ST$^3$: Accelerating Multimodal Large Language Model by Spatial-Temporal Visual Token Trimming
作者: Jiedong Zhuang, Lu Lu, Ming Dai, Rui Hu, Jian Chen, Qiang Liu, Haoji Hu
分类: cs.CV
发布日期: 2024-12-28
备注: Accepted to AAAI2025
💡 一句话要点
提出ST³框架,通过时空视觉令牌修剪加速多模态大语言模型推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉令牌修剪 模型加速 注意力机制 推理优化
📋 核心要点
- 现有MLLM处理大量视觉令牌导致计算成本高昂,且现有剪枝策略在速度和精度间平衡不足。
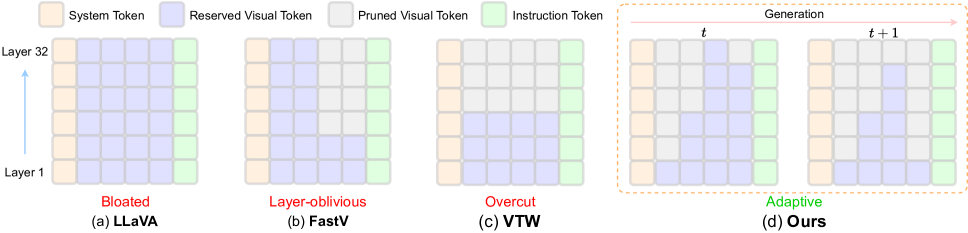
- ST³框架通过逐层剪枝不重要视觉令牌和动态调整每层令牌数量,实现高效推理。
- 实验表明,ST³在保持性能的同时,推理速度提升约2倍,KV缓存内存需求降低约70%。
📝 摘要(中文)
多模态大语言模型(MLLMs)通过整合视觉和文本信息来增强感知能力。然而,处理大量的视觉令牌会产生巨大的计算成本。现有对MLLM注意力机制的分析仍然不够深入,导致粗粒度的令牌剪枝策略无法有效地平衡速度和准确性。本文对LLaVA的MLLM注意力机制进行了全面研究,发现解码过程中存在大量冗余的视觉令牌和部分注意力计算。基于此,我们提出了空间-时间视觉令牌修剪(ST³),该框架旨在加速MLLM推理而无需重新训练。ST³包含两个主要组成部分:1) 逐层视觉令牌剪枝(PVTP),它消除了跨层的不重要的视觉令牌;2) 视觉令牌退火(VTA),它随着生成令牌的增长动态地减少每层中的视觉令牌数量。这些技术共同实现了大约2倍的推理速度提升,并且仅需原始LLaVA约30%的KV缓存内存,同时保持了跨各种数据集的一致性能。至关重要的是,ST³可以无缝集成到现有的预训练MLLM中,为高效推理提供了一种即插即用的解决方案。
🔬 方法详解
问题定义:论文旨在解决多模态大语言模型(MLLM)推理过程中,由于处理大量视觉tokens而导致的计算成本过高的问题。现有方法通常采用粗粒度的token剪枝策略,无法在速度和精度之间取得良好的平衡,导致推理效率提升有限,甚至影响模型性能。
核心思路:论文的核心思路是深入分析MLLM的注意力机制,发现并去除冗余的视觉tokens,从而降低计算量。具体而言,通过观察不同层和不同生成阶段的视觉tokens的重要性,自适应地进行剪枝和调整,以在保证模型性能的前提下,最大程度地加速推理过程。
技术框架:ST³框架包含两个主要模块:逐层视觉令牌剪枝(PVTP)和视觉令牌退火(VTA)。PVTP模块通过评估每个视觉token的重要性,在不同层逐步移除不重要的tokens。VTA模块则根据已生成的文本tokens数量,动态调整每层中视觉tokens的数量,实现更精细的资源分配。整个框架可以无缝集成到现有的预训练MLLM中,无需重新训练。
关键创新:ST³的关键创新在于其时空自适应的视觉token修剪策略。与传统的静态或粗粒度剪枝方法不同,ST³能够根据不同层和不同生成阶段的tokens重要性,动态地进行剪枝和调整,从而更有效地去除冗余计算,提高推理效率。
关键设计:PVTP模块使用注意力权重作为token重要性的评估指标,并设置阈值来决定是否剪枝。VTA模块则根据已生成的文本tokens数量,使用预定义的退火策略来动态调整每层中视觉tokens的数量。具体的阈值和退火策略需要根据不同的模型和数据集进行调整,以达到最佳的性能和效率平衡。
🖼️ 关键图片


📊 实验亮点
实验结果表明,ST³框架在LLaVA模型上实现了约2倍的推理速度提升,同时将KV缓存内存需求降低了约70%,并且在多个数据集上保持了与原始模型相当的性能。这些结果表明,ST³是一种高效且实用的MLLM加速方法。
🎯 应用场景
该研究成果可广泛应用于需要高效多模态信息处理的场景,例如智能客服、自动驾驶、医疗诊断等。通过降低MLLM的计算成本,可以使其在资源受限的设备上运行,并加速相关应用的部署和普及。此外,该方法还可以促进更大规模MLLM的研发,从而提升人工智能的整体能力。
📄 摘要(原文)
Multimodal large language models (MLLMs) enhance their perceptual capabilities by integrating visual and textual information. However, processing the massive number of visual tokens incurs a significant computational cost. Existing analysis of the MLLM attention mechanisms remains shallow, leading to coarse-grain token pruning strategies that fail to effectively balance speed and accuracy. In this paper, we conduct a comprehensive investigation of MLLM attention mechanisms with LLaVA. We find that numerous visual tokens and partial attention computations are redundant during the decoding process. Based on this insight, we propose Spatial-Temporal Visual Token Trimming ($\textbf{ST}^{3}$), a framework designed to accelerate MLLM inference without retraining. $\textbf{ST}^{3}$ consists of two primary components: 1) Progressive Visual Token Pruning (\textbf{PVTP}), which eliminates inattentive visual tokens across layers, and 2) Visual Token Annealing (\textbf{VTA}), which dynamically reduces the number of visual tokens in each layer as the generated tokens grow. Together, these techniques deliver around $\mathbf{2\times}$ faster inference with only about $\mathbf{30\%}$ KV cache memory compared to the original LLaVA, while maintaining consistent performance across various datasets. Crucially, $\textbf{ST}^{3}$ can be seamlessly integrated into existing pre-trained MLLMs, providing a plug-and-play solution for efficient inference.