Generalized Uncertainty-Based Evidential Fusion with Hybrid Multi-Head Attention for Weak-Supervised Temporal Action Localization
作者: Yuanpeng He, Lijian Li, Tianxiang Zhan, Wenpin Jiao, Chi-Man Pun
分类: cs.CV, cs.AI
发布日期: 2024-12-27
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于广义不确定性的证据融合与混合多头注意力机制,解决弱监督时序动作定位中的动作-背景混淆问题。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 弱监督学习 时序动作定位 多头注意力 证据融合 不确定性建模
📋 核心要点
- 现有WS-TAL方法受限于动作-背景混淆,难以准确区分动作实例与背景噪声。
- 提出HMHA与GUEF模块,分别增强特征表达和自适应消除背景噪声,提升定位精度。
- 在THUMOS14数据集上的实验结果表明,该方法优于现有技术水平。
📝 摘要(中文)
本文针对弱监督时序动作定位(WS-TAL)任务中,由于聚合和动作内部差异导致的背景噪声引起的动作-背景混淆问题,提出了一种混合多头注意力(HMHA)模块和广义不确定性证据融合(GUEF)模块。HMHA通过过滤冗余信息并调整特征分布,有效地增强了RGB和光流特征,使其更好地适应WS-TAL任务。此外,GUEF通过融合片段级别的证据来优化不确定性度量,并选择更优的前景特征信息,从而自适应地消除背景噪声的干扰,使模型能够专注于完整的动作实例,从而获得更好的动作定位和分类性能。在THUMOS14数据集上进行的实验结果表明,本文方法优于目前最先进的方法。代码已开源。
🔬 方法详解
问题定义:弱监督时序动作定位(WS-TAL)旨在仅利用视频级别的标签来定位视频中动作的起止时间和类别。现有方法的主要痛点在于动作-背景混淆,即模型难以区分真正的动作实例和背景噪声,这主要是由于视频片段的聚合以及动作内部的变化造成的。这种混淆导致模型无法准确地定位动作,降低了定位和分类的性能。
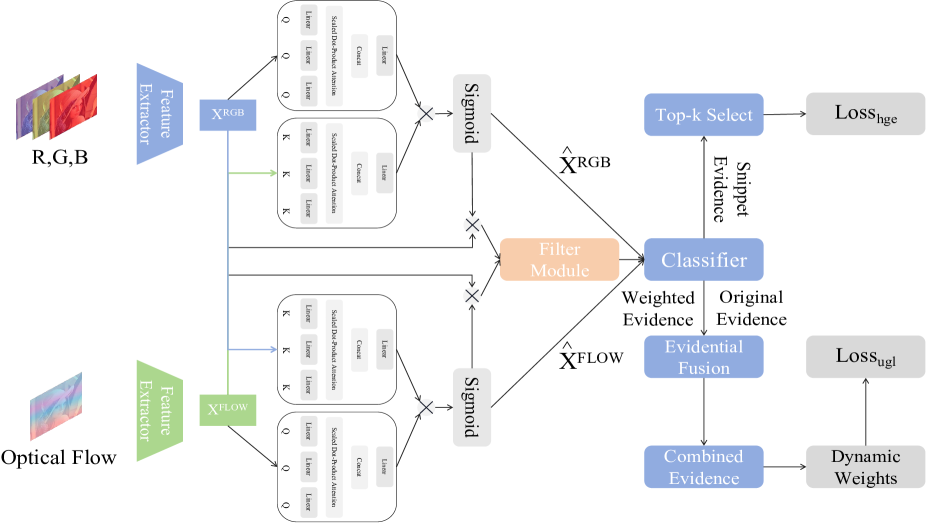
核心思路:本文的核心思路是通过增强特征表达和自适应地消除背景噪声来解决动作-背景混淆问题。具体来说,利用混合多头注意力(HMHA)模块来增强RGB和光流特征,使其更好地适应WS-TAL任务。同时,利用广义不确定性证据融合(GUEF)模块来融合片段级别的证据,优化不确定性度量,从而自适应地消除背景噪声的干扰。
技术框架:整体框架包含两个主要模块:HMHA和GUEF。首先,输入RGB和光流特征,通过HMHA模块进行特征增强,过滤冗余信息并调整特征分布。然后,将增强后的特征输入到GUEF模块中,该模块融合片段级别的证据,计算不确定性,并根据不确定性选择更优的前景特征信息。最后,利用选择后的特征进行动作定位和分类。
关键创新:本文的关键创新在于HMHA和GUEF模块的设计。HMHA模块通过混合不同类型的注意力机制,能够更有效地增强特征表达。GUEF模块则通过引入不确定性度量,能够自适应地消除背景噪声的干扰,从而提高定位精度。与现有方法相比,本文方法能够更有效地解决动作-背景混淆问题。
关键设计:HMHA模块采用了混合多头注意力机制,具体包括自注意力、交叉注意力和引导注意力。GUEF模块的关键在于不确定性的计算和融合策略,使用了证据理论来建模不确定性,并设计了一种广义的证据融合方法。损失函数方面,使用了分类损失和定位损失的加权和。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在THUMOS14数据集上取得了优于现有技术水平的性能。具体来说,该方法在平均精度均值(mAP)指标上取得了显著提升,表明其在动作定位和分类方面都具有优越的性能。相较于其他方法,该方法能够更准确地定位动作的起止时间,并更准确地对动作进行分类。
🎯 应用场景
该研究成果可应用于视频监控、智能安防、体育视频分析、自动驾驶等领域。通过精确定位视频中的动作,可以实现异常行为检测、运动员动作分析、交通事件识别等功能,具有重要的实际应用价值和广阔的应用前景。未来的研究可以进一步探索如何将该方法应用于更复杂的场景和更大规模的数据集。
📄 摘要(原文)
Weakly supervised temporal action localization (WS-TAL) is a task of targeting at localizing complete action instances and categorizing them with video-level labels. Action-background ambiguity, primarily caused by background noise resulting from aggregation and intra-action variation, is a significant challenge for existing WS-TAL methods. In this paper, we introduce a hybrid multi-head attention (HMHA) module and generalized uncertainty-based evidential fusion (GUEF) module to address the problem. The proposed HMHA effectively enhances RGB and optical flow features by filtering redundant information and adjusting their feature distribution to better align with the WS-TAL task. Additionally, the proposed GUEF adaptively eliminates the interference of background noise by fusing snippet-level evidences to refine uncertainty measurement and select superior foreground feature information, which enables the model to concentrate on integral action instances to achieve better action localization and classification performance. Experimental results conducted on the THUMOS14 dataset demonstrate that our method outperforms state-of-the-art methods. Our code is available in \url{https://github.com/heyuanpengpku/GUEF/tree/main}.