Defending Multimodal Backdoored Models by Repulsive Visual Prompt Tuning
作者: Zhifang Zhang, Shuo He, Haobo Wang, Bingquan Shen, Lei Feng
分类: cs.CV
发布日期: 2024-12-29 (更新: 2025-10-30)
💡 一句话要点
提出排斥视觉Prompt调整(RVPT)防御多模态后门模型,提升视觉特征抗扰动性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 后门防御 视觉Prompt调整 对比学习 特征排斥 对抗训练 模型安全
📋 核心要点
- 多模态模型易受后门攻击,现有防御方法依赖中毒数据或需微调整个模型,成本高昂。
- RVPT通过视觉Prompt调整,对抗性地排斥非预测性特征,增强模型对扰动的抵抗力。
- RVPT仅需少量干净样本和微调少量参数,即可显著降低攻击成功率,并具备良好的泛化性。
📝 摘要(中文)
多模态对比学习模型(如CLIP)可以从大规模图文数据集中学习高质量的表征,但它们对后门攻击表现出显著的脆弱性,引发了严重的安全问题。本文揭示了CLIP的脆弱性主要源于其倾向于编码超出数据集预测模式的特征,从而损害了其视觉特征对输入扰动的抵抗力。这使得其编码特征极易被后门触发器重塑。为了应对这一挑战,我们提出了一种新的防御方法——排斥视觉Prompt调整(RVPT),该方法采用深度视觉prompt调整和专门设计的特征排斥损失。具体而言,RVPT在优化标准交叉熵损失的同时,对抗性地排斥来自更深层的编码特征,确保只编码下游任务中的预测特征,从而增强CLIP的视觉特征对输入扰动的抵抗力,并减轻其对后门攻击的敏感性。与通常需要中毒数据或涉及微调整个模型的现有多模态后门防御方法不同,RVPT利用少量下游干净样本,并且仅调整少量参数。实验结果表明,RVPT仅调整CLIP中0.27%的参数,但其性能显著优于最先进的防御方法,在ImageNet上针对最先进的多模态攻击,将攻击成功率从89.70%降低到2.76%,并有效地将其防御能力推广到多个数据集。
🔬 方法详解
问题定义:多模态对比学习模型,如CLIP,容易受到后门攻击,攻击者可以通过在训练数据中注入恶意触发器来控制模型的行为。现有的防御方法通常需要访问被污染的数据集进行训练,或者需要对整个模型进行微调,这在实际应用中是不可行的,并且计算成本很高。因此,需要一种高效且不需要访问被污染数据的防御方法。
核心思路:论文的核心思路是通过增强模型对输入扰动的抵抗力来防御后门攻击。具体来说,通过在视觉prompt调整过程中,引入一个特征排斥损失,使得模型在编码特征时,只关注与下游任务相关的预测性特征,而忽略那些容易被后门触发器利用的非预测性特征。这样,即使输入中存在后门触发器,模型也不会被其影响,从而达到防御后门攻击的目的。
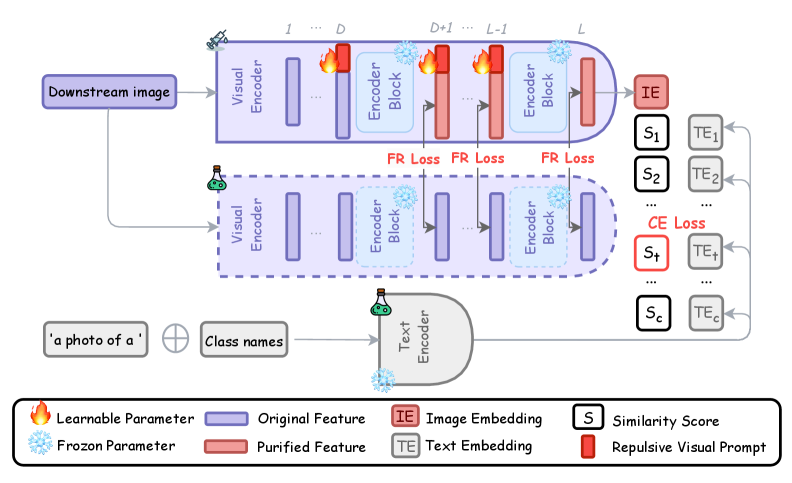
技术框架:RVPT的整体框架是在预训练的CLIP模型的基础上,添加一个可学习的视觉prompt。在训练过程中,RVPT同时优化两个损失函数:一个是标准的交叉熵损失,用于保证模型在下游任务上的性能;另一个是特征排斥损失,用于排斥那些容易被后门触发器利用的非预测性特征。通过这种方式,RVPT可以增强模型对输入扰动的抵抗力,从而防御后门攻击。
关键创新:RVPT的关键创新在于提出了特征排斥损失。该损失函数通过对抗性地排斥来自更深层的编码特征,使得模型在编码特征时,只关注与下游任务相关的预测性特征。这种方法与现有的防御方法不同,它不需要访问被污染的数据集,也不需要对整个模型进行微调,因此更加高效和实用。
关键设计:RVPT的关键设计包括:1) 使用深度视觉prompt tuning,允许模型学习更复杂的特征表示;2) 设计特征排斥损失,对抗性地排斥非预测性特征;3) 使用少量干净样本进行训练,降低了对数据的需求;4) 仅调整少量参数,降低了计算成本。特征排斥损失的具体形式未知,论文中可能没有详细描述其数学公式。
🖼️ 关键图片
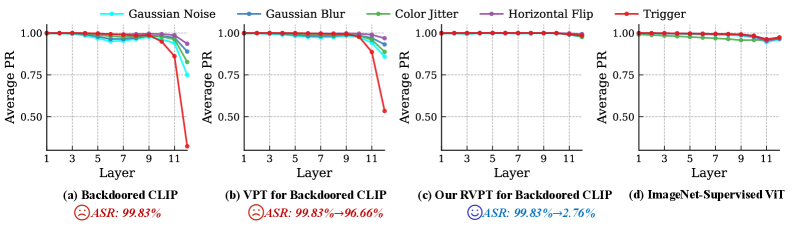
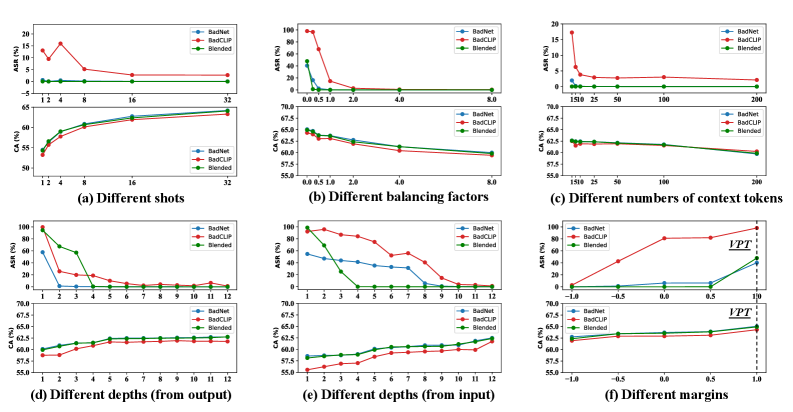
📊 实验亮点
RVPT在ImageNet数据集上针对最先进的多模态攻击,将攻击成功率从89.70%显著降低到2.76%,性能优于现有防御方法。更重要的是,RVPT仅需调整CLIP模型中0.27%的参数,并且能够有效地将其防御能力推广到多个数据集,展示了其高效性和泛化能力。
🎯 应用场景
RVPT可应用于各种多模态应用场景,例如图像分类、图像检索、视觉问答等,尤其适用于对安全性要求较高的场景。该方法能够有效防御后门攻击,提高多模态模型的可靠性和安全性,降低恶意攻击带来的风险,具有重要的实际应用价值和潜在的社会影响。
📄 摘要(原文)
Multimodal contrastive learning models (e.g., CLIP) can learn high-quality representations from large-scale image-text datasets, while they exhibit significant vulnerabilities to backdoor attacks, raising serious safety concerns. In this paper, we reveal that CLIP's vulnerabilities primarily stem from its tendency to encode features beyond in-dataset predictive patterns, compromising its visual feature resistivity to input perturbations. This makes its encoded features highly susceptible to being reshaped by backdoor triggers. To address this challenge, we propose Repulsive Visual Prompt Tuning (RVPT), a novel defense approach that employs deep visual prompt tuning with a specially designed feature-repelling loss. Specifically, RVPT adversarially repels the encoded features from deeper layers while optimizing the standard cross-entropy loss, ensuring that only predictive features in downstream tasks are encoded, thereby enhancing CLIP's visual feature resistivity against input perturbations and mitigating its susceptibility to backdoor attacks. Unlike existing multimodal backdoor defense methods that typically require the availability of poisoned data or involve fine-tuning the entire model, RVPT leverages few-shot downstream clean samples and only tunes a small number of parameters. Empirical results demonstrate that RVPT tunes only 0.27\% of the parameters in CLIP, yet it significantly outperforms state-of-the-art defense methods, reducing the attack success rate from 89.70\% to 2.76\% against the most advanced multimodal attacks on ImageNet and effectively generalizes its defensive capabilities across multiple datasets.