Revisiting Monocular 3D Object Detection with Depth Thickness Field
作者: Qiude Zhang, Chunyu Lin, Zhijie Shen, Nie Lang, Yao Zhao
分类: cs.CV
发布日期: 2024-12-26 (更新: 2025-03-24)
💡 一句话要点
提出深度厚度场MonoDTF,提升单目3D目标检测的结构感知能力
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 单目3D目标检测 深度估计 深度厚度场 场景理解 自动驾驶
📋 核心要点
- 单目3D目标检测面临挑战,现有方法依赖的单目深度估计精度不足,限制了检测性能。
- 论文提出深度厚度场(Depth Thickness Field)来嵌入场景的3D结构信息,增强模型对3D结构的感知能力。
- 实验结果表明,所提出的MonoDTF方法在KITTI和Waymo数据集上优于现有SOTA方法,且具有较好的通用性。
📝 摘要(中文)
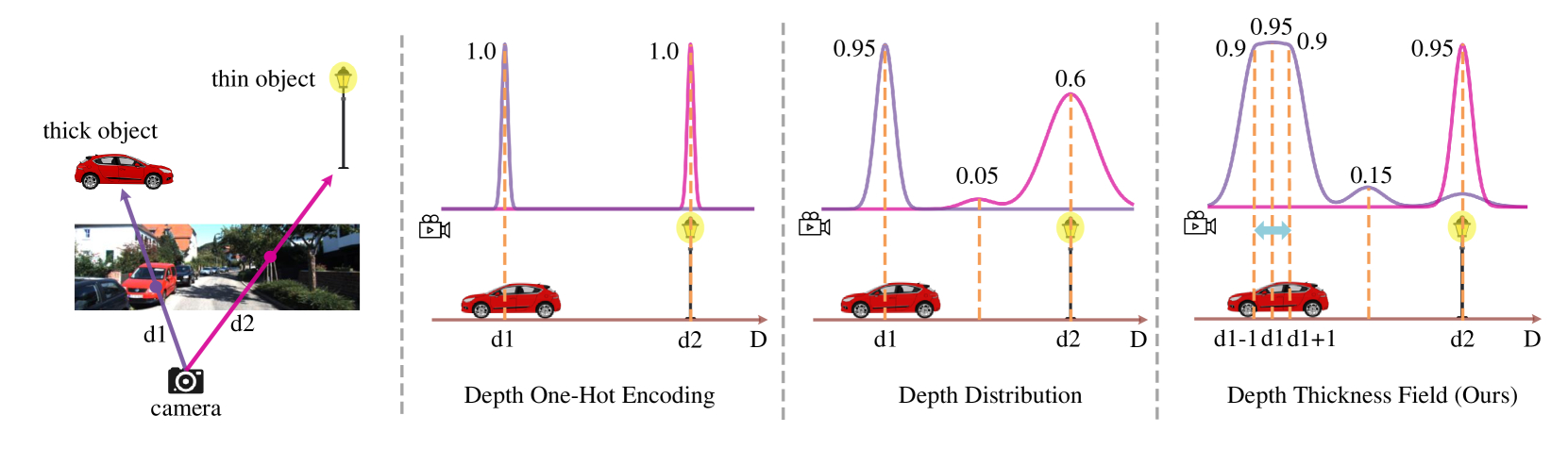
单目3D目标检测由于缺乏精确的深度信息而具有挑战性。现有基于深度辅助的解决方案性能仍然较差,这通常归因于单目深度估计模型的不理想精度。本文从深度角度重新审视单目3D目标检测,并提出了一个额外的问题,即现有深度表示(例如,深度one-hot编码或深度分布)的有限的3D结构感知能力。为了解决这个问题,我们引入了一种新的深度厚度场方法来嵌入清晰的场景3D结构。具体来说,我们提出了MonoDTF,一个场景到实例深度自适应网络,用于单目3D目标检测。该框架主要包括一个场景级深度重定向(SDR)模块和一个实例级空间细化(ISR)模块。前者将传统深度表示重定向到提出的深度厚度场,从而结合了场景级的3D结构感知。后者在实例的指导下细化体素空间,增强了深度厚度场的3D实例感知能力,从而提高了检测精度。在KITTI和Waymo数据集上的大量实验表明,我们的方法优于现有的最先进方法,并且在配备不同的深度估计模型时具有通用性。代码即将发布。
🔬 方法详解
问题定义:单目3D目标检测的关键挑战在于缺乏精确的深度信息,导致难以准确推断3D目标的位置和尺寸。现有方法通常依赖单目深度估计,但其精度不足,并且现有深度表示方法(如深度one-hot编码或深度分布)对3D结构的感知能力有限,无法充分利用深度信息进行3D目标检测。
核心思路:论文的核心思路是提出一种新的深度表示方法,即深度厚度场(Depth Thickness Field, DTF),以更有效地编码场景的3D结构信息。DTF旨在克服现有深度表示方法在3D结构感知方面的局限性,从而提升单目3D目标检测的性能。通过将深度信息转化为厚度场,可以更好地捕捉场景中物体的空间关系和几何形状。
技术框架:MonoDTF框架包含两个主要模块:场景级深度重定向(Scene-Level Depth Retargeting, SDR)模块和实例级空间细化(Instance-Level Spatial Refinement, ISR)模块。SDR模块将传统的深度表示转换为提出的深度厚度场,从而引入场景级的3D结构感知。ISR模块则在实例的指导下细化体素空间,增强深度厚度场的3D实例感知能力。整体流程是从单目图像和深度估计开始,通过SDR模块生成DTF,然后利用ISR模块进行实例级别的空间细化,最终实现3D目标检测。
关键创新:论文的关键创新在于提出了深度厚度场(DTF)这一新的深度表示方法。与传统的深度表示方法相比,DTF能够更有效地编码场景的3D结构信息,从而提升模型对3D结构的感知能力。此外,SDR和ISR模块的设计也旨在充分利用DTF的优势,从而提高单目3D目标检测的精度。
关键设计:SDR模块的具体实现细节未知,但其核心目标是将传统深度表示转换为DTF。ISR模块则利用实例信息来细化体素空间,可能涉及到3D卷积、注意力机制等技术。损失函数的设计也至关重要,需要综合考虑3D目标的位置、尺寸和方向等因素。具体的网络结构和参数设置在论文中应该有详细描述,但摘要中未提及。
🖼️ 关键图片


📊 实验亮点
实验结果表明,所提出的MonoDTF方法在KITTI和Waymo数据集上均取得了显著的性能提升,优于现有的SOTA方法。具体的数据提升幅度未知,但摘要强调了该方法在配备不同的深度估计模型时具有通用性,表明其具有较强的鲁棒性。
🎯 应用场景
该研究成果可应用于自动驾驶、机器人导航、增强现实等领域。在自动驾驶中,单目3D目标检测可以帮助车辆理解周围环境,识别车辆、行人等目标,从而做出更安全的决策。在机器人导航中,可以帮助机器人进行场景理解和目标定位。在增强现实中,可以实现更逼真的虚拟物体与真实场景的融合。
📄 摘要(原文)
Monocular 3D object detection is challenging due to the lack of accurate depth. However, existing depth-assisted solutions still exhibit inferior performance, whose reason is universally acknowledged as the unsatisfactory accuracy of monocular depth estimation models. In this paper, we revisit monocular 3D object detection from the depth perspective and formulate an additional issue as the limited 3D structure-aware capability of existing depth representations (e.g., depth one-hot encoding or depth distribution). To address this issue, we introduce a novel Depth Thickness Field approach to embed clear 3D structures of the scenes. Specifically, we present MonoDTF, a scene-to-instance depth-adapted network for monocular 3D object detection. The framework mainly comprises a Scene-Level Depth Retargeting (SDR) module and an Instance-Level Spatial Refinement (ISR) module. The former retargets traditional depth representations to the proposed depth thickness field, incorporating the scene-level perception of 3D structures. The latter refines the voxel space with the guidance of instances, enhancing the 3D instance-aware capability of the depth thickness field and thus improving detection accuracy. Extensive experiments on the KITTI and Waymo datasets demonstrate our superiority to existing state-of-the-art (SoTA) methods and the universality when equipped with different depth estimation models. The code will be available.