MVTamperBench: Evaluating Robustness of Vision-Language Models
作者: Amit Agarwal, Srikant Panda, Angeline Charles, Bhargava Kumar, Hitesh Patel, Priyaranjan Pattnayak, Taki Hasan Rafi, Tejaswini Kumar, Hansa Meghwani, Karan Gupta, Dong-Kyu Chae
分类: cs.CV
发布日期: 2024-12-27 (更新: 2025-06-11)
🔗 代码/项目: HUGGINGFACE | PROJECT_PAGE
💡 一句话要点
MVTamperBench:评估视觉-语言模型对抗视频篡改的鲁棒性
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频篡改检测 多模态大语言模型 鲁棒性评估 基准测试 对抗攻击
📋 核心要点
- 现有的多模态大语言模型在视频理解方面取得了进展,但对对抗性视频篡改的鲁棒性研究不足。
- MVTamperBench通过系统评估模型对旋转、掩蔽等五种篡改技术的抵抗能力,填补了这一空白。
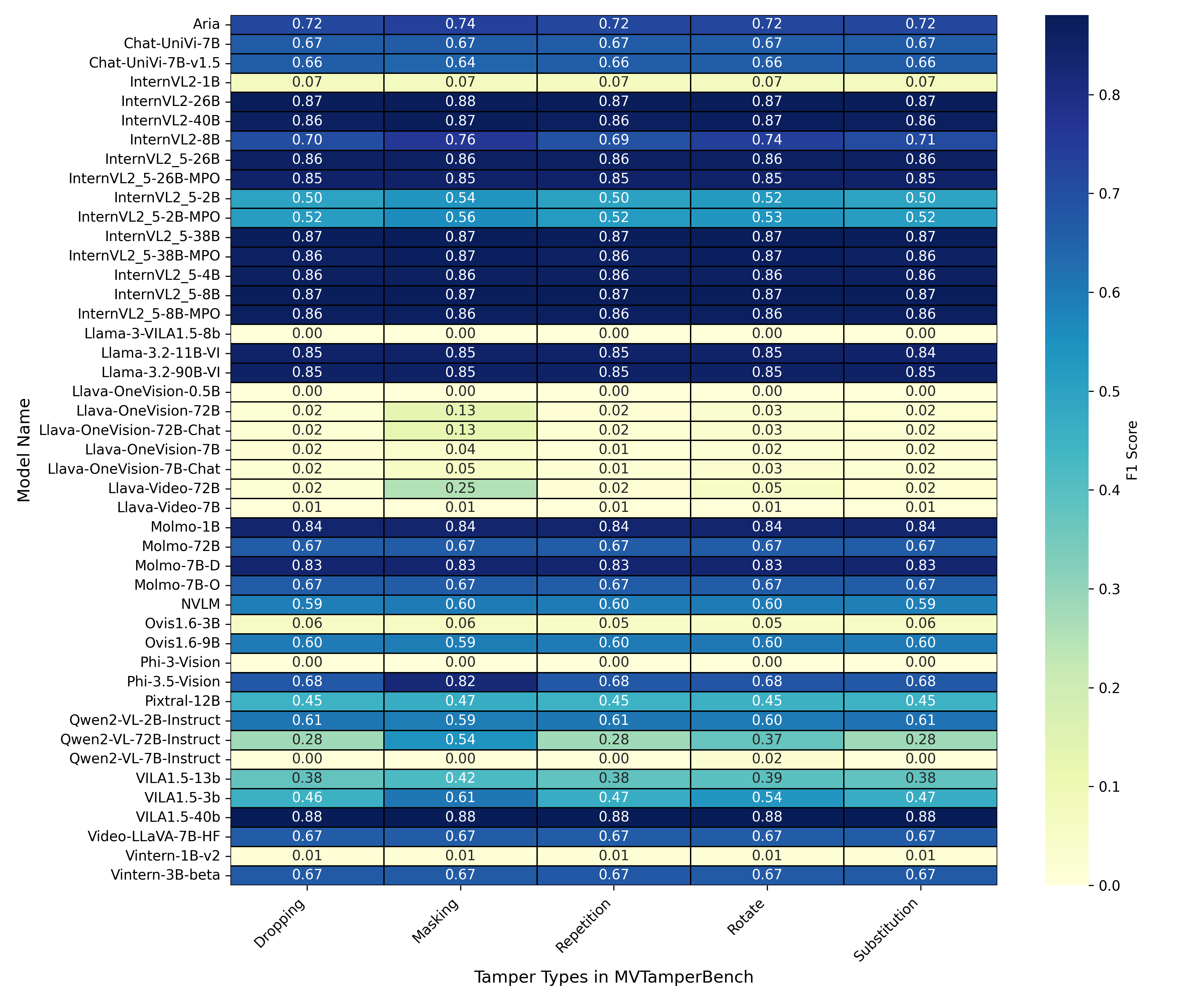
- 实验结果表明,模型在不同篡改类型上的鲁棒性差异显著,且参数量大的模型不一定更鲁棒。
📝 摘要(中文)
多模态大型语言模型(MLLM)是视觉-语言模型(VLM)的最新进展,推动了视频理解的重大进步。然而,它们对对抗性篡改和操纵的脆弱性仍未得到充分探索。为了解决这一差距,我们引入了MVTamperBench,这是一个基准,系统地评估MLLM对五种常见篡改技术的鲁棒性:旋转、掩蔽、替换、重复和删除;这些技术基于现实世界的视觉篡改场景,如监控干扰、社交媒体内容编辑和错误信息注入。MVTamperBench包含约3.4K个原始视频,扩展到超过17K个篡改片段,涵盖19个不同的视频操纵任务。该基准测试挑战模型检测空间和时间连贯性中的操纵。我们评估了来自15+个模型系列的45个最新的MLLM。我们揭示了不同篡改类型之间的弹性存在显著差异,并表明更大的参数数量并不一定保证鲁棒性。MVTamperBench为开发安全关键应用中具有防篡改能力的MLLM设定了一个新的基准,包括检测点击诱饵、防止有害内容传播以及执行媒体平台上的策略。我们发布所有代码、数据和基准,以促进可信视频理解方面的开放研究。
🔬 方法详解
问题定义:论文旨在解决多模态大型语言模型(MLLM)在面对恶意视频篡改时的脆弱性问题。现有方法缺乏对MLLM鲁棒性的系统性评估,无法有效应对现实世界中日益复杂的视频篡改手段,例如社交媒体上的恶意编辑、监控视频的干扰等。这些篡改可能导致模型产生错误的理解和判断,从而带来安全风险。
核心思路:论文的核心思路是构建一个全面的基准测试集MVTamperBench,包含多种类型的视频篡改,并利用该基准系统性地评估现有MLLM的鲁棒性。通过分析模型在不同篡改类型下的表现,揭示其弱点,从而为开发更具鲁棒性的MLLM提供指导。
技术框架:MVTamperBench的整体框架包括以下几个主要步骤:1) 收集原始视频数据;2) 应用五种主要的视频篡改技术(旋转、掩蔽、替换、重复和删除)生成篡改后的视频;3) 构建包含原始视频和篡改视频的基准测试集;4) 选择多个代表性的MLLM进行评估;5) 分析评估结果,揭示模型在不同篡改类型下的鲁棒性表现。
关键创新:该论文的关键创新在于:1) 提出了一个专门用于评估MLLM视频篡改鲁棒性的基准测试集MVTamperBench,填补了该领域的空白;2) 系统性地研究了五种常见的视频篡改技术对MLLM的影响,揭示了模型在不同篡改类型下的脆弱性;3) 评估了大量MLLM,并发现模型大小与鲁棒性之间没有必然联系。
关键设计:MVTamperBench包含3.4K个原始视频,并扩展到超过17K个篡改后的视频片段,涵盖19个不同的视频操纵任务。五种篡改技术分别模拟了不同的现实场景:旋转模拟摄像头角度变化,掩蔽模拟遮挡,替换模拟内容替换,重复模拟信息重复,删除模拟信息丢失。论文没有特别提及损失函数或网络结构的修改,而是侧重于基准测试集的构建和评估。
🖼️ 关键图片

📊 实验亮点
实验结果表明,现有MLLM在面对视频篡改时表现出显著的脆弱性。例如,某些模型在旋转篡改下的准确率大幅下降。此外,研究发现模型参数量的大小与鲁棒性之间没有直接关系,即更大的模型并不一定更鲁棒。MVTamperBench的评估结果为后续研究提供了重要的参考。
🎯 应用场景
该研究成果可应用于多个领域,包括:1) 检测社交媒体上的恶意编辑和虚假信息;2) 提高监控系统的安全性,防止篡改后的视频被用于非法目的;3) 增强自动驾驶系统的鲁棒性,使其能够识别被篡改的交通标志和道路信息。该研究为开发更安全、更可靠的视频理解系统奠定了基础。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs), are recent advancement of Vision-Language Models (VLMs) that have driven major advances in video understanding. However, their vulnerability to adversarial tampering and manipulations remains underexplored. To address this gap, we introduce \textbf{MVTamperBench}, a benchmark that systematically evaluates MLLM robustness against five prevalent tampering techniques: rotation, masking, substitution, repetition, and dropping; based on real-world visual tampering scenarios such as surveillance interference, social media content edits, and misinformation injection. MVTamperBench comprises ~3.4K original videos, expanded into over ~17K tampered clips covering 19 distinct video manipulation tasks. This benchmark challenges models to detect manipulations in spatial and temporal coherence. We evaluate 45 recent MLLMs from 15+ model families. We reveal substantial variability in resilience across tampering types and show that larger parameter counts do not necessarily guarantee robustness. MVTamperBench sets a new benchmark for developing tamper-resilient MLLM in safety-critical applications, including detecting clickbait, preventing harmful content distribution, and enforcing policies on media platforms. We release all code, data, and benchmark to foster open research in trustworthy video understanding. Code: https://amitbcp.github.io/MVTamperBench/ Data: https://huggingface.co/datasets/Srikant86/MVTamperBench