A Large-scale Interpretable Multi-modality Benchmark for Facial Image Forgery Localization
作者: Jingchun Lian, Lingyu Liu, Yaxiong Wang, Yujiao Wu, Li Zhu, Zhedong Zheng
分类: cs.CV, cs.AI
发布日期: 2024-12-27
备注: 10 pages, 4 figures, 4 tabels
💡 一句话要点
提出MMTT数据集和ForgeryTalker模型,用于可解释的面部伪造图像定位。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图像伪造定位 多模态学习 可解释性AI 深度伪造检测 文本解释 MMTT数据集 ForgeryTalker
📋 核心要点
- 现有伪造图像定位方法依赖二元分割掩码,缺乏对模型预测的解释性,无法区分不同伪造区域的逼真程度。
- 提出MMTT数据集和ForgeryTalker模型,通过图像-文本对的方式,为伪造区域提供显著区域的解释,提升模型的可解释性。
- 实验结果表明,ForgeryTalker模型在MMTT数据集上表现优异,验证了其在伪造定位和解释方面的有效性。
📝 摘要(中文)
图像伪造定位旨在识别图像中被篡改的像素,并取得了显著进展。传统方法通常将其建模为图像分割的变体,将伪造区域的二元分割作为最终结果。本文认为,基本的二元伪造掩码不足以解释模型预测,无法阐明模型为何定位某些区域,并且对所有伪造像素一视同仁,难以发现最逼真的伪造部分。为了解决这些局限性,本文为伪造图像生成了以显著区域为中心的解释。为此,构建了一个多模态篡改追踪(MMTT)数据集,包含使用深度伪造技术操纵的面部图像,并配有手动、可解释的文本注释。为了获得高质量的注释,注释员被要求仔细观察被操纵的图像,并阐明伪造区域的典型特征。最终收集了包含128,303个图像-文本对的数据集。利用MMTT数据集,开发了ForgeryTalker,一种用于并发伪造定位和解释的架构。ForgeryTalker首先训练一个伪造提示器网络来识别解释性文本中的关键线索。随后,将区域提示器整合到多模态大型语言模型中进行微调,以实现定位和解释的双重目标。在MMTT数据集上进行的大量实验验证了所提出的模型的优越性能。数据集、代码和预训练检查点将公开提供,以促进进一步的研究并确保结果的可重复性。
🔬 方法详解
问题定义:现有图像伪造定位方法主要依赖于二元分割掩码,仅仅标注了图像中哪些像素被篡改,而忽略了为什么这些区域被认为是伪造的,以及不同伪造区域的逼真程度差异。这种缺乏解释性的方法限制了模型的可信度和泛化能力。
核心思路:本文的核心思路是通过引入文本描述,为伪造区域提供更丰富的解释信息。通过让模型同时学习定位伪造区域和生成相应的文本描述,可以提高模型对伪造特征的理解,从而提升定位的准确性和可解释性。
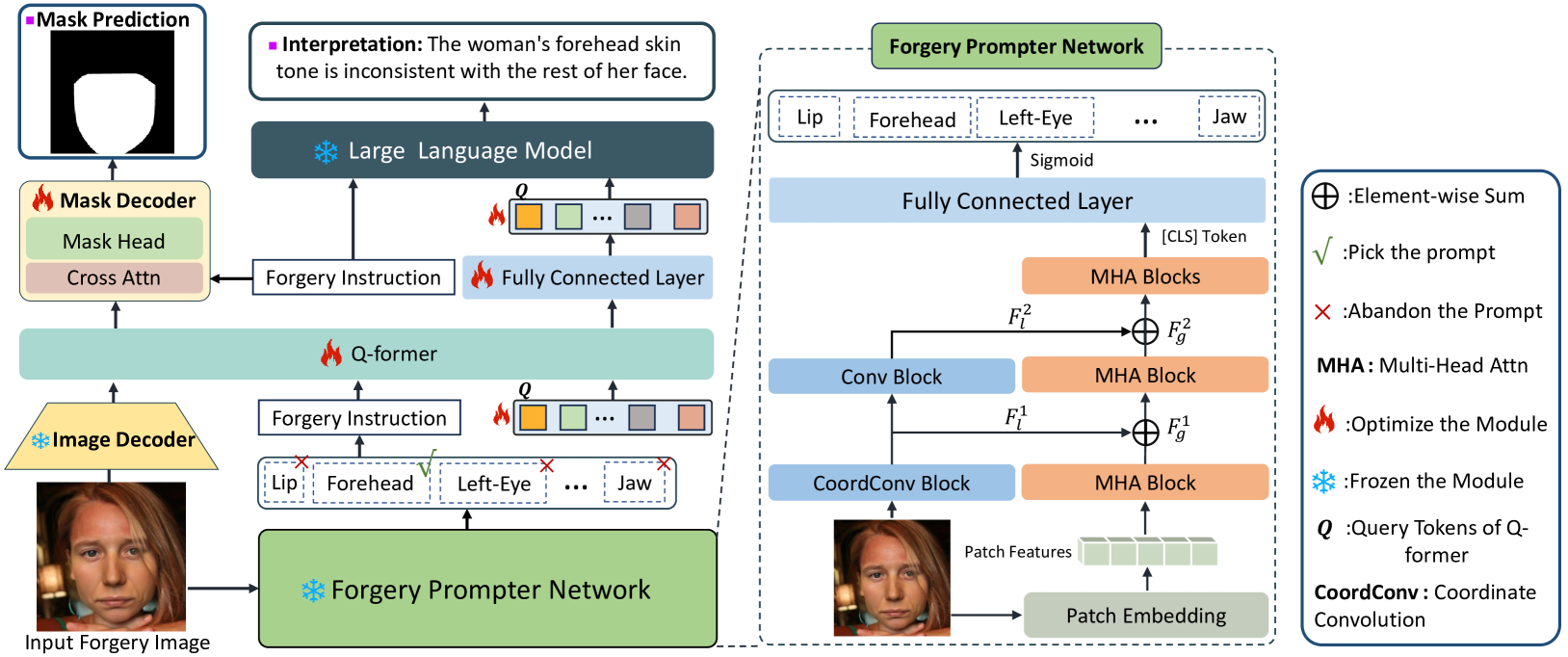
技术框架:ForgeryTalker模型的整体架构包含以下几个主要模块:1) MMTT数据集:包含伪造面部图像和对应的文本描述,文本描述详细解释了图像中伪造区域的特征。2) 伪造提示器网络:用于从文本描述中提取关键线索,生成伪造提示。3) 区域提示器:将伪造提示融入到多模态大型语言模型中。4) 多模态大型语言模型:经过微调后,可以同时进行伪造区域的定位和文本描述的生成。
关键创新:本文最重要的技术创新点在于将文本解释融入到图像伪造定位任务中,从而提升模型的可解释性。通过多模态学习,模型不仅可以定位伪造区域,还可以生成相应的文本描述,解释为什么这些区域被认为是伪造的。这与传统的二元分割方法有本质区别。
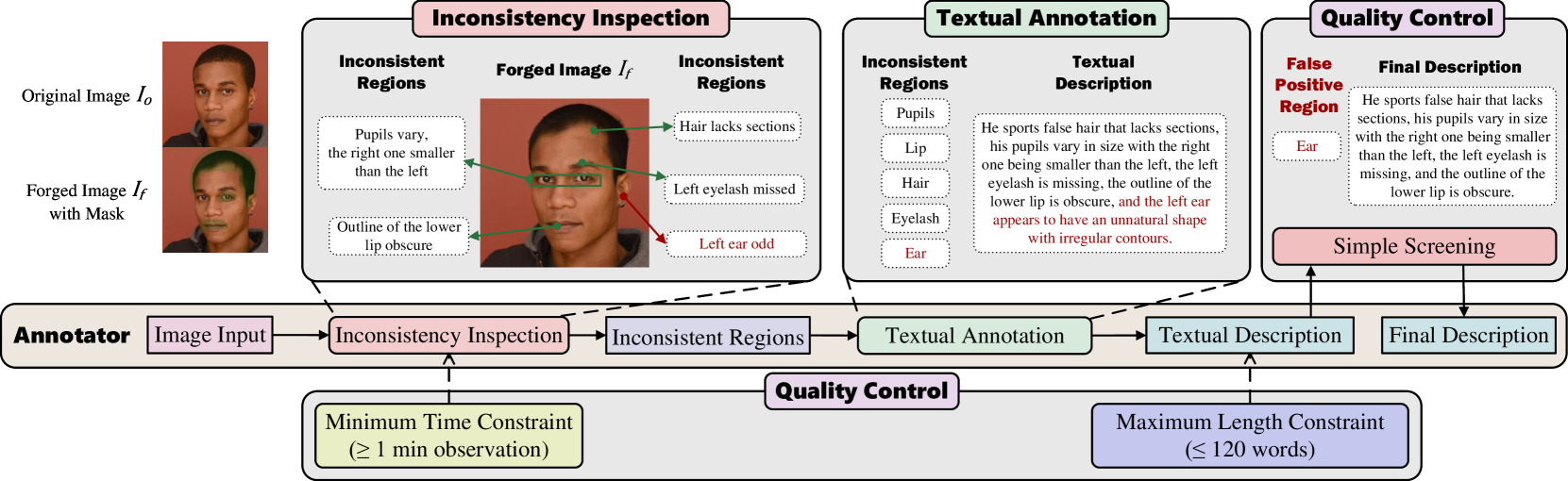
关键设计:MMTT数据集的设计至关重要,高质量的文本描述是模型学习的关键。ForgeryTalker模型利用伪造提示器网络从文本描述中提取关键线索,并将其融入到多模态大型语言模型中。具体的损失函数设计和网络结构细节在论文中有详细描述(未知)。
🖼️ 关键图片
📊 实验亮点
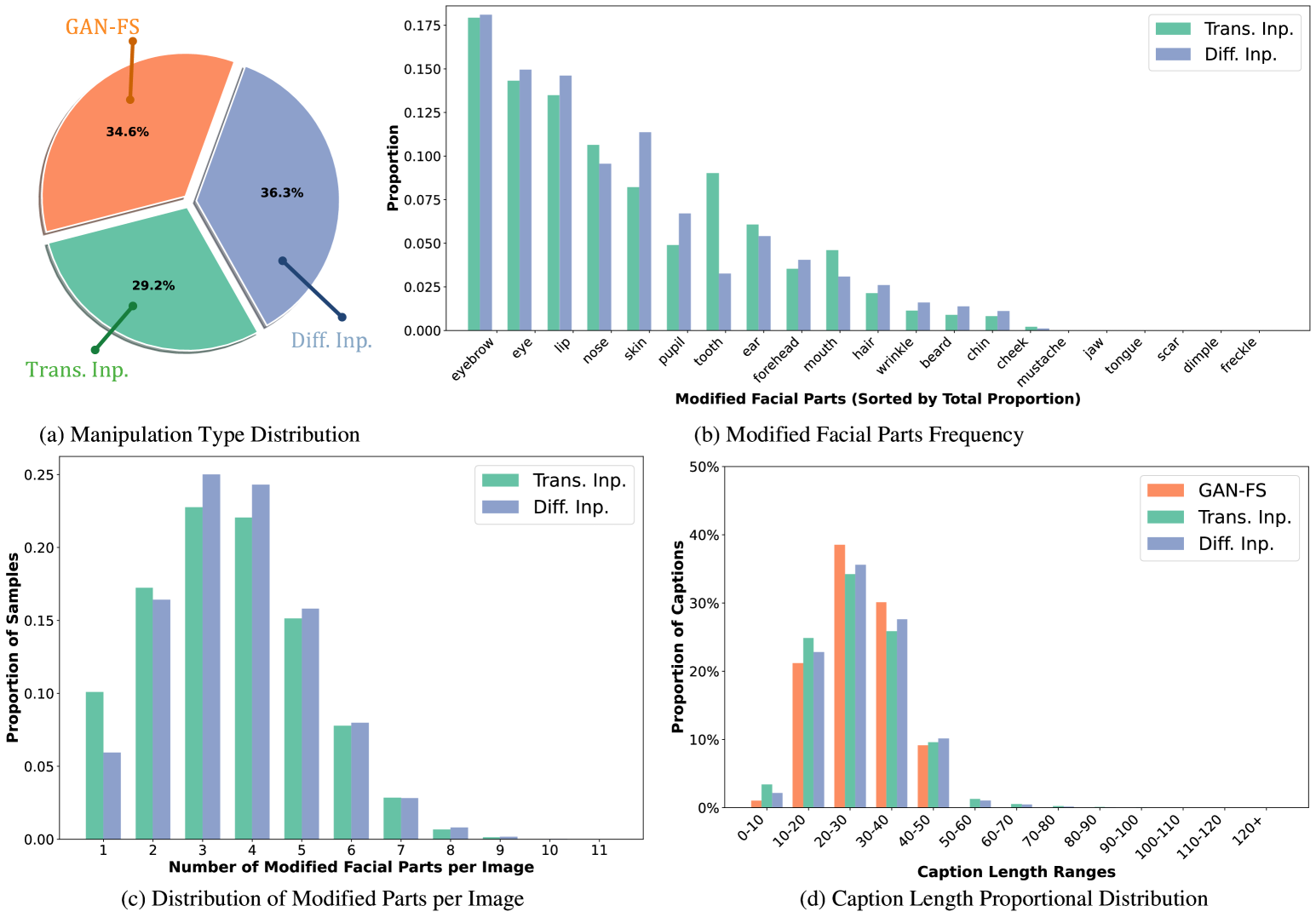
实验结果表明,ForgeryTalker模型在MMTT数据集上取得了优异的性能。通过与现有方法的对比,验证了ForgeryTalker模型在伪造定位和解释方面的有效性。具体的性能数据和提升幅度在论文中有详细描述(未知)。
🎯 应用场景
该研究成果可应用于数字取证、社交媒体内容审核、金融安全等领域。通过提高伪造图像定位的准确性和可解释性,可以帮助识别和防止恶意伪造行为,维护网络安全和社会稳定。未来,该技术还可以扩展到其他类型的图像伪造检测,例如视频伪造检测。
📄 摘要(原文)
Image forgery localization, which centers on identifying tampered pixels within an image, has seen significant advancements. Traditional approaches often model this challenge as a variant of image segmentation, treating the binary segmentation of forged areas as the end product. We argue that the basic binary forgery mask is inadequate for explaining model predictions. It doesn't clarify why the model pinpoints certain areas and treats all forged pixels the same, making it hard to spot the most fake-looking parts. In this study, we mitigate the aforementioned limitations by generating salient region-focused interpretation for the forgery images. To support this, we craft a Multi-Modal Tramper Tracing (MMTT) dataset, comprising facial images manipulated using deepfake techniques and paired with manual, interpretable textual annotations. To harvest high-quality annotation, annotators are instructed to meticulously observe the manipulated images and articulate the typical characteristics of the forgery regions. Subsequently, we collect a dataset of 128,303 image-text pairs. Leveraging the MMTT dataset, we develop ForgeryTalker, an architecture designed for concurrent forgery localization and interpretation. ForgeryTalker first trains a forgery prompter network to identify the pivotal clues within the explanatory text. Subsequently, the region prompter is incorporated into multimodal large language model for finetuning to achieve the dual goals of localization and interpretation. Extensive experiments conducted on the MMTT dataset verify the superior performance of our proposed model. The dataset, code as well as pretrained checkpoints will be made publicly available to facilitate further research and ensure the reproducibility of our results.