Reversed in Time: A Novel Temporal-Emphasized Benchmark for Cross-Modal Video-Text Retrieval
作者: Yang Du, Yuqi Liu, Qin Jin
分类: cs.CV, cs.AI, cs.CL, cs.IR, cs.LG
发布日期: 2024-12-26 (更新: 2025-09-28)
备注: ACMMM 2024 poster
🔗 代码/项目: GITHUB
💡 一句话要点
提出RTime数据集以解决视频-文本检索中的时间理解问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频-文本检索 时间理解 跨模态检索 数据集构建 多模态学习
📋 核心要点
- 现有视频-文本检索基准在时间理解评估上存在不足,导致图像-文本预训练模型在零-shot任务中表现出色。
- 本文提出RTime数据集,通过反转视频生成更具挑战性的负样本,并结合人工标注和GPT-4扩展字幕。
- 实验结果表明,RTime为视频-文本检索提供了新的基准,显著提高了模型在时间理解方面的挑战性。
📝 摘要(中文)
跨模态检索(如图像-文本、视频-文本)是信息检索和多模态视觉语言理解领域的重要任务。由于时间理解使得视频-文本检索比图像-文本检索更具挑战性,现有视频-文本基准在全面评估模型能力方面存在不足。为此,本文提出了RTime,一个新颖的时间强调视频-文本检索数据集。我们收集了具有显著时间性的动作或事件视频,并反转这些视频以创建更具挑战性的负样本。通过人工标注和GPT-4扩展,我们构建了包含21,000个视频和每个视频10个字幕的RTime数据集。基于此,我们提出了三个检索基准任务,并在多种视频-文本模型上进行了基准测试,证明RTime确实为视频-文本检索带来了新的挑战。
🔬 方法详解
问题定义:本文旨在解决现有视频-文本检索基准在时间理解评估上的不足,导致图像-文本模型在零-shot任务中表现优异的问题。
核心思路:通过收集具有显著时间性的动作或事件视频,并反转这些视频以生成更具挑战性的负样本,从而提升模型对时间信息的理解能力。
技术框架:整体流程包括视频收集、视频反转、人工标注、GPT-4字幕扩展和基准测试。主要模块包括视频处理、标注系统和模型评估。
关键创新:RTime数据集的核心创新在于引入了时间反转的负样本生成方法,这一方法在现有视频-文本检索中尚未被广泛应用。
关键设计:在数据集构建中,设置了严格的标注标准,并采用GPT-4进行字幕扩展,确保每个视频的多样性和质量。
🖼️ 关键图片

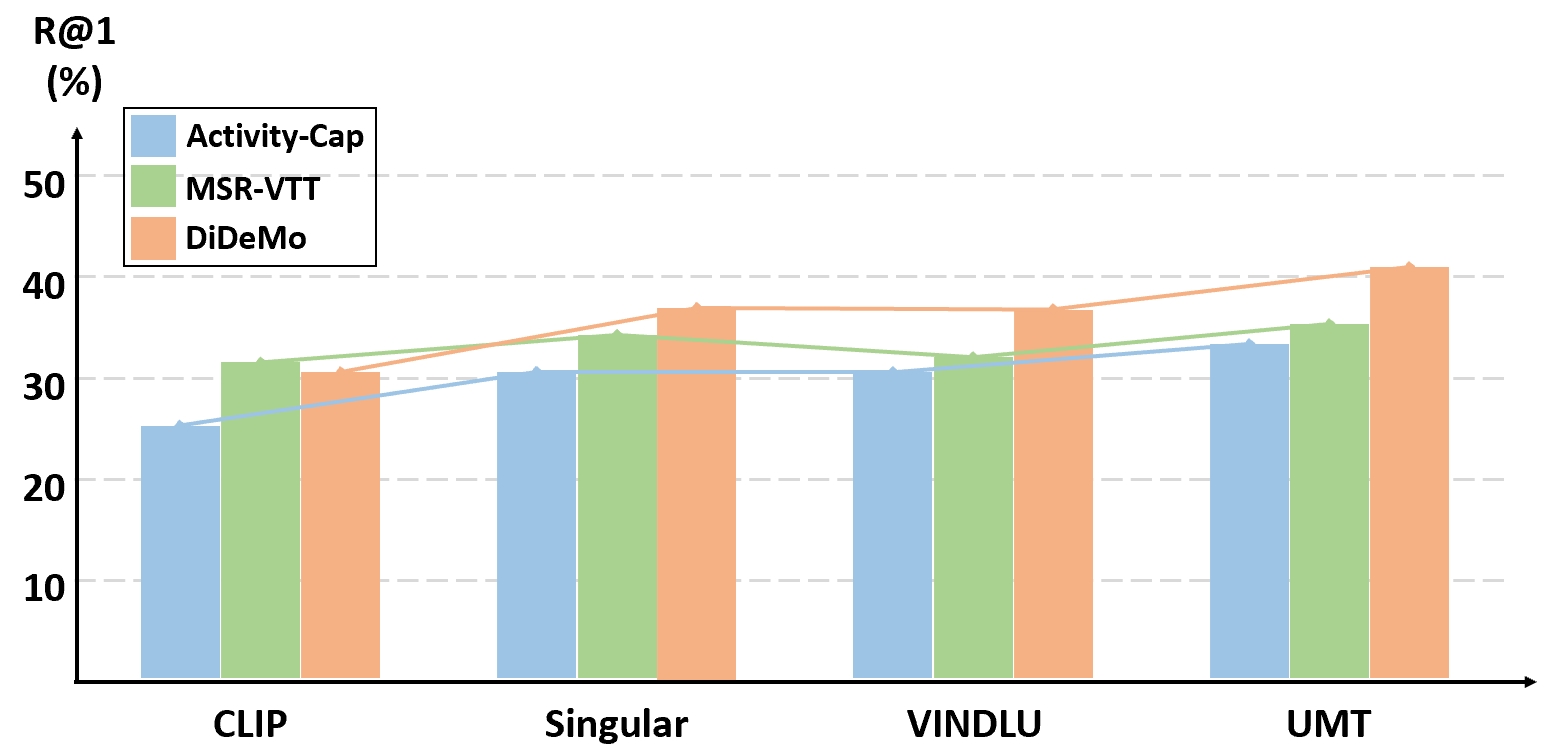
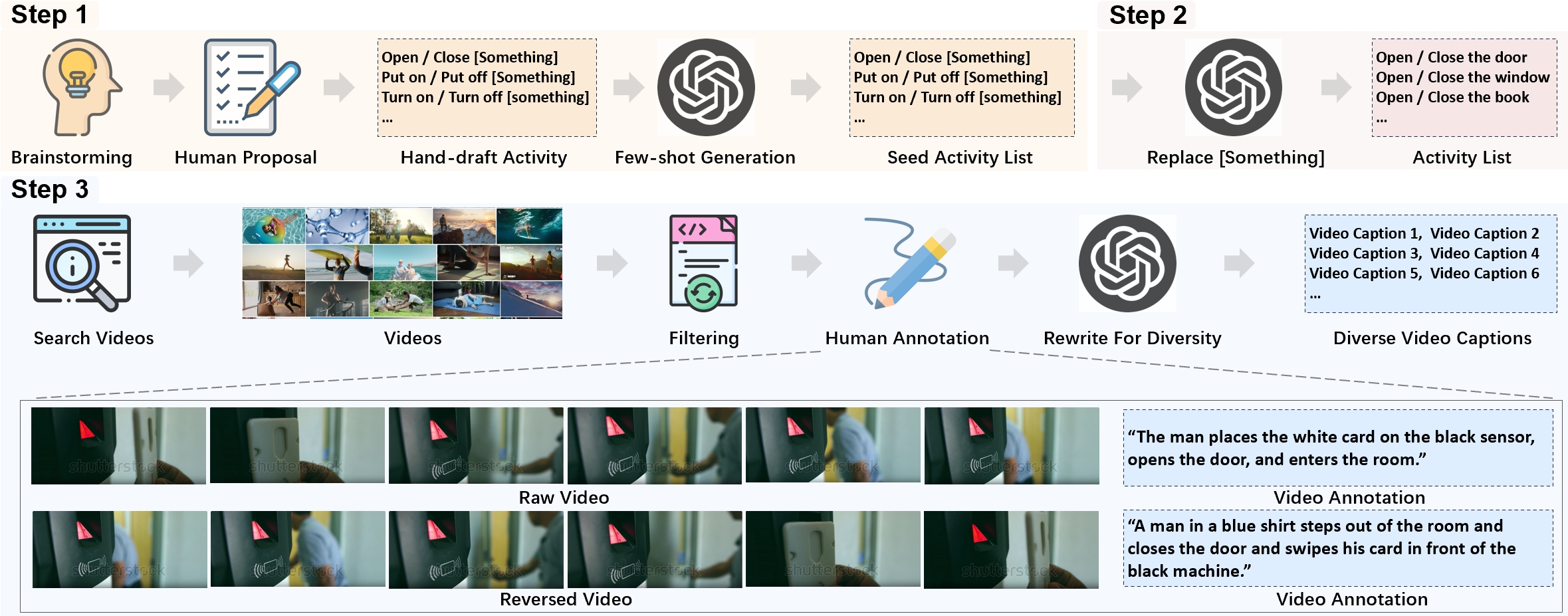
📊 实验亮点
实验结果表明,基于RTime数据集的模型在视频-文本检索任务中表现出显著提升,尤其是在时间理解方面。具体性能数据和对比基线尚未提供,但实验分析证明了RTime的有效性和挑战性。
🎯 应用场景
该研究的潜在应用领域包括视频检索、智能监控、自动视频摘要生成等。通过提升视频-文本检索的准确性和效率,RTime数据集将推动多模态理解技术的发展,促进相关领域的研究和应用。
📄 摘要(原文)
Cross-modal (e.g. image-text, video-text) retrieval is an important task in information retrieval and multimodal vision-language understanding field. Temporal understanding makes video-text retrieval more challenging than image-text retrieval. However, we find that the widely used video-text benchmarks have shortcomings in comprehensively assessing abilities of models, especially in temporal understanding, causing large-scale image-text pre-trained models can already achieve comparable zero-shot performance with video-text pre-trained models. In this paper, we introduce RTime, a novel temporal-emphasized video-text retrieval dataset. We first obtain videos of actions or events with significant temporality, and then reverse these videos to create harder negative samples. We then recruit annotators to judge the significance and reversibility of candidate videos, and write captions for qualified videos. We further adopt GPT-4 to extend more captions based on human-written captions. Our RTime dataset currently consists of 21k videos with 10 captions per video, totalling about 122 hours. Based on RTime, we propose three retrieval benchmark tasks: RTime-Origin, RTime-Hard, and RTime-Binary. We further enhance the use of harder-negatives in model training, and benchmark a variety of video-text models on RTime. Extensive experiment analysis proves that RTime indeed poses new and higher challenges to video-text retrieval. We release our RTime dataset https://github.com/qyr0403/Reversed-in-Time to further advance video-text retrieval and multimodal understanding research.