Referencing Where to Focus: Improving VisualGrounding with Referential Query
作者: Yabing Wang, Zhuotao Tian, Qingpei Guo, Zheng Qin, Sanping Zhou, Ming Yang, Le Wang
分类: cs.CV, cs.CL
发布日期: 2024-12-26
备注: Accepted by NIPS2024
💡 一句话要点
提出RefFormer,通过引入参考查询改进DETR视觉定位,提升定位精度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉定位 DETR CLIP 参考查询 多模态融合
📋 核心要点
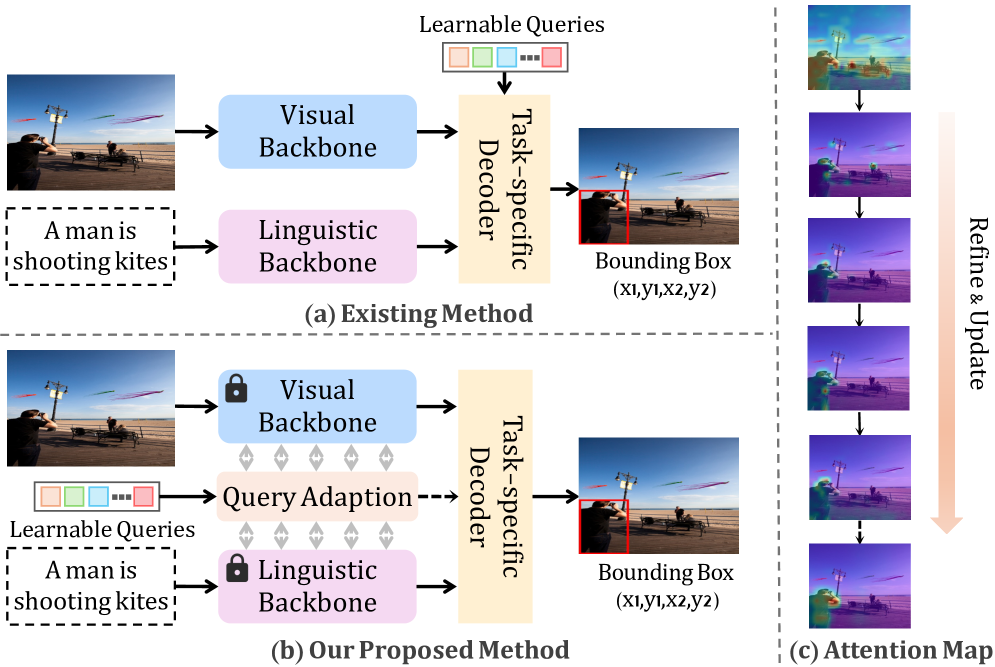
- 现有基于DETR的视觉定位方法依赖随机或语言嵌入初始化查询,缺乏目标先验信息,增加了学习难度。
- RefFormer通过查询适配模块生成参考查询,为解码器提供目标先验信息,降低学习难度,提升定位精度。
- 实验结果表明,RefFormer在五个视觉定位基准测试中超越了现有最佳方法,验证了其有效性和效率。
📝 摘要(中文)
本文提出了一种名为RefFormer的新方法,旨在改进基于DETR的视觉定位。现有方法主要集中于设计更强大的多模态解码器,通常通过随机初始化或使用语言嵌入来生成可学习的查询。这种原始的查询生成方法不可避免地增加了模型的学习难度,因为它在解码开始时没有包含任何与目标相关的信息。此外,它们仅使用最深层的图像特征进行查询学习,忽略了其他层级特征的重要性。为了解决这些问题,我们提出了RefFormer,它包含一个查询适配模块,可以无缝集成到CLIP中,并生成参考查询,为解码器提供先验上下文,以及一个特定于任务的解码器。通过将参考查询整合到解码器中,我们可以有效地降低解码器的学习难度,并准确地关注目标对象。此外,我们提出的查询适配模块还可以充当适配器,保留CLIP中丰富的知识,而无需调整骨干网络的参数。大量实验表明,我们提出的方法有效且高效,在五个视觉定位基准测试中优于最先进的方法。
🔬 方法详解
问题定义:视觉定位旨在给定自然语言表达式,在图像中定位目标对象。现有基于DETR的方法依赖于随机初始化或语言嵌入生成查询,缺乏目标相关的先验信息,导致解码器学习困难,且通常只利用最深层的图像特征,忽略了其他层级特征的价值。
核心思路:RefFormer的核心思路是利用CLIP模型提取的视觉和语言特征,通过一个查询适配模块生成包含目标信息的参考查询,作为解码器的先验知识,从而引导解码器更准确地关注目标对象,降低学习难度。同时,利用多层级的图像特征,提供更丰富的上下文信息。
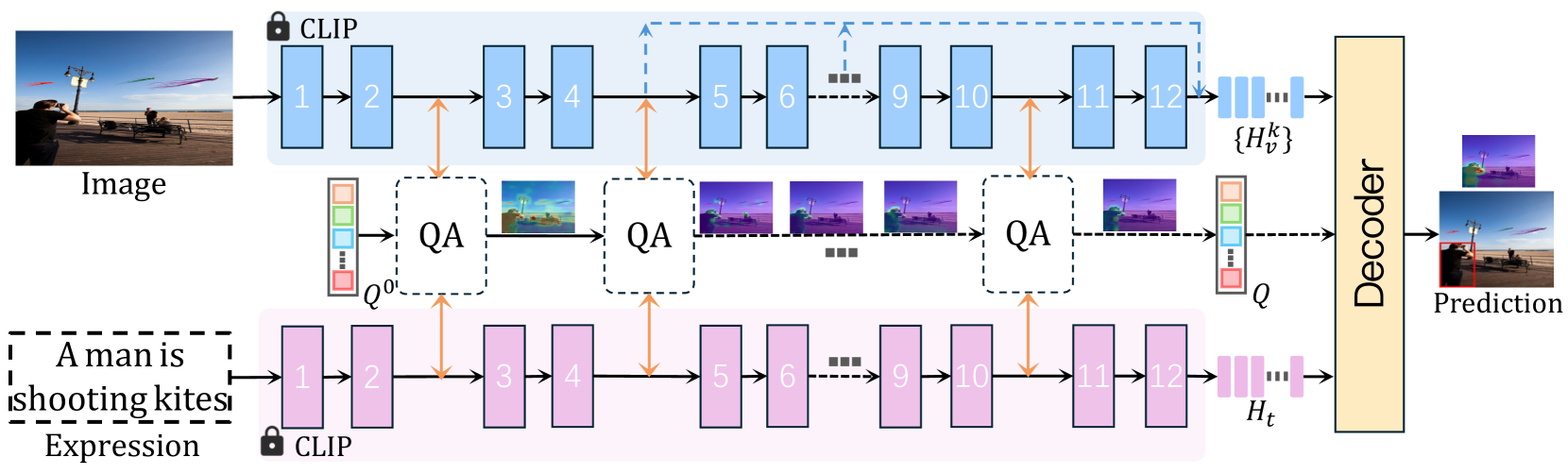
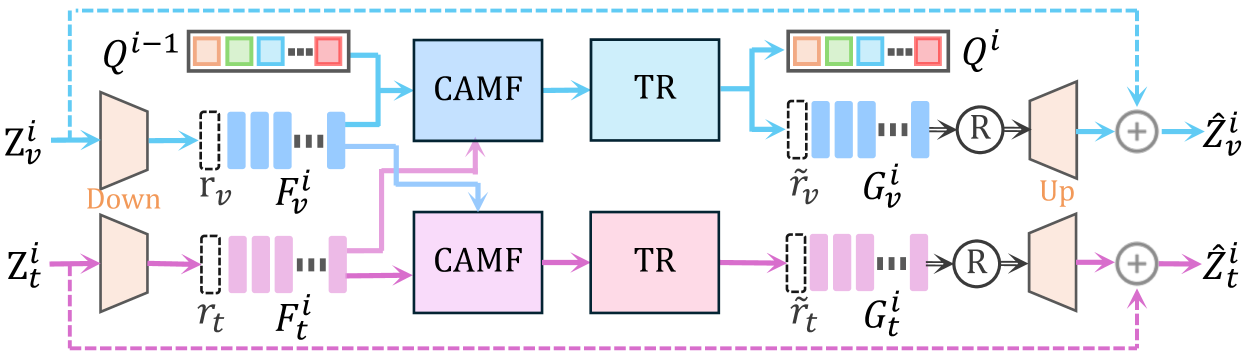
技术框架:RefFormer主要包含两个模块:查询适配模块和任务特定解码器。查询适配模块将CLIP的视觉和语言特征融合,生成参考查询。任务特定解码器接收参考查询和多层级图像特征,预测目标对象的坐标。整体流程是:输入图像和文本描述,通过CLIP提取视觉和语言特征,查询适配模块生成参考查询,解码器利用参考查询和多层级图像特征进行目标定位。
关键创新:RefFormer的关键创新在于引入了参考查询的概念,利用预训练的CLIP模型提取的知识,为解码器提供目标相关的先验信息,避免了从零开始学习的困难。此外,查询适配模块的设计使得CLIP的知识可以被有效利用,而无需调整CLIP的参数。
关键设计:查询适配模块的具体实现方式未知,但可以推测其可能包含一些注意力机制或特征融合操作,用于将CLIP的视觉和语言特征进行对齐和融合,生成包含目标信息的查询向量。解码器可能采用Transformer结构,利用自注意力机制和交叉注意力机制,融合参考查询和多层级图像特征,最终预测目标对象的坐标。损失函数可能包含定位损失和匹配损失,用于优化模型的定位精度和匹配能力。
🖼️ 关键图片
📊 实验亮点
RefFormer在五个视觉定位基准测试中取得了state-of-the-art的结果,证明了其有效性和效率。具体性能数据未知,但摘要中明确指出RefFormer优于现有最佳方法,表明其在定位精度和效率方面都有显著提升。
🎯 应用场景
RefFormer在视觉定位领域具有广泛的应用前景,例如智能客服、图像搜索、机器人导航等。它可以帮助计算机理解人类的语言描述,并在图像中准确地找到对应的目标对象,从而实现更智能的人机交互和更高效的图像处理。
📄 摘要(原文)
Visual Grounding aims to localize the referring object in an image given a natural language expression. Recent advancements in DETR-based visual grounding methods have attracted considerable attention, as they directly predict the coordinates of the target object without relying on additional efforts, such as pre-generated proposal candidates or pre-defined anchor boxes. However, existing research primarily focuses on designing stronger multi-modal decoder, which typically generates learnable queries by random initialization or by using linguistic embeddings. This vanilla query generation approach inevitably increases the learning difficulty for the model, as it does not involve any target-related information at the beginning of decoding. Furthermore, they only use the deepest image feature during the query learning process, overlooking the importance of features from other levels. To address these issues, we propose a novel approach, called RefFormer. It consists of the query adaption module that can be seamlessly integrated into CLIP and generate the referential query to provide the prior context for decoder, along with a task-specific decoder. By incorporating the referential query into the decoder, we can effectively mitigate the learning difficulty of the decoder, and accurately concentrate on the target object. Additionally, our proposed query adaption module can also act as an adapter, preserving the rich knowledge within CLIP without the need to tune the parameters of the backbone network. Extensive experiments demonstrate the effectiveness and efficiency of our proposed method, outperforming state-of-the-art approaches on five visual grounding benchmarks.