free method with two novel modules DPSelect and PivotKV, to jointly reduce both temporal visual redundancy and knowledge redundancy for video compression. To align with the way of human temporal perception, DPSelect identifies keyframes based on inter-frame distance peaks. To leverage LLMs' learned prior knowledge, PivotKV marks the keyframes as pivots and compress non-pivot frames by pruning low-attention tokens in their KV cache. ReTaKe enables VideoLLMs to process 8 times longer frames (up to 2048), outperforming similar-sized models by 3-5% and even rivaling much larger ones on VideoMME, MLVU, LongVideoBench, and LVBench. Moreover, by overlapping compression operations with prefilling, ReTaKe introduces only ~10% prefilling latency overhead while reducing decoding latency by ~20%. Our code is available at https://github.com/SCZwangxiao/video-ReTaKe.