MBQ: Modality-Balanced Quantization for Large Vision-Language Models
作者: Shiyao Li, Yingchun Hu, Xuefei Ning, Xihui Liu, Ke Hong, Xiaotao Jia, Xiuhong Li, Yaqi Yan, Pei Ran, Guohao Dai, Shengen Yan, Huazhong Yang, Yu Wang
分类: cs.CV, cs.AI
发布日期: 2024-12-27 (更新: 2025-03-21)
🔗 代码/项目: GITHUB
💡 一句话要点
提出模态平衡量化(MBQ)方法,提升大视觉-语言模型量化后的精度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 后训练量化 模型压缩 模态平衡 低比特量化
📋 核心要点
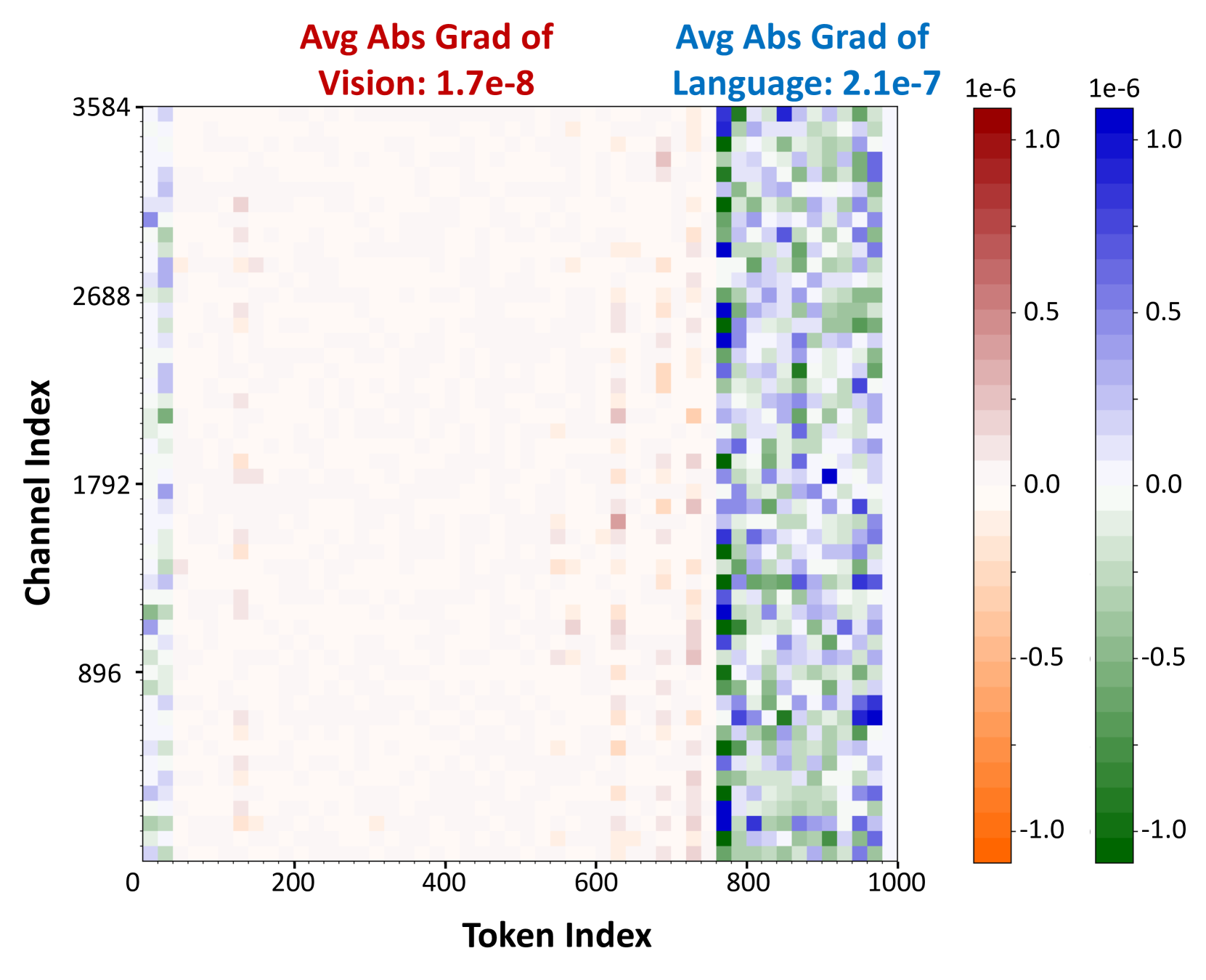
- 现有PTQ方法在量化视觉-语言模型时,忽略了视觉和语言模态token敏感度的差异,导致精度损失。
- MBQ方法通过在校准过程中考虑不同模态的敏感度,最小化重建损失,从而优化量化参数。
- 实验结果表明,MBQ在多种VLM模型上显著提升了量化后的精度,并实现了GPU加速。
📝 摘要(中文)
视觉-语言模型(VLM)在现实世界中有着广泛的应用。然而,VLM庞大的参数规模带来了巨大的内存和计算开销,给部署带来了严峻的挑战。后训练量化(PTQ)是一种有效的降低内存和计算开销的技术。现有的PTQ方法主要集中在大型语言模型(LLM)上,没有考虑到不同模态之间的差异。本文发现,大型VLM中语言和视觉token的敏感度存在显著差异。因此,像现有的PTQ方法那样平等地对待来自不同模态的token,可能会过度强调不敏感的模态,从而导致显著的精度损失。为了解决上述问题,我们为大型VLM提出了一种简单而有效的方法,即模态平衡量化(MBQ)。具体来说,MBQ在校准过程中考虑了不同模态之间的不同敏感度,以最小化重建损失,从而获得更好的量化参数。大量的实验表明,与SOTA基线相比,MBQ可以在7B到70B的VLM的W3和W4A8量化下显著提高任务精度,分别高达4.4%和11.6%。此外,我们实现了一个W3 GPU内核,它融合了解量化和GEMV算子,在RTX 4090上的LLaVA-onevision-7B上实现了1.4倍的加速。代码可在https://github.com/thu-nics/MBQ 获取。
🔬 方法详解
问题定义:现有后训练量化(PTQ)方法在压缩大型视觉-语言模型(VLM)时,通常平等对待来自不同模态(视觉和语言)的token。然而,不同模态的token对量化误差的敏感度存在显著差异,忽略这种差异会导致对不敏感模态的过度强调,从而造成显著的精度损失。
核心思路:MBQ的核心思路是根据不同模态的敏感度,在量化过程中进行平衡。通过在校准阶段引入模态敏感度信息,调整量化参数,使得对敏感模态的量化误差最小化,从而提升整体的量化精度。这种方法避免了对所有模态采用统一的量化策略,更加精细化地处理不同模态的量化需求。
技术框架:MBQ方法主要包含以下几个阶段:1) 确定视觉和语言模态的敏感度差异。2) 在PTQ的校准阶段,利用模态敏感度信息调整量化参数。3) 使用调整后的量化参数对VLM进行量化。4) (可选) 实现定制化的GPU kernel以加速量化后的模型推理。整体流程是在标准PTQ流程的基础上,增加了模态敏感度分析和参数调整环节。
关键创新:MBQ最关键的创新在于它意识到了VLM中不同模态token的敏感度差异,并将其纳入到量化过程中。与现有PTQ方法平等对待所有token不同,MBQ通过模态平衡的方式,更加有效地利用了量化比特,从而在相同的量化比特数下实现了更高的精度。
关键设计:MBQ的关键设计在于如何有效地将模态敏感度信息融入到PTQ的校准过程中。具体实现细节可能包括:1) 使用某种指标(例如重建误差)来衡量不同模态的敏感度。2) 设计一种损失函数,该损失函数能够根据模态敏感度调整量化参数。3) 针对量化后的模型,设计高效的GPU kernel,例如融合解量化和GEMV操作,以加速推理。
🖼️ 关键图片
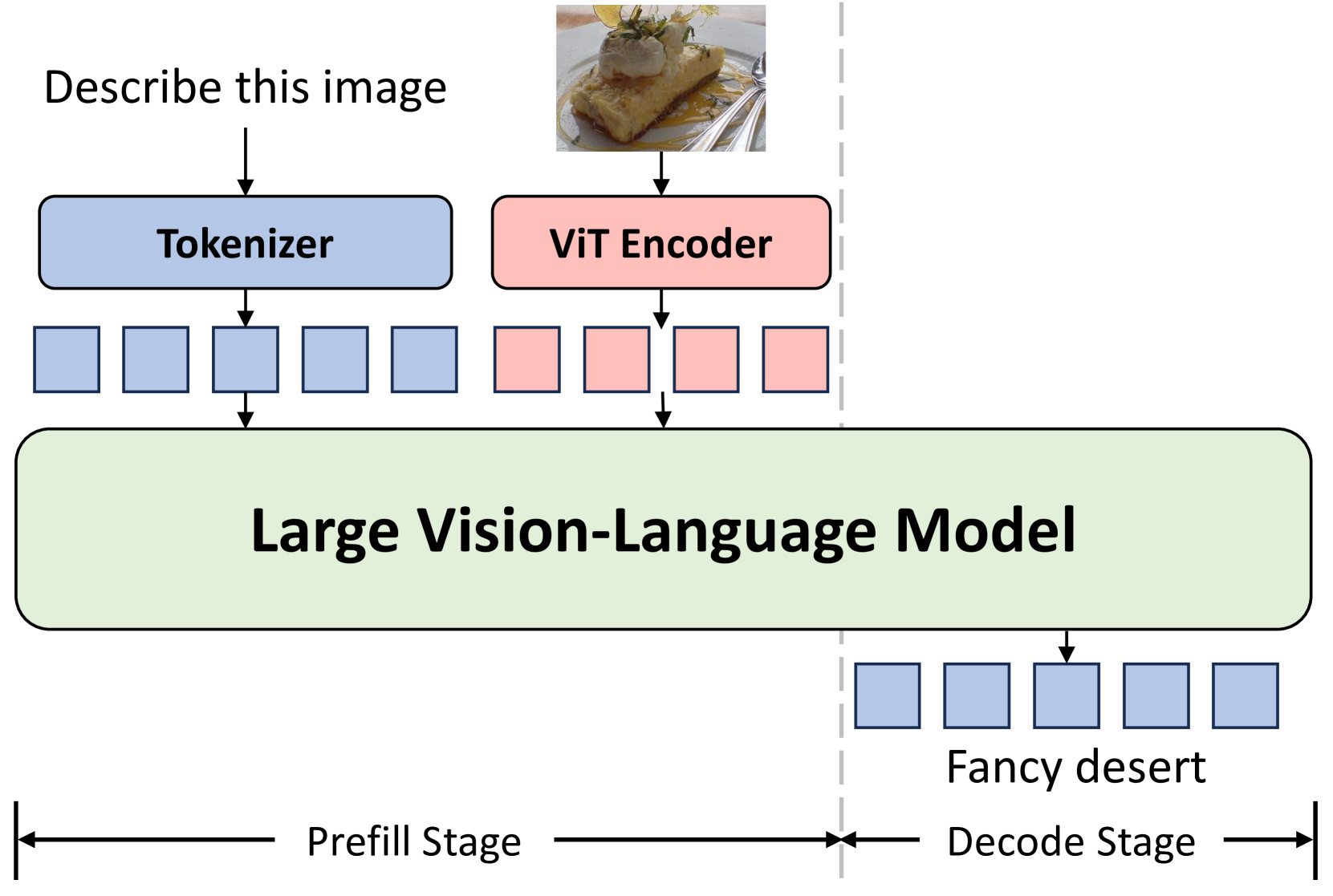
📊 实验亮点
MBQ在7B到70B的VLM模型上进行了广泛的实验,结果表明,在W3和W4A8量化下,MBQ相比SOTA基线方法,任务精度分别提升了高达4.4%和11.6%。此外,通过实现一个融合了解量化和GEMV算子的W3 GPU kernel,MBQ在RTX 4090上的LLaVA-onevision-7B模型上实现了1.4倍的加速。
🎯 应用场景
MBQ方法可以应用于各种需要部署大型视觉-语言模型的场景,例如移动设备、边缘计算设备等。通过降低模型的内存占用和计算开销,MBQ使得这些设备能够运行更加复杂的VLM模型,从而实现更智能的视觉和语言理解能力。该方法还可以应用于云计算平台,降低VLM的部署成本,提高服务效率。
📄 摘要(原文)
Vision-Language Models (VLMs) have enabled a variety of real-world applications. The large parameter size of VLMs brings large memory and computation overhead which poses significant challenges for deployment. Post-Training Quantization (PTQ) is an effective technique to reduce the memory and computation overhead. Existing PTQ methods mainly focus on large language models (LLMs), without considering the differences across other modalities. In this paper, we discover that there is a significant difference in sensitivity between language and vision tokens in large VLMs. Therefore, treating tokens from different modalities equally, as in existing PTQ methods, may over-emphasize the insensitive modalities, leading to significant accuracy loss. To deal with the above issue, we propose a simple yet effective method, Modality-Balanced Quantization (MBQ), for large VLMs. Specifically, MBQ incorporates the different sensitivities across modalities during the calibration process to minimize the reconstruction loss for better quantization parameters. Extensive experiments show that MBQ can significantly improve task accuracy by up to 4.4% and 11.6% under W3 and W4A8 quantization for 7B to 70B VLMs, compared to SOTA baselines. Additionally, we implement a W3 GPU kernel that fuses the dequantization and GEMV operators, achieving a 1.4x speedup on LLaVA-onevision-7B on the RTX 4090. The code is available at https://github.com/thu-nics/MBQ.