VELoRA: A Low-Rank Adaptation Approach for Efficient RGB-Event based Recognition
作者: Lan Chen, Haoxiang Yang, Pengpeng Shao, Haoyu Song, Xiao Wang, Zhicheng Zhao, Yaowei Wang, Yonghong Tian
分类: cs.CV, cs.AI, cs.NE
发布日期: 2024-12-28
备注: In Peer Review
🔗 代码/项目: GITHUB
💡 一句话要点
提出VELoRA,一种基于低秩自适应的高效RGB-Event识别方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: RGB-Event识别 参数高效微调 低秩自适应 多模态融合 视觉基础模型 ViT 运动信息
📋 核心要点
- 现有方法难以高效地将大型预训练模型应用于RGB-Event识别,完全微调成本高昂。
- VELoRA采用模态特定和模态共享的LoRA微调策略,有效利用RGB和Event数据,降低计算成本。
- 实验结果表明,VELoRA能够在RGB-Event识别任务上实现高效的性能提升,优于现有方法。
📝 摘要(中文)
本文提出了一种新颖的参数高效微调(PEFT)策略VELoRA,用于RGB-Event融合的模式识别,旨在将预训练的视觉基础模型适配到RGB-Event分类任务中。该方法利用视觉基础模型ViT提取RGB帧和事件流的特征,并采用模态特定的LoRA微调策略。同时,考虑双模态的帧间差异,通过帧差骨干网络捕获运动线索。这些特征被拼接后输入到高层Transformer层,通过模态共享的LoRA微调进行高效的多模态特征学习。最后,将这些特征拼接并输入到分类头中,实现高效的微调。代码和预训练模型将在GitHub上发布。
🔬 方法详解
问题定义:RGB-Event识别旨在融合RGB图像和Event数据的信息,以提高识别准确率和鲁棒性。然而,直接对大型预训练模型进行全参数微调计算成本高昂,难以部署。现有的轻量级微调方法(如Adapter)在RGB-Event识别上的效果有待提升。
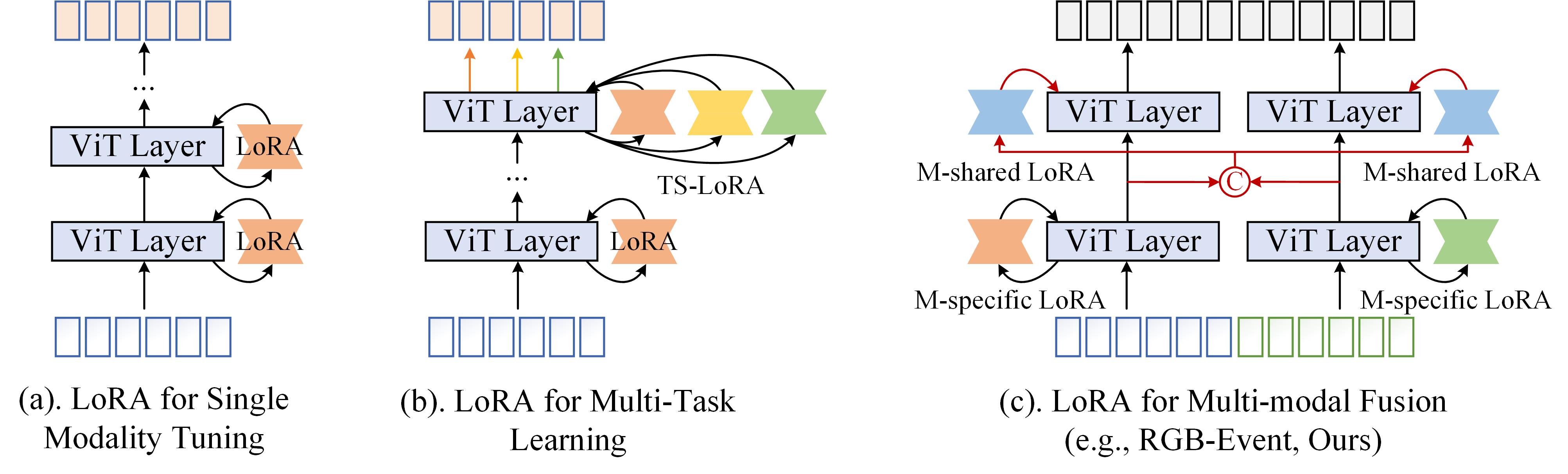
核心思路:VELoRA的核心思路是利用低秩自适应(LoRA)方法,在预训练的视觉基础模型上进行参数高效的微调。通过在模型的特定层中引入低秩矩阵,只训练少量参数,从而降低计算成本,同时保持模型的性能。针对RGB和Event两种模态,采用不同的LoRA策略,以适应各自的特点。
技术框架:VELoRA的整体框架包括以下几个主要模块:1) RGB和Event特征提取:使用预训练的ViT模型分别提取RGB帧和Event流的特征。2) 模态特定LoRA微调:对ViT模型的特定层进行LoRA微调,以适应RGB和Event两种模态的特点。3) 帧差特征提取:计算RGB和Event的帧间差异,并使用帧差骨干网络提取运动线索。4) 多模态特征融合:将RGB、Event和帧差特征拼接,并输入到高层Transformer层进行融合。5) 模态共享LoRA微调:对Transformer层进行LoRA微调,以学习多模态特征的交互。6) 分类头:将融合后的特征输入到分类头进行分类。
关键创新:VELoRA的关键创新在于:1) 首次将参数高效微调(PEFT)方法应用于RGB-Event识别。2) 提出了模态特定和模态共享的LoRA微调策略,充分利用了RGB和Event两种模态的信息。3) 考虑了帧间差异,提取了运动线索,进一步提高了识别准确率。
关键设计:VELoRA的关键设计包括:1) 选择ViT作为视觉基础模型,利用其强大的特征提取能力。2) 使用LoRA进行参数高效微调,降低计算成本。3) 设计了模态特定和模态共享的LoRA策略,以适应RGB和Event两种模态的特点。4) 引入帧差特征,提取运动线索。5) 使用Transformer层进行多模态特征融合,学习模态间的交互。
🖼️ 关键图片
📊 实验亮点
论文通过实验验证了VELoRA的有效性。实验结果表明,VELoRA在RGB-Event识别任务上取得了显著的性能提升,相比于全参数微调,VELoRA能够以更低的计算成本达到相近甚至更好的性能。具体的性能数据和对比基线将在论文中详细展示。
🎯 应用场景
VELoRA可应用于自动驾驶、机器人导航、视频监控等领域。在这些场景中,RGB相机提供纹理信息,Event相机提供高动态范围和低延迟的运动信息。VELoRA能够高效地融合这两种模态的信息,提高识别准确率和鲁棒性,从而提升系统的性能和安全性。未来,VELoRA有望在更多多模态感知任务中发挥作用。
📄 摘要(原文)
Pattern recognition leveraging both RGB and Event cameras can significantly enhance performance by deploying deep neural networks that utilize a fine-tuning strategy. Inspired by the successful application of large models, the introduction of such large models can also be considered to further enhance the performance of multi-modal tasks. However, fully fine-tuning these models leads to inefficiency and lightweight fine-tuning methods such as LoRA and Adapter have been proposed to achieve a better balance between efficiency and performance. To our knowledge, there is currently no work that has conducted parameter-efficient fine-tuning (PEFT) for RGB-Event recognition based on pre-trained foundation models. To address this issue, this paper proposes a novel PEFT strategy to adapt the pre-trained foundation vision models for the RGB-Event-based classification. Specifically, given the RGB frames and event streams, we extract the RGB and event features based on the vision foundation model ViT with a modality-specific LoRA tuning strategy. The frame difference of the dual modalities is also considered to capture the motion cues via the frame difference backbone network. These features are concatenated and fed into high-level Transformer layers for efficient multi-modal feature learning via modality-shared LoRA tuning. Finally, we concatenate these features and feed them into a classification head to achieve efficient fine-tuning. The source code and pre-trained models will be released on \url{https://github.com/Event-AHU/VELoRA}.