Image Augmentation Agent for Weakly Supervised Semantic Segmentation
作者: Wangyu Wu, Xianglin Qiu, Siqi Song, Zhenhong Chen, Xiaowei Huang, Fei Ma, Jimin Xiao
分类: cs.CV
发布日期: 2024-12-29 (更新: 2025-08-24)
备注: Accepted at Neurocomputing 2025
💡 一句话要点
提出图像增强代理IAA,利用LLM和扩散模型提升弱监督语义分割性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 弱监督语义分割 图像增强 大型语言模型 扩散模型 数据生成 提示工程 自精炼
📋 核心要点
- 现有WSSS方法受限于固定数据集,忽略了数据多样性对模型性能的提升。
- 提出图像增强代理IAA,利用LLM和扩散模型自动生成更多样化的训练图像。
- 实验表明,IAA在PASCAL VOC 2012和MS COCO 2014数据集上显著超越了现有方法。
📝 摘要(中文)
弱监督语义分割(WSSS)仅使用图像级标签就取得了显著进展。然而,现有WSSS方法大多侧重于设计新的网络结构和损失函数以生成更精确的密集标签,而忽略了固定数据集的限制,这会约束性能的提升。我们认为,更多样化的可训练图像为WSSS提供了更丰富的信息,并有助于模型理解更全面的语义模式。因此,本文提出了一种名为图像增强代理(IAA)的新方法,表明从数据生成的角度增强WSSS是可行的。IAA主要设计了一个增强代理,该代理利用大型语言模型(LLM)和扩散模型自动生成额外的图像用于WSSS。在实践中,为了解决LLM生成提示的不稳定性,我们开发了一种提示自精炼机制,允许LLM重新评估生成提示的合理性,以产生更连贯的提示。此外,我们在扩散生成过程中插入了一个在线过滤器,以动态地确保生成图像的质量和平衡。实验结果表明,我们的方法在PASCAL VOC 2012和MS COCO 2014数据集上显著超越了最先进的WSSS方法。
🔬 方法详解
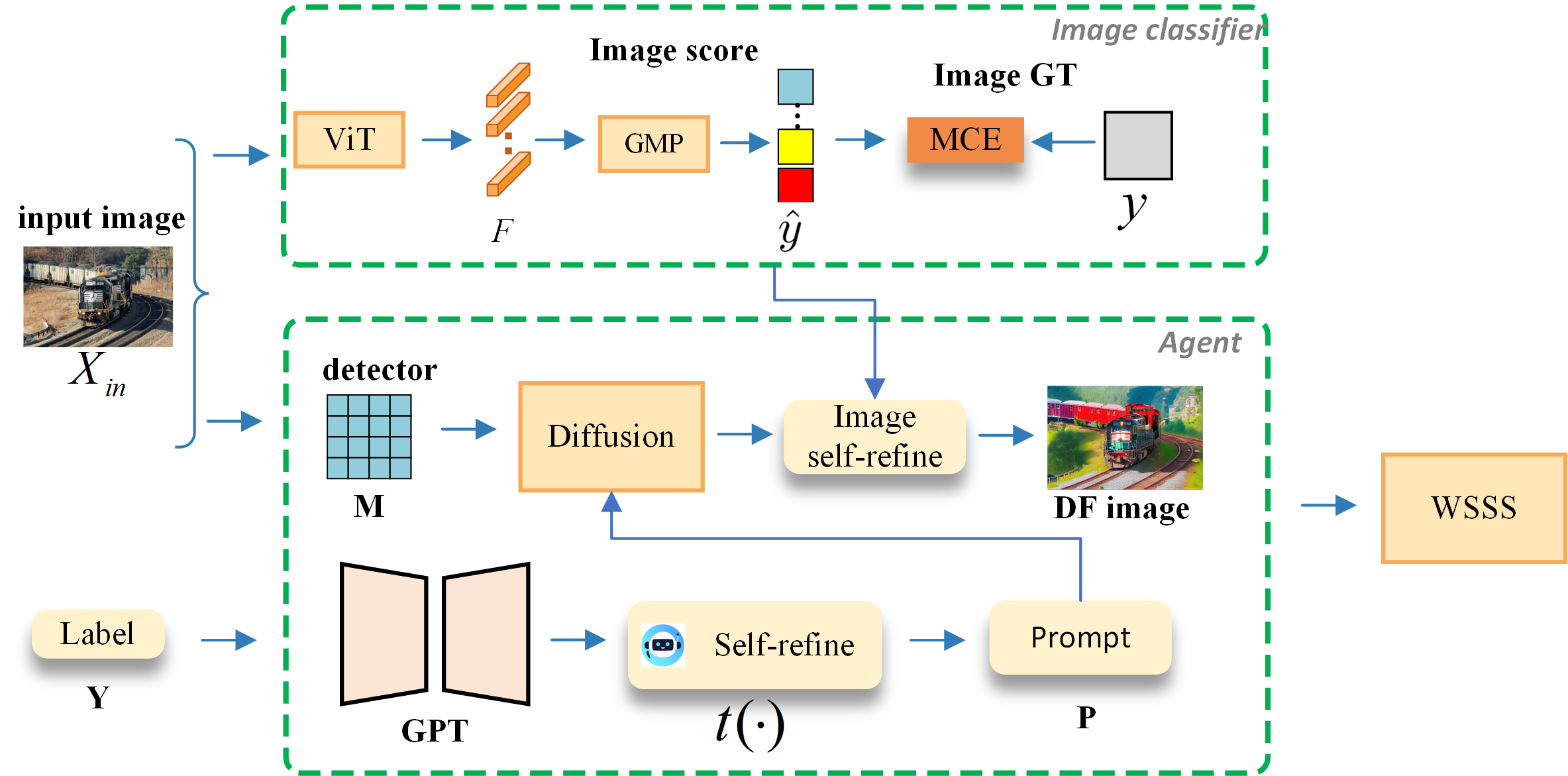
问题定义:现有的弱监督语义分割方法主要集中在网络结构和损失函数的设计上,而忽略了训练数据集本身的多样性不足。固定数据集限制了模型学习更全面的语义信息,从而制约了性能的进一步提升。因此,如何有效地扩充训练数据,提高数据的多样性,是本文要解决的关键问题。
核心思路:本文的核心思路是从数据生成的角度出发,利用大型语言模型(LLM)和扩散模型自动生成额外的训练图像。通过LLM生成图像描述提示,再利用扩散模型根据提示生成图像,从而扩充训练数据集,提高数据的多样性,最终提升弱监督语义分割的性能。
技术框架:IAA包含以下几个主要模块:1) LLM提示生成模块:利用LLM生成图像描述提示;2) 提示自精炼模块:对LLM生成的提示进行评估和优化,提高提示的质量和连贯性;3) 扩散模型图像生成模块:根据优化后的提示,利用扩散模型生成图像;4) 在线过滤模块:对生成的图像进行质量和平衡性过滤,确保生成图像的质量和类别分布;5) WSSS模型训练模块:利用原始数据集和生成的图像训练WSSS模型。
关键创新:本文的关键创新在于提出了一个完整的图像增强代理IAA,将LLM和扩散模型结合起来,自动生成高质量、多样化的训练图像,从而提升弱监督语义分割的性能。与现有方法相比,IAA从数据生成的角度出发,避免了对网络结构和损失函数的过度依赖,提供了一种全新的解决思路。
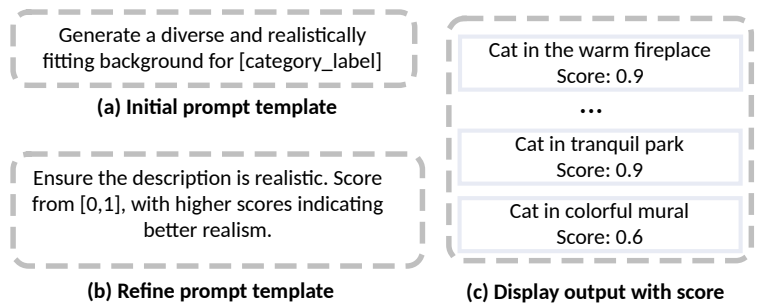
关键设计:1) 提示自精炼机制:通过LLM对生成的提示进行合理性评估,并进行迭代优化,提高提示的质量和连贯性。具体实现细节未知。2) 在线过滤模块:动态地对生成的图像进行质量和平衡性过滤,确保生成图像的质量和类别分布。具体实现细节未知。3) 损失函数和网络结构:论文主要关注数据增强,对损失函数和网络结构的选择没有特别说明,可能使用了常用的WSSS模型和损失函数。
🖼️ 关键图片

📊 实验亮点
实验结果表明,提出的IAA方法在PASCAL VOC 2012和MS COCO 2014数据集上显著超越了现有的最先进WSSS方法。具体的性能提升数据在摘要中没有给出,但强调了“显著超越”,说明IAA在性能上取得了实质性的提升。该方法验证了从数据增强角度提升WSSS性能的有效性。
🎯 应用场景
该研究成果可广泛应用于弱监督语义分割领域,尤其是在数据标注成本高昂或难以获取的情况下。例如,医学图像分析、遥感图像解译等领域,可以利用该方法生成更多样化的训练数据,提高模型的分割精度和泛化能力。未来,该方法还可以扩展到其他弱监督学习任务中,例如目标检测、图像描述等。
📄 摘要(原文)
Weakly-supervised semantic segmentation (WSSS) has achieved remarkable progress using only image-level labels. However, most existing WSSS methods focus on designing new network structures and loss functions to generate more accurate dense labels, overlooking the limitations imposed by fixed datasets, which can constrain performance improvements. We argue that more diverse trainable images provides WSSS richer information and help model understand more comprehensive semantic pattern. Therefore in this paper, we introduce a novel approach called Image Augmentation Agent (IAA) which shows that it is possible to enhance WSSS from data generation perspective. IAA mainly design an augmentation agent that leverages large language models (LLMs) and diffusion models to automatically generate additional images for WSSS. In practice, to address the instability in prompt generation by LLMs, we develop a prompt self-refinement mechanism. It allow LLMs to re-evaluate the rationality of generated prompts to produce more coherent prompts. Additionally, we insert an online filter into diffusion generation process to dynamically ensure the quality and balance of generated images. Experimental results show that our method significantly surpasses state-of-the-art WSSS approaches on the PASCAL VOC 2012 and MS COCO 2014 datasets.