Humans as a Calibration Pattern: Dynamic 3D Scene Reconstruction from Unsynchronized and Uncalibrated Videos
作者: Changwoon Choi, Jeongjun Kim, Geonho Cha, Minkwan Kim, Dongyoon Wee, Young Min Kim
分类: cs.CV
发布日期: 2024-12-26 (更新: 2025-03-08)
💡 一句话要点
利用人体作为校准模式,从非同步、未标定的视频中重建动态3D场景。
🎯 匹配领域: 支柱三:空间感知与语义 (Perception & Semantics)
关键词: 动态3D重建 神经场 人体姿态估计 非同步视频 未标定相机
📋 核心要点
- 现有动态3D神经场重建方法依赖同步且已标定的多视角视频,限制了其在实际场景中的应用。
- 该方法利用人体运动的先验知识,通过估计人体形状和姿态参数来初始化动态神经场的训练,解决未标定和非同步视频的重建问题。
- 实验结果表明,该方法在时空校准和场景重建方面表现出色,尤其是在具有挑战性的条件下。
📝 摘要(中文)
本文提出了一种从非同步、未标定的多视角视频中重建动态神经场的方法。现有方法通常需要同步且相机位姿已知的视频作为输入,这在实际场景中难以满足。本文利用视频中常见的人体运动作为先验信息,通过估计人体形状和姿态参数来初始化动态神经场的训练。具体而言,首先估计视频间的时间偏移,然后通过分析3D关节位置估计相机位姿。接着,采用多分辨率网格训练动态神经场,并同时优化时间偏移和相机位姿。为了稳定优化过程,引入了一种鲁棒的渐进式学习策略。实验结果表明,该方法在具有挑战性的条件下实现了精确的时空校准和高质量的场景重建。
🔬 方法详解
问题定义:论文旨在解决从非同步、未标定的多视角视频中重建动态3D场景的问题。现有方法通常需要同步且相机位姿已知的视频作为输入,这在实际场景中难以满足,限制了其应用范围。这些方法对输入数据要求高,难以处理真实世界中普遍存在的非同步和未标定视频数据。
核心思路:论文的核心思路是利用视频中常见的人体运动作为校准模式。人体形状和姿态可以使用现有的姿态估计方法进行估计,虽然这些估计结果可能存在噪声,但可以为动态神经场的训练提供一个合理的初始化点。通过优化人体姿态、相机位姿和时间偏移,可以实现对动态场景的重建。
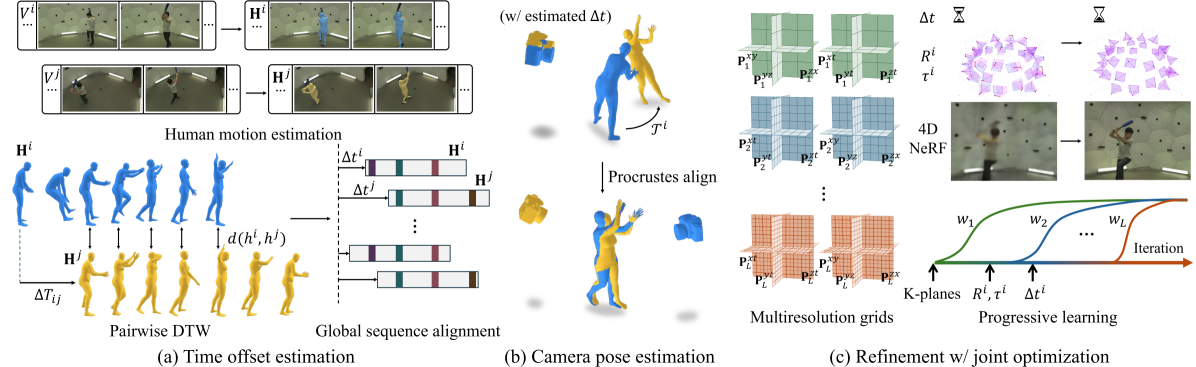
技术框架:整体框架包含以下几个主要阶段:1) 人体姿态估计:使用现有的姿态估计方法从每个视频帧中提取人体形状和姿态参数。2) 时间偏移估计:基于人体姿态信息,计算不同视频之间的时间偏移。3) 相机位姿估计:分析3D关节位置,估计每个相机的位姿。4) 动态神经场训练:使用多分辨率网格表示动态神经场,并同时优化时间偏移和相机位姿。5) 渐进式学习:为了稳定优化过程,采用一种鲁棒的渐进式学习策略。
关键创新:该方法最重要的创新点在于利用人体作为校准模式,从而能够在非同步、未标定的视频中重建动态3D场景。与现有方法相比,该方法不需要预先标定的相机位姿和同步的视频数据,大大降低了对输入数据的要求。此外,渐进式学习策略也提高了优化过程的鲁棒性。
关键设计:论文采用多分辨率网格来表示动态神经场,这有助于提高重建的精度和效率。损失函数的设计考虑了人体姿态、相机位姿和时间偏移的一致性。渐进式学习策略通过逐步增加优化参数的数量来稳定训练过程。具体的参数设置和网络结构在论文中有详细描述,但具体数值未知。
🖼️ 关键图片
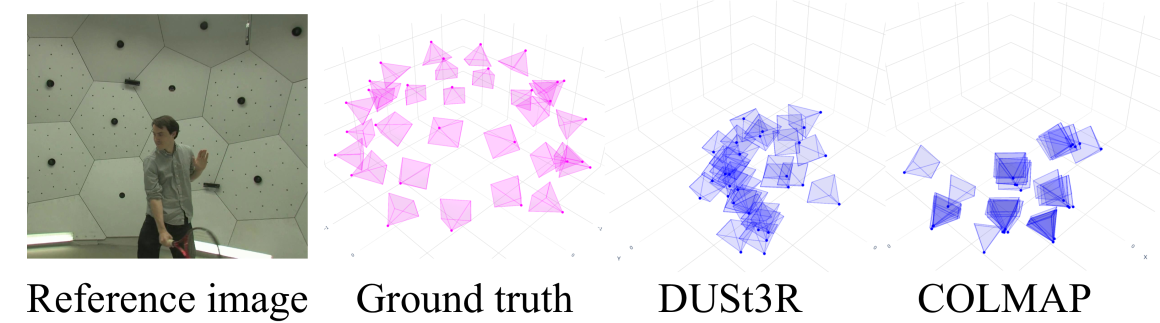

📊 实验亮点
实验结果表明,该方法在具有挑战性的条件下实现了精确的时空校准和高质量的场景重建。具体性能数据和对比基线未知,但摘要强调了其在非同步和未标定视频下的有效性。渐进式学习策略显著提高了优化过程的鲁棒性。
🎯 应用场景
该研究成果可应用于虚拟现实、增强现实、电影制作、运动分析等领域。例如,可以利用该方法从用户上传的手机视频中重建动态3D场景,从而实现沉浸式的虚拟体验。此外,该方法还可以用于分析运动员的运动姿态,提高训练效率。未来,该方法有望应用于更广泛的动态场景重建任务中。
📄 摘要(原文)
Recent works on dynamic 3D neural field reconstruction assume the input from synchronized multi-view videos whose poses are known. The input constraints are often not satisfied in real-world setups, making the approach impractical. We show that unsynchronized videos from unknown poses can generate dynamic neural fields as long as the videos capture human motion. Humans are one of the most common dynamic subjects captured in videos, and their shapes and poses can be estimated using state-of-the-art libraries. While noisy, the estimated human shape and pose parameters provide a decent initialization point to start the highly non-convex and under-constrained problem of training a consistent dynamic neural representation. Given the shape and pose parameters of humans in individual frames, we formulate methods to calculate the time offsets between videos, followed by camera pose estimations that analyze the 3D joint positions. Then, we train the dynamic neural fields employing multiresolution grids while we concurrently refine both time offsets and camera poses. The setup still involves optimizing many parameters; therefore, we introduce a robust progressive learning strategy to stabilize the process. Experiments show that our approach achieves accurate spatio-temporal calibration and high-quality scene reconstruction in challenging conditions.