Exploring Compositional Generalization of Multimodal LLMs for Medical Imaging
作者: Zhenyang Cai, Junying Chen, Rongsheng Wang, Weihong Wang, Yonglin Deng, Dingjie Song, Yize Chen, Zixu Zhang, Benyou Wang
分类: cs.CV, cs.AI, cs.CL, cs.LG
发布日期: 2024-12-28 (更新: 2025-05-31)
🔗 代码/项目: GITHUB
💡 一句话要点
探索多模态LLM在医学影像中组合泛化能力,揭示多任务训练的内在机理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学影像分析 多模态学习 大型语言模型 组合泛化 多任务学习
📋 核心要点
- 现有医学影像分析方法缺乏对多任务训练内在机理的深入理解,未能充分挖掘任务间的关系。
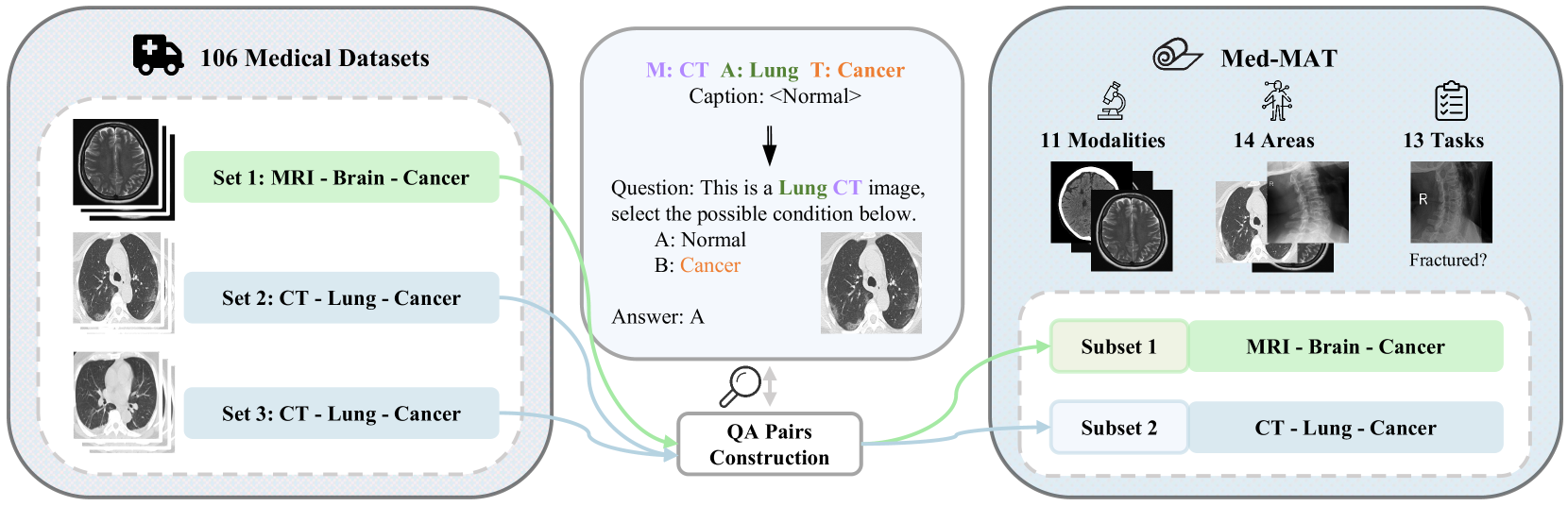
- 论文提出利用组合泛化(CG)框架,将医学影像分解为模态、解剖区域和任务三个维度,分析MLLM的泛化能力。
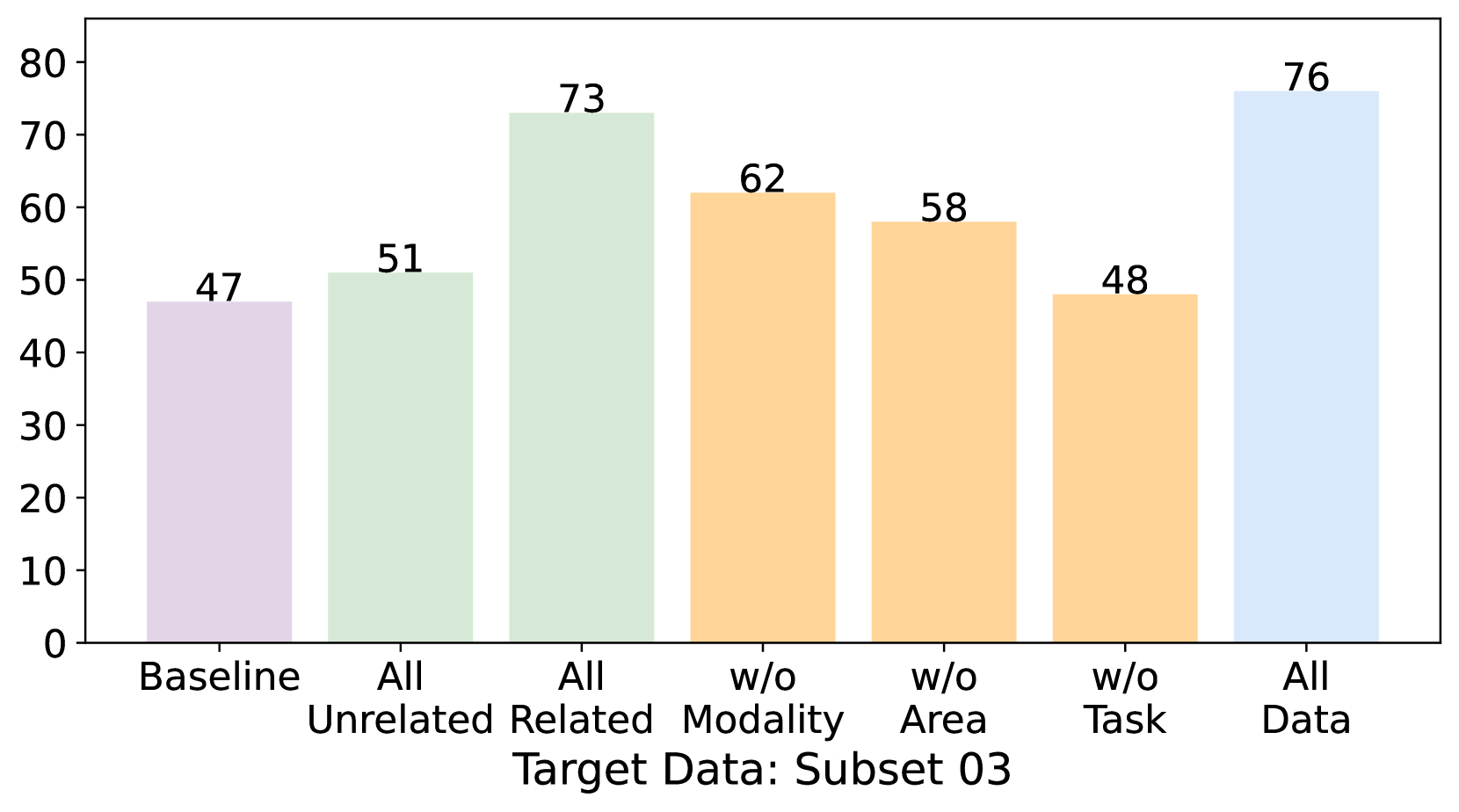
- 实验结果表明,CG是MLLM在医学影像分析中泛化的主要驱动因素之一,尤其在数据有限的情况下表现出色。
📝 摘要(中文)
医学影像为诊断提供重要的视觉信息,多模态大型语言模型(MLLM)因其强大的泛化能力而被越来越多地用于医学影像分析;然而,驱动这种泛化的根本因素仍不清楚。目前的研究表明,多任务训练优于单任务训练,因为不同的任务可以相互受益,但它们往往忽略了这些任务之间的内在关系。为了分析这种现象,我们尝试采用组合泛化(CG)作为一个指导框架,组合泛化指的是模型通过重组学习到的元素来理解新的组合的能力。由于医学图像可以通过模态、解剖区域和任务来精确定义,自然地为探索CG提供了一个环境,我们组装了106个医学数据集来创建Med-MAT,用于全面的实验。实验证实,MLLM可以使用CG来理解未见过的医学图像,并确定CG是多任务训练中观察到的泛化的主要驱动因素之一。此外,进一步的研究表明,CG有效地支持数据有限的数据集,并证实MLLM可以在分类和检测任务中实现CG,突显了其更广泛的泛化潜力。Med-MAT可在https://github.com/FreedomIntelligence/Med-MAT获取。
🔬 方法详解
问题定义:论文旨在解决多模态大型语言模型(MLLM)在医学影像分析中泛化能力的内在驱动因素不明的问题。现有方法通常侧重于多任务训练,但忽略了不同任务之间的内在联系,缺乏对模型如何利用已学知识组合泛化到新任务的深入理解。
核心思路:论文的核心思路是将组合泛化(Compositional Generalization, CG)引入医学影像分析领域,并将其作为理解MLLM泛化能力的关键框架。通过将医学影像分解为模态(Modality)、解剖区域(Anatomical area)和任务(Task)三个维度,研究模型如何通过重组已学习的元素来理解新的医学影像组合。
技术框架:论文构建了一个名为Med-MAT的大规模医学影像数据集,包含106个医学数据集,涵盖多种模态、解剖区域和任务。研究人员使用Med-MAT对MLLM进行训练和评估,分析其在不同组合下的泛化性能。整体流程包括:1) 数据集构建:收集和整理医学影像数据,并按照模态、解剖区域和任务进行标注;2) 模型训练:使用MLLM在Med-MAT上进行多任务训练;3) 泛化能力评估:测试模型在未见过的医学影像组合上的性能,并分析CG对泛化的影响。
关键创新:论文的关键创新在于将组合泛化(CG)的概念引入医学影像分析领域,并将其作为理解MLLM泛化能力的关键框架。通过构建Med-MAT数据集,论文提供了一个系统性的评估平台,用于研究MLLM在医学影像中的CG能力。与现有方法相比,该研究更注重揭示模型泛化的内在机理,而非仅仅关注性能指标的提升。
关键设计:论文的关键设计包括:1) Med-MAT数据集的构建,确保数据集的多样性和覆盖范围;2) 实验设计,通过控制模态、解剖区域和任务的组合,系统性地评估MLLM的CG能力;3) 评估指标的选择,采用合适的指标来衡量模型在不同组合下的泛化性能。具体的参数设置、损失函数和网络结构等技术细节在论文中未详细说明,属于MLLM的通用设置。
🖼️ 关键图片

📊 实验亮点
实验结果表明,MLLM能够利用组合泛化(CG)来理解未见过的医学影像,并且CG是多任务训练中观察到的泛化的主要驱动因素之一。此外,研究还证实CG能够有效支持数据有限的数据集,并且MLLM可以在分类和检测任务中实现CG,突显了其更广泛的泛化潜力。具体的性能数据和提升幅度在摘要中未明确给出。
🎯 应用场景
该研究成果可应用于提升医学影像辅助诊断的准确性和效率,尤其是在数据稀缺或存在新的影像模态、解剖区域或诊断任务时。通过理解MLLM的组合泛化能力,可以更好地设计模型和训练策略,使其能够更好地适应新的医学影像场景,从而为临床医生提供更可靠的决策支持。
📄 摘要(原文)
Medical imaging provides essential visual insights for diagnosis, and multimodal large language models (MLLMs) are increasingly utilized for its analysis due to their strong generalization capabilities; however, the underlying factors driving this generalization remain unclear. Current research suggests that multi-task training outperforms single-task as different tasks can benefit each other, but they often overlook the internal relationships within these tasks. To analyze this phenomenon, we attempted to employ compositional generalization (CG), which refers to the models' ability to understand novel combinations by recombining learned elements, as a guiding framework. Since medical images can be precisely defined by Modality, Anatomical area, and Task, naturally providing an environment for exploring CG, we assembled 106 medical datasets to create Med-MAT for comprehensive experiments. The experiments confirmed that MLLMs can use CG to understand unseen medical images and identified CG as one of the main drivers of the generalization observed in multi-task training. Additionally, further studies demonstrated that CG effectively supports datasets with limited data and confirmed that MLLMs can achieve CG across classification and detection tasks, underscoring its broader generalization potential. Med-MAT is available at https://github.com/FreedomIntelligence/Med-MAT.