Task Preference Optimization: Improving Multimodal Large Language Models with Vision Task Alignment
作者: Ziang Yan, Zhilin Li, Yinan He, Chenting Wang, Kunchang Li, Xinhao Li, Xiangyu Zeng, Zilei Wang, Yali Wang, Yu Qiao, Limin Wang, Yi Wang
分类: cs.CV
发布日期: 2024-12-26 (更新: 2025-06-30)
备注: CVPR2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出任务偏好优化TPO,提升多模态大语言模型在视觉任务上的精细理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 视觉任务对齐 任务偏好优化 可学习任务Token 多任务协同训练
📋 核心要点
- 现有MLLM在视觉任务的精细理解上存在不足,限制了其在精确视觉应用中的表现。
- TPO通过引入可学习的任务token和任务特定头,利用可微任务偏好来优化MLLM在视觉任务上的表现。
- 实验表明,TPO在多模态性能上提升了14.6%,并在零样本任务中表现出与监督模型相当的性能。
📝 摘要(中文)
当前的多模态大语言模型(MLLMs)虽然在各种视觉应用中展现了全面的感知和推理能力,但在视觉的精细理解方面表现不佳。为了解决这个问题,并以可扩展的方式增强MLLMs的视觉任务能力,我们提出了任务偏好优化(TPO),这是一种利用从典型精细视觉任务中导出的可微任务偏好的新方法。TPO引入了可学习的任务token,用于建立多个特定任务头和MLLM之间的连接。通过在训练期间利用丰富的视觉标签,TPO显著增强了MLLM的多模态能力和特定任务的性能。通过TPO中的多任务协同训练,我们观察到协同效益,将单个任务的性能提升到超过单任务训练方法所能达到的水平。我们在VideoChat和LLaVA上的实验表明,与基线模型相比,多模态性能总体提高了14.6%。此外,MLLM-TPO在各种任务中表现出强大的零样本能力,与最先进的监督模型相当。
🔬 方法详解
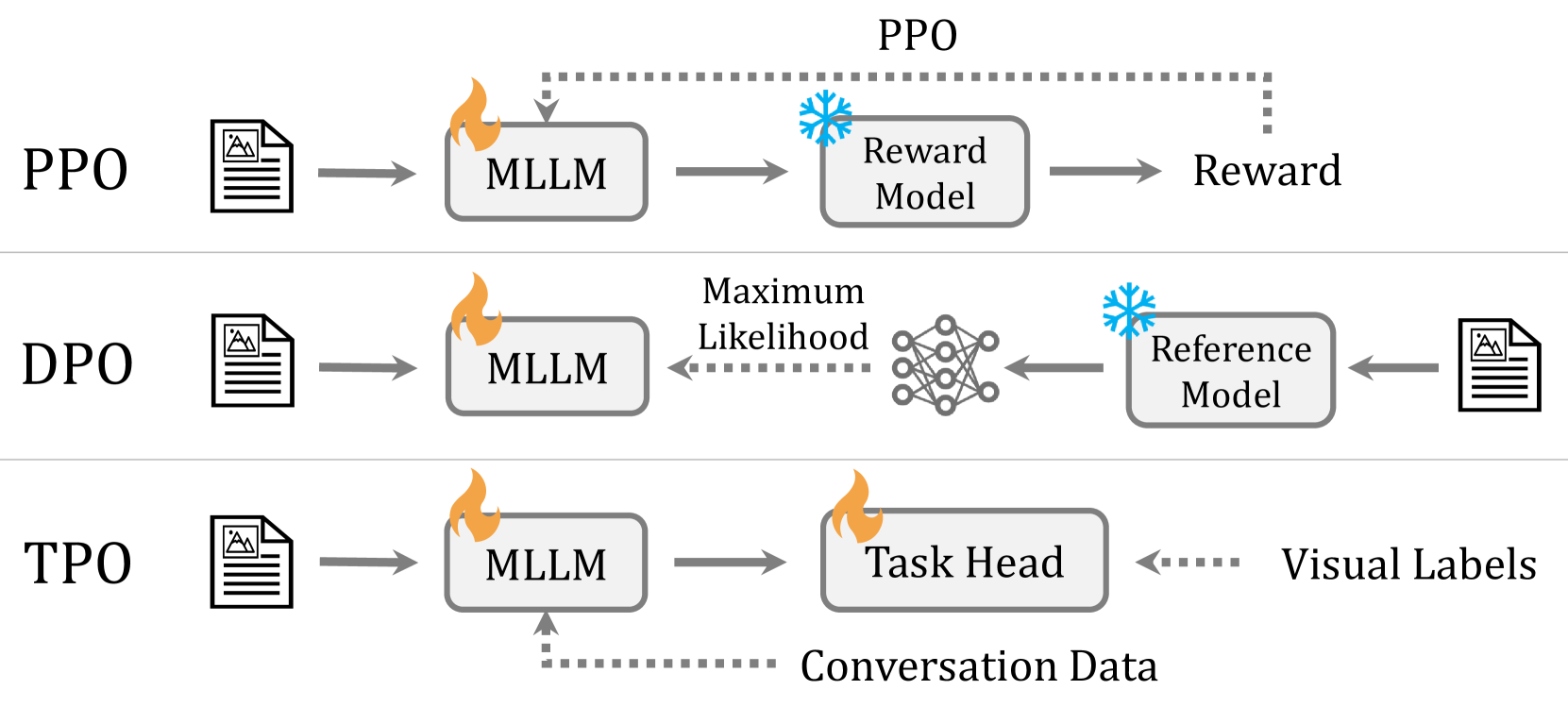
问题定义:当前的多模态大语言模型(MLLMs)在处理需要精细理解的视觉任务时表现不佳。虽然它们在广泛的视觉应用中展现了全面的感知和推理能力,但在需要精确识别、定位或理解图像细节的任务上,性能往往受到限制。现有的方法,如工具使用或将特定视觉任务统一到自回归框架中,通常会牺牲整体的多模态性能。因此,如何提升MLLMs在视觉任务上的精细理解能力,同时保持其通用性,是一个重要的挑战。
核心思路:TPO的核心思路是利用从典型精细视觉任务中提取的可微任务偏好来指导MLLM的训练。通过引入可学习的任务token,将不同的任务特定头与MLLM连接起来,使得模型能够根据任务的需求调整其内部表示。这种方法允许模型在多任务协同训练中学习到任务之间的关联,从而提升整体性能。
技术框架:TPO的技术框架主要包括以下几个模块:1) 多模态大语言模型(MLLM):作为基础模型,负责处理视觉和语言信息。2) 任务token:可学习的向量,用于表示不同的视觉任务。3) 任务特定头:针对特定视觉任务设计的输出层,例如目标检测头、图像分割头等。4) 任务偏好优化器:根据任务的损失函数,调整任务token和MLLM的参数,使得模型能够更好地完成任务。训练流程包括:输入图像和任务描述,任务token被注入到MLLM中,MLLM生成视觉表示,任务特定头根据视觉表示生成预测结果,计算损失函数,任务偏好优化器更新模型参数。
关键创新:TPO最重要的技术创新点在于引入了可学习的任务token和任务偏好优化机制。与以往的方法不同,TPO不是简单地将视觉任务添加到MLLM中,而是通过学习任务之间的关系,使得模型能够更好地适应不同的任务需求。这种方法具有更好的可扩展性和泛化能力,可以应用于各种视觉任务。
关键设计:TPO的关键设计包括:1) 任务token的初始化:可以使用随机初始化或预训练的词向量。2) 任务特定头的选择:根据任务的类型选择合适的输出层。3) 损失函数的设计:可以使用交叉熵损失、均方误差损失等。4) 优化器的选择:可以使用Adam、SGD等。5) 多任务协同训练策略:可以采用均匀采样、重要性采样等方法。
🖼️ 关键图片


📊 实验亮点
实验结果表明,TPO在多模态性能上取得了显著的提升。与基线模型相比,TPO在VideoChat和LLaVA上实现了14.6%的总体性能提升。此外,MLLM-TPO在各种零样本任务中表现出强大的能力,与最先进的监督模型相当。这些结果表明,TPO是一种有效的提升MLLM在视觉任务上性能的方法。
🎯 应用场景
TPO具有广泛的应用前景,可以应用于智能监控、自动驾驶、医疗影像分析、机器人导航等领域。通过提升MLLM在视觉任务上的精细理解能力,可以提高这些应用的准确性和可靠性。例如,在智能监控中,TPO可以帮助模型更准确地识别异常行为;在自动驾驶中,TPO可以帮助模型更准确地识别交通标志和行人;在医疗影像分析中,TPO可以帮助医生更准确地诊断疾病。
📄 摘要(原文)
Current multimodal large language models (MLLMs) struggle with fine-grained or precise understanding of visuals although they give comprehensive perception and reasoning in a spectrum of vision applications. Recent studies either develop tool-using or unify specific visual tasks into the autoregressive framework, often at the expense of overall multimodal performance. To address this issue and enhance MLLMs with visual tasks in a scalable fashion, we propose Task Preference Optimization (TPO), a novel method that utilizes differentiable task preferences derived from typical fine-grained visual tasks. TPO introduces learnable task tokens that establish connections between multiple task-specific heads and the MLLM. By leveraging rich visual labels during training, TPO significantly enhances the MLLM's multimodal capabilities and task-specific performance. Through multi-task co-training within TPO, we observe synergistic benefits that elevate individual task performance beyond what is achievable through single-task training methodologies. Our instantiation of this approach with VideoChat and LLaVA demonstrates an overall 14.6% improvement in multimodal performance compared to baseline models. Additionally, MLLM-TPO demonstrates robust zero-shot capabilities across various tasks, performing comparably to state-of-the-art supervised models. The code will be released at https://github.com/OpenGVLab/TPO