Multi-Modality Driven LoRA for Adverse Condition Depth Estimation
作者: Guanglei Yang, Rui Tian, Yongqiang Zhang, Zhun Zhong, Yongqiang Li, Wangmeng Zuo
分类: cs.CV
发布日期: 2024-12-28
💡 一句话要点
提出MMD-LoRA,通过多模态驱动的LoRA方法提升恶劣天气下的深度估计性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 深度估计 恶劣天气 多模态学习 低秩适应 域自适应
📋 核心要点
- 现有恶劣天气深度估计方法复杂度高,调优困难,且多模态特征对齐不足,限制了性能。
- MMD-LoRA利用低秩适应矩阵进行高效微调,并设计PDDA和VTCCL模块实现域对齐和多模态一致性。
- 实验表明,MMD-LoRA在nuScenes和Oxford RobotCar数据集上取得了SOTA性能,验证了其有效性。
📝 摘要(中文)
本文针对自动驾驶领域中日益重要的恶劣条件(如夜间、雾天、雨天)下的驾驶安全问题,提出了多模态驱动的LoRA(MMD-LoRA)方法,用于恶劣条件下的深度估计(ACDE)。现有ACDE方法主要依赖生成模型或可学习参数进行特征增强,导致模型复杂度和调优难度增加,且缺乏多模态特征的充分对齐。MMD-LoRA利用低秩适应矩阵进行高效的源域到目标域的微调,包含提示驱动的域对齐(PDDA)和视觉-文本一致性对比学习(VTCCL)两个核心组件。PDDA通过对齐损失监督图像编码器生成目标域视觉表示,使语言和图像之间的源-目标差异相等。VTCCL弥合了CLIP文本特征和扩散模型视觉特征之间的差距,区分不同的天气表示,并聚集相似的表示。实验结果表明,该方法在nuScenes和Oxford RobotCar数据集上取得了最先进的性能,验证了其在各种恶劣环境中的鲁棒性和效率。
🔬 方法详解
问题定义:论文旨在解决恶劣天气条件下的深度估计问题,即ACDE。现有方法主要依赖于生成模型或可学习参数进行特征增强,增加了模型复杂度和调优难度。此外,现有方法缺乏对多模态特征(如图像和文本)的充分对齐,导致模型在恶劣天气下的理解能力不足。
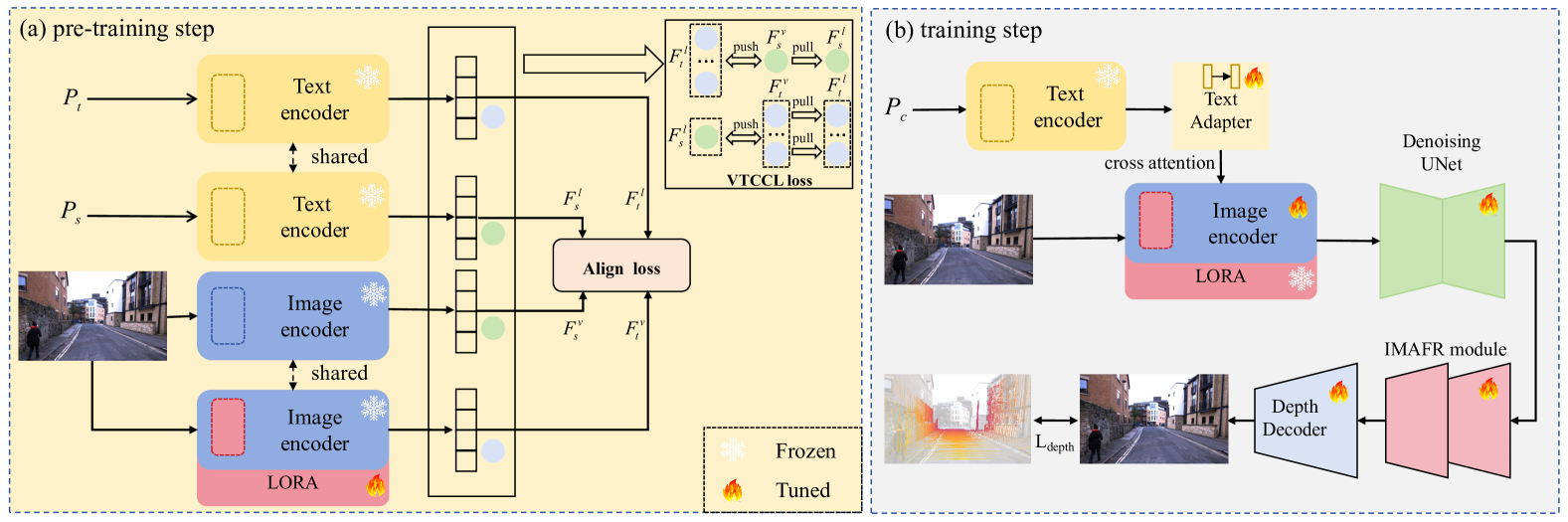
核心思路:论文的核心思路是利用低秩适应(LoRA)技术,通过少量可训练参数实现源域到目标域的高效迁移学习。同时,通过提示驱动的域对齐(PDDA)和视觉-文本一致性对比学习(VTCCL)来增强多模态特征的对齐,从而提高模型在恶劣天气下的深度估计性能。
技术框架:MMD-LoRA包含两个主要模块:PDDA和VTCCL。PDDA模块利用LoRA对图像编码器进行微调,并通过对齐损失来监督目标域视觉表示的生成,使得图像和文本之间的域差异尽可能一致。VTCCL模块则通过对比学习,拉近相似天气的视觉和文本表示,推远不同天气的表示,从而增强多模态特征的一致性。整体流程是先通过PDDA进行域对齐,再通过VTCCL增强多模态一致性,最终提升深度估计性能。
关键创新:论文的关键创新在于将LoRA技术应用于恶劣天气深度估计,并结合PDDA和VTCCL模块,实现了高效的域适应和多模态特征对齐。与现有方法相比,MMD-LoRA避免了复杂的生成模型或特征增强模块,降低了模型复杂度和调优难度,同时通过多模态对齐提高了模型在恶劣天气下的理解能力。
关键设计:PDDA模块的关键在于对齐损失的设计,该损失旨在最小化图像和文本之间的源域和目标域的差异。VTCCL模块的关键在于对比学习的损失函数设计,需要选择合适的正负样本,并调整温度系数等参数,以实现最佳的多模态对齐效果。此外,LoRA的秩(rank)的选择也会影响模型的性能和训练效率。
🖼️ 关键图片


📊 实验亮点
MMD-LoRA在nuScenes和Oxford RobotCar数据集上取得了state-of-the-art的性能。具体而言,相较于之前的最佳方法,在nuScenes数据集上取得了显著的性能提升,并在Oxford RobotCar数据集上也表现出强大的竞争力,验证了其在不同恶劣环境下的鲁棒性和有效性。具体指标提升数据未知,但强调了SOTA性能。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、智能监控等领域,尤其是在恶劣天气条件下。通过提高深度估计的准确性和鲁棒性,可以提升自动驾驶系统的安全性,减少事故发生率。此外,该方法还可以应用于虚拟现实、游戏等领域,增强沉浸感和真实感。
📄 摘要(原文)
The autonomous driving community is increasingly focused on addressing corner case problems, particularly those related to ensuring driving safety under adverse conditions (e.g., nighttime, fog, rain). To this end, the task of Adverse Condition Depth Estimation (ACDE) has gained significant attention. Previous approaches in ACDE have primarily relied on generative models, which necessitate additional target images to convert the sunny condition into adverse weather, or learnable parameters for feature augmentation to adapt domain gaps, resulting in increased model complexity and tuning efforts. Furthermore, unlike CLIP-based methods where textual and visual features have been pre-aligned, depth estimation models lack sufficient alignment between multimodal features, hindering coherent understanding under adverse conditions. To address these limitations, we propose Multi-Modality Driven LoRA (MMD-LoRA), which leverages low-rank adaptation matrices for efficient fine-tuning from source-domain to target-domain. It consists of two core components: Prompt Driven Domain Alignment (PDDA) and Visual-Text Consistent Contrastive Learning(VTCCL). During PDDA, the image encoder with MMD-LoRA generates target-domain visual representations, supervised by alignment loss that the source-target difference between language and image should be equal. Meanwhile, VTCCL bridges the gap between textual features from CLIP and visual features from diffusion model, pushing apart different weather representations (vision and text) and bringing together similar ones. Through extensive experiments, the proposed method achieves state-of-the-art performance on the nuScenes and Oxford RobotCar datasets, underscoring robustness and efficiency in adapting to varied adverse environments.