Perceive, Query & Reason: Enhancing Video QA with Question-Guided Temporal Queries
作者: Roberto Amoroso, Gengyuan Zhang, Rajat Koner, Lorenzo Baraldi, Rita Cucchiara, Volker Tresp
分类: cs.CV
发布日期: 2024-12-26
备注: WACV 2025
💡 一句话要点
提出T-Former,通过问题引导的时序建模增强视频问答能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频问答 时序建模 多模态学习 大型语言模型 注意力机制
📋 核心要点
- 视频问答的关键挑战在于如何有效提取与问题相关的时序信息,现有方法难以在时空维度上对齐视觉和语言信息。
- T-Former的核心思想是构建一个问题引导的时序桥梁,连接逐帧的视觉感知和大型语言模型的推理能力,实现更精准的时序建模。
- 实验结果表明,T-Former在多个视频问答基准测试中表现出色,与现有先进的时序建模方法相比具有竞争力。
📝 摘要(中文)
视频问答(Video QA)是一项具有挑战性的视频理解任务,它要求模型理解整个视频,根据给定问题的上下文线索识别最相关的信息,并准确地进行推理以提供答案。多模态大型语言模型(MLLM)的最新进展通过利用其卓越的常识推理能力改变了视频QA。这一进展主要得益于视觉数据和MLLM语言空间之间的有效对齐。然而,对于视频QA,额外的时间-空间对齐对跨帧提取问题相关信息提出了相当大的挑战。在这项工作中,我们研究了各种时序建模技术,以与MLLM集成,旨在实现问题引导的时序建模,从而利用MLLM中预训练的视觉和文本对齐。我们提出了一种新的时序建模方法T-Former,它在逐帧视觉感知和LLM的推理能力之间创建了一个问题引导的时序桥梁。我们在多个视频QA基准上的评估表明,T-Former与现有的时序建模方法相比具有竞争力,并与视频QA的最新进展保持一致。
🔬 方法详解
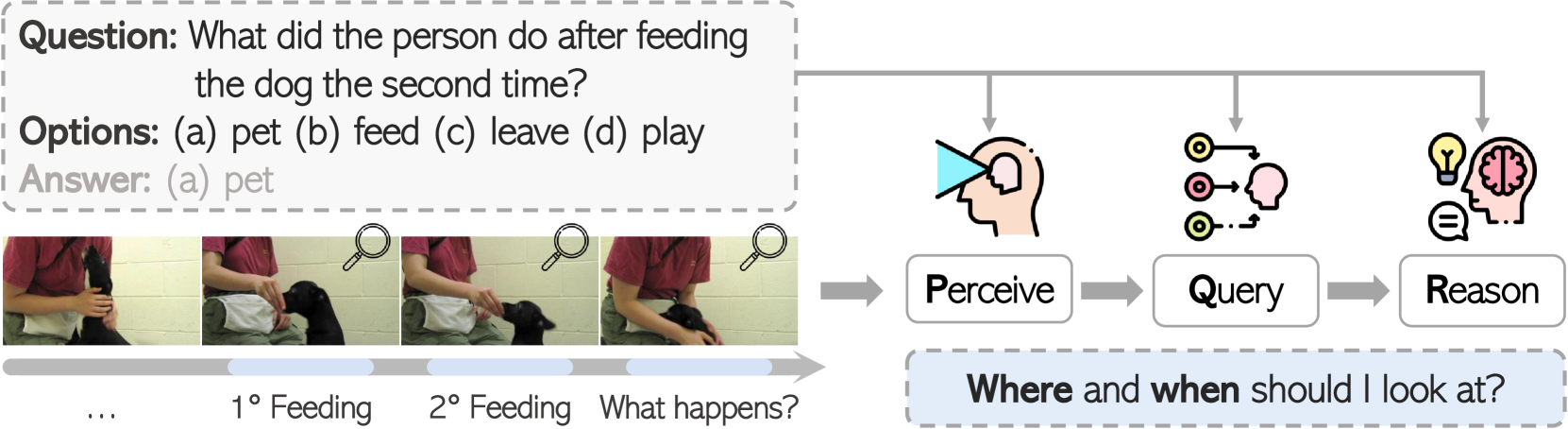
问题定义:视频问答任务需要模型理解视频内容并根据问题给出答案。现有的方法在处理视频时序信息时,难以有效地提取与问题相关的帧,并且缺乏对视觉和语言信息在时序上的有效对齐,导致推理精度不高。
核心思路:T-Former的核心思路是利用问题作为引导,在视频帧之间建立时序连接,从而更好地提取与问题相关的时序信息。通过这种方式,模型可以更加关注视频中与问题相关的部分,提高推理的准确性。这种设计旨在弥合视觉感知和语言推理之间的差距,充分利用预训练的MLLM的优势。
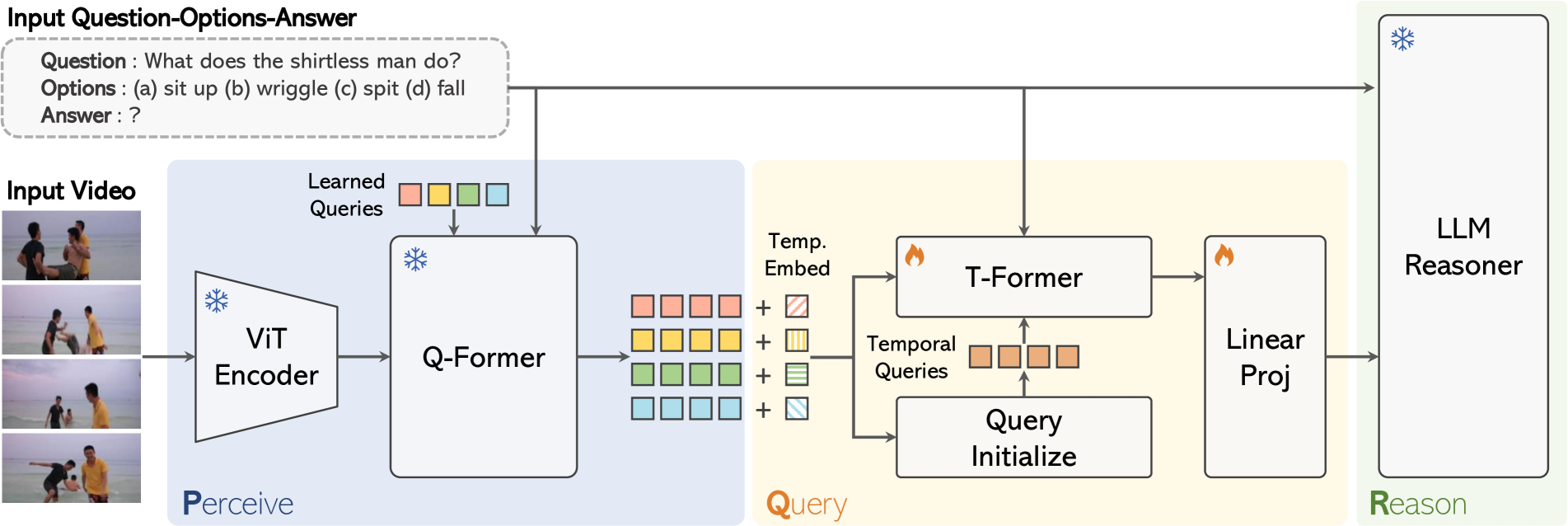
技术框架:T-Former的整体框架包含以下几个主要模块:1) 视频帧特征提取模块,用于提取每一帧的视觉特征;2) 问题编码模块,用于将问题编码成向量表示;3) 问题引导的时序建模模块(T-Former),用于在视频帧特征之间建立时序连接,并根据问题选择相关的帧;4) 多模态融合模块,用于将视觉特征和问题表示融合;5) 答案预测模块,用于根据融合后的特征预测答案。
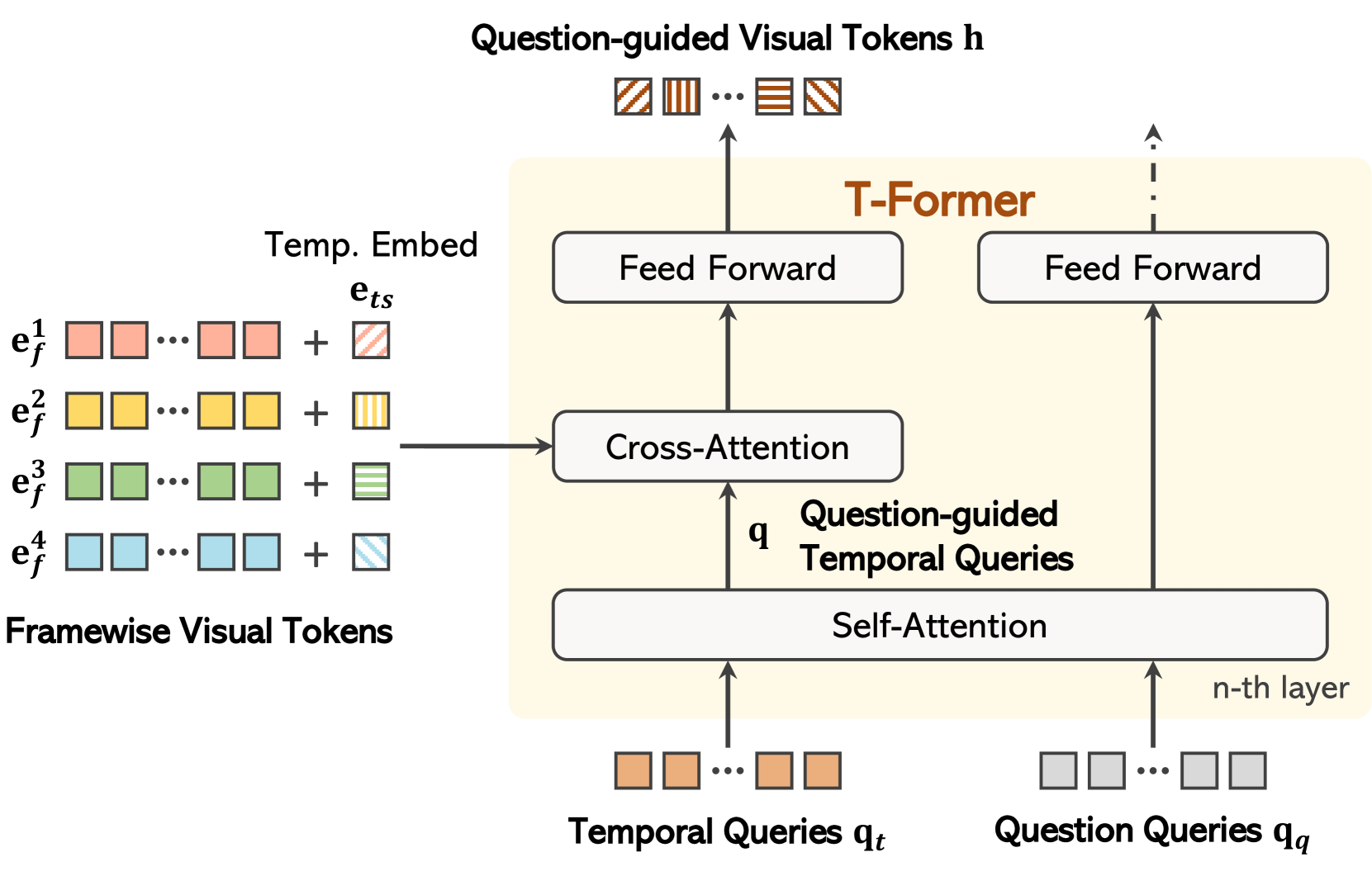
关键创新:T-Former的关键创新在于问题引导的时序建模模块。该模块通过注意力机制,根据问题动态地调整帧之间的连接权重,从而实现对问题相关帧的有效选择。与传统的时序建模方法相比,T-Former能够更加精准地提取与问题相关的时序信息,避免了无关信息的干扰。
关键设计:T-Former模块使用了Transformer结构,并引入了问题作为query,计算每一帧与问题之间的相关性,从而动态地调整帧之间的连接权重。损失函数方面,使用了交叉熵损失函数来优化答案预测模块。具体的网络结构和参数设置在论文中有详细描述,但摘要中未提及具体数值。
🖼️ 关键图片
📊 实验亮点
T-Former在多个视频QA基准测试中取得了良好的效果,证明了其有效性。虽然摘要中没有给出具体的性能数据和提升幅度,但强调了T-Former与现有先进的时序建模方法相比具有竞争力,并与视频QA的最新进展保持一致。具体的实验结果需要在论文中进一步查阅。
🎯 应用场景
该研究成果可应用于智能视频分析、智能客服、视频搜索等领域。例如,在智能客服中,可以利用该技术理解用户提出的视频相关问题,并快速准确地给出答案。在视频搜索中,可以根据用户的问题,快速定位到视频中相关的片段。未来,该技术有望在更多视频理解相关的应用中发挥重要作用。
📄 摘要(原文)
Video Question Answering (Video QA) is a challenging video understanding task that requires models to comprehend entire videos, identify the most relevant information based on contextual cues from a given question, and reason accurately to provide answers. Recent advancements in Multimodal Large Language Models (MLLMs) have transformed video QA by leveraging their exceptional commonsense reasoning capabilities. This progress is largely driven by the effective alignment between visual data and the language space of MLLMs. However, for video QA, an additional space-time alignment poses a considerable challenge for extracting question-relevant information across frames. In this work, we investigate diverse temporal modeling techniques to integrate with MLLMs, aiming to achieve question-guided temporal modeling that leverages pre-trained visual and textual alignment in MLLMs. We propose T-Former, a novel temporal modeling method that creates a question-guided temporal bridge between frame-wise visual perception and the reasoning capabilities of LLMs. Our evaluation across multiple video QA benchmarks demonstrates that T-Former competes favorably with existing temporal modeling approaches and aligns with recent advancements in video QA.