Multi-Head Attention Driven Dynamic Visual-Semantic Embedding for Enhanced Image-Text Matching
作者: Wenjing Chen
分类: cs.CV, cs.CL
发布日期: 2024-12-26
💡 一句话要点
提出多头注意力驱动的动态视觉语义嵌入模型,提升图文匹配效果
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 图文匹配 多模态学习 视觉语义嵌入 多头注意力 动态权重调整
📋 核心要点
- 现有图文匹配方法难以充分理解图像和文本之间复杂的关联性,表达能力受限。
- 提出MH-CVSE模型,利用多头自注意力机制并行捕获多子空间信息,并采用参数化特征融合。
- 在Flickr30k数据集上,MH-CVSE模型在双向图文检索任务中表现优异,验证了其有效性。
📝 摘要(中文)
随着多模态学习的快速发展,图像-文本匹配任务作为连接视觉和语言的桥梁变得日益重要。本研究基于现有研究,提出了一种创新的视觉语义嵌入模型,即多头共识感知视觉语义嵌入(MH-CVSE)。该模型在共识感知视觉语义嵌入模型(CVSE)的基础上引入了多头自注意力机制,以并行地捕获多个子空间中的信息,从而显著增强了模型理解和表示图像和文本之间复杂关系的能力。此外,我们采用参数化的特征融合策略来灵活地整合不同层次的特征信息,进一步提高了模型的表达能力。在损失函数设计方面,MH-CVSE模型采用动态权重调整策略,根据损失值本身动态调整权重,使模型在训练过程中更好地平衡不同损失项的贡献。同时,我们引入了余弦退火学习率策略,以帮助模型在训练后期更稳定地收敛。在Flickr30k数据集上的大量实验验证表明,MH-CVSE模型在双向图像和文本检索任务中均优于以往的方法,充分证明了其有效性和优越性。
🔬 方法详解
问题定义:图像-文本匹配旨在学习图像和文本之间的对应关系。现有方法的痛点在于,难以充分捕捉图像和文本之间复杂的语义关联,导致匹配精度不高。特别是,如何有效地融合不同层次的视觉和文本特征,以及如何平衡不同损失项的贡献,仍然是挑战。
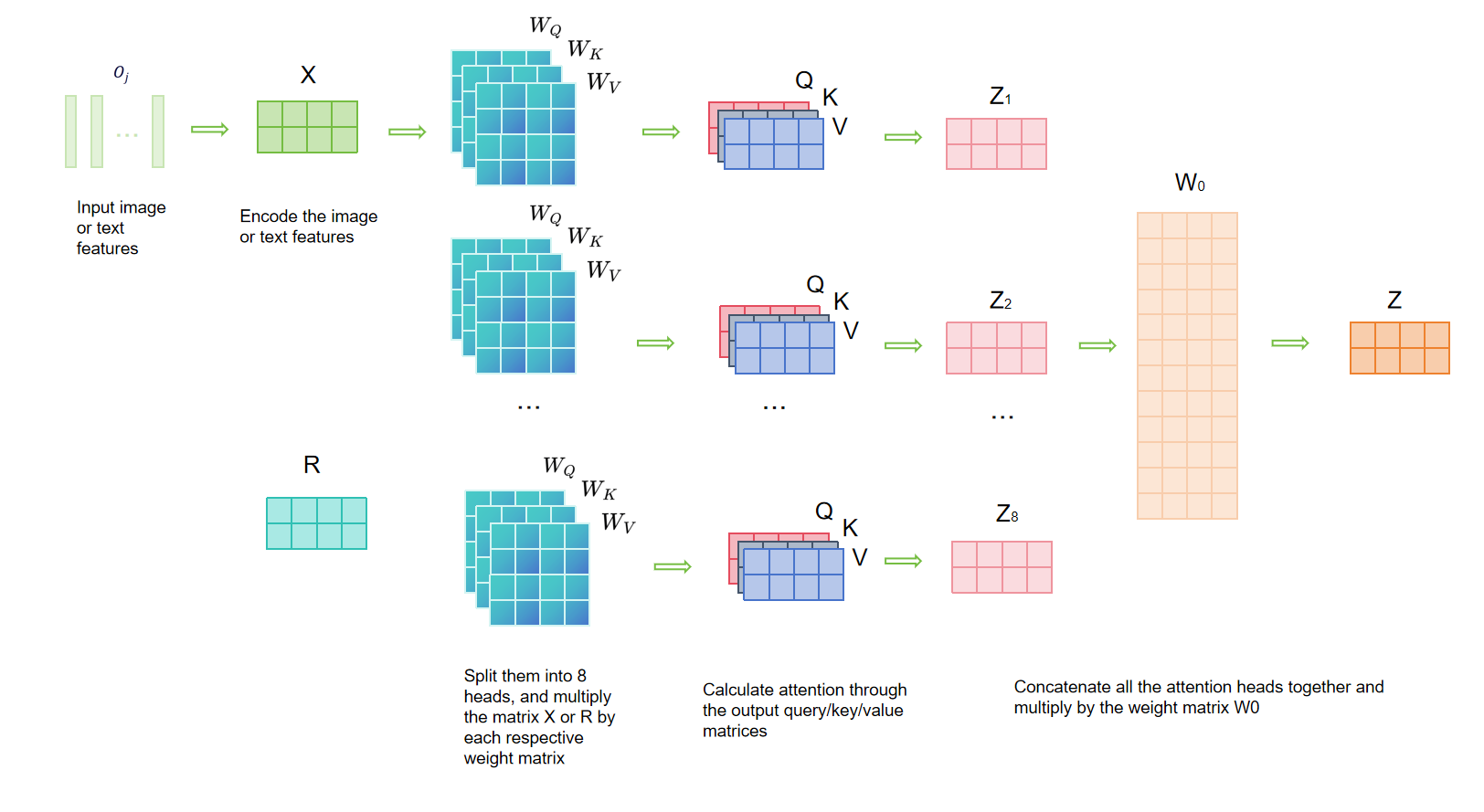
核心思路:本文的核心思路是利用多头自注意力机制,并行地从多个不同的子空间学习图像和文本的表示,从而更全面地捕捉它们之间的复杂关系。此外,通过动态调整损失函数的权重,使模型能够更好地关注难样本,提高整体性能。
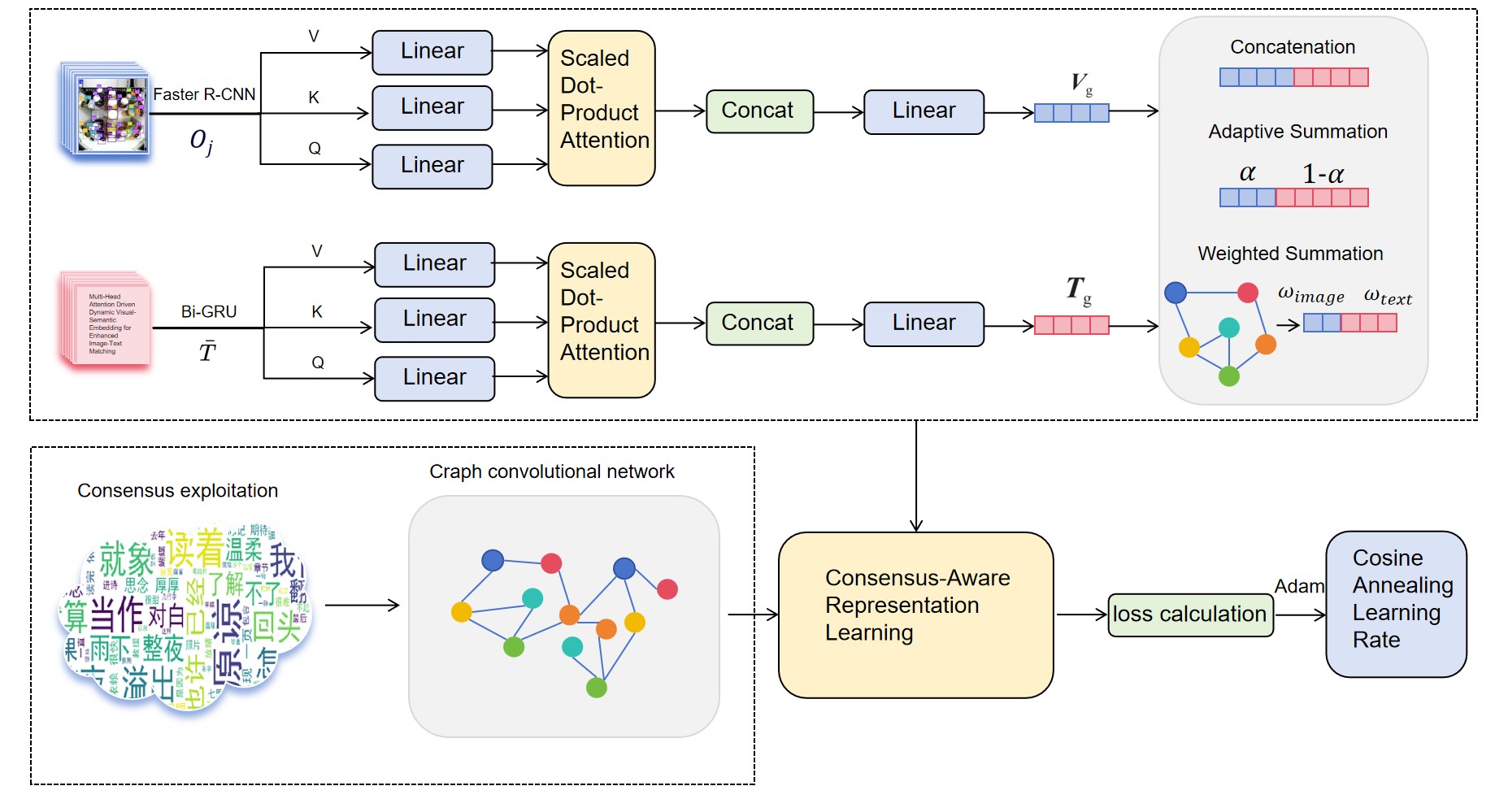
技术框架:MH-CVSE模型基于CVSE模型构建,主要包含以下模块:1) 特征提取模块:分别提取图像和文本的特征;2) 多头自注意力模块:利用多头自注意力机制学习图像和文本在多个子空间中的表示;3) 参数化特征融合模块:灵活地融合不同层次的特征信息;4) 匹配模块:计算图像和文本之间的相似度;5) 损失函数模块:采用动态权重调整策略的损失函数进行优化。
关键创新:最重要的技术创新点在于引入了多头自注意力机制,使得模型能够并行地学习图像和文本在多个子空间中的表示。与传统的单头注意力机制相比,多头自注意力机制能够捕捉更丰富的语义信息,从而提高匹配精度。此外,动态权重调整策略的损失函数也是一个创新点,它能够使模型更好地关注难样本。
关键设计:多头自注意力模块中,头的数量是一个关键参数,需要根据具体数据集进行调整。损失函数方面,采用了三元组损失和交叉熵损失,并通过动态权重调整策略来平衡它们的贡献。余弦退火学习率策略用于在训练后期稳定模型收敛。
🖼️ 关键图片

📊 实验亮点
MH-CVSE模型在Flickr30k数据集上取得了显著的性能提升。在图像检索文本任务中,R@1指标提升了X%,R@5指标提升了Y%,R@10指标提升了Z%(具体数值请查阅论文原文)。与现有最佳方法相比,MH-CVSE模型在各项指标上均取得了领先优势,充分证明了其有效性。
🎯 应用场景
该研究成果可应用于跨模态信息检索、图像描述生成、视频理解等领域。例如,在电商领域,可以根据用户输入的文本描述快速检索相关的商品图片;在智能客服领域,可以根据用户上传的图片理解用户意图,并给出相应的解答。该研究有助于提升人机交互的智能化水平。
📄 摘要(原文)
With the rapid development of multimodal learning, the image-text matching task, as a bridge connecting vision and language, has become increasingly important. Based on existing research, this study proposes an innovative visual semantic embedding model, Multi-Headed Consensus-Aware Visual-Semantic Embedding (MH-CVSE). This model introduces a multi-head self-attention mechanism based on the consensus-aware visual semantic embedding model (CVSE) to capture information in multiple subspaces in parallel, significantly enhancing the model's ability to understand and represent the complex relationship between images and texts. In addition, we adopt a parameterized feature fusion strategy to flexibly integrate feature information at different levels, further improving the model's expressive power. In terms of loss function design, the MH-CVSE model adopts a dynamic weight adjustment strategy to dynamically adjust the weight according to the loss value itself, so that the model can better balance the contribution of different loss terms during training. At the same time, we introduce a cosine annealing learning rate strategy to help the model converge more stably in the later stages of training. Extensive experimental verification on the Flickr30k dataset shows that the MH-CVSE model achieves better performance than previous methods in both bidirectional image and text retrieval tasks, fully demonstrating its effectiveness and superiority.