MoPD: Mixture-of-Prompts Distillation for Vision-Language Models
作者: Yang Chen, Shuai Fu, Yu Zhang
分类: cs.CV, cs.CL, cs.LG
发布日期: 2024-12-26 (更新: 2025-09-12)
💡 一句话要点
提出混合提示蒸馏(MoPD)方法,提升视觉-语言模型在未见类别上的泛化能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视觉-语言模型 软提示学习 知识蒸馏 泛化能力 零样本学习
📋 核心要点
- 现有软提示学习方法在视觉-语言模型中存在过拟合已见类别,泛化能力差的问题。
- MoPD方法通过将人工设计的硬提示知识蒸馏到软提示中,提升模型在未见类别上的泛化性。
- 实验结果表明,MoPD方法在未见类别上的性能显著优于现有方法,验证了其有效性。
📝 摘要(中文)
软提示学习方法在将视觉-语言模型(VLMs)适配到下游任务中非常有效。然而,经验证据表明,现有方法容易过拟合已见类别,并在未见类别上表现出性能下降。这种局限性源于训练数据中固有的对已见类别的偏见。为了解决这个问题,我们提出了一种新颖的软提示学习方法,名为混合提示蒸馏(MoPD),它可以有效地将手动设计的硬提示(又称教师提示)中的有用知识转移到可学习的软提示(又称学生提示),从而增强软提示在未见类别上的泛化能力。此外,所提出的MoPD方法利用一个门控网络来学习选择用于提示蒸馏的硬提示。大量实验表明,所提出的MoPD方法优于最先进的基线方法,尤其是在未见类别上。
🔬 方法详解
问题定义:现有软提示学习方法在视觉-语言模型微调时,容易过拟合训练集中出现的类别(已见类别),导致在未见过的类别上表现不佳。这是因为训练数据本身存在偏差,模型学习到的提示偏向于已见类别的特征。
核心思路:MoPD的核心思想是通过知识蒸馏,将人工设计的、具有更强泛化能力的硬提示的知识迁移到可学习的软提示中。这样,软提示不仅学习了已见类别的特征,也学习了硬提示中蕴含的更通用的知识,从而提升在未见类别上的表现。
技术框架:MoPD方法包含以下几个主要模块:1) 教师提示(硬提示):人工设计的提示,提供先验知识。2) 学生提示(软提示):可学习的提示,用于适配下游任务。3) 门控网络:用于选择合适的教师提示进行知识蒸馏。4) 蒸馏损失:用于指导学生提示学习教师提示的知识。
关键创新:MoPD的关键创新在于混合提示蒸馏机制,它不同于传统的知识蒸馏,而是利用多个硬提示的混合来指导软提示的学习。此外,门控网络的设计使得模型能够自适应地选择最合适的硬提示,进一步提升了蒸馏效果。
关键设计:MoPD的关键设计包括:1) 硬提示的设计:需要根据任务特点精心设计,以提供有用的先验知识。2) 门控网络的结构:需要能够有效地选择合适的硬提示。3) 蒸馏损失函数的选择:需要能够有效地将硬提示的知识迁移到软提示中。具体参数设置和网络结构在论文中有详细描述,此处未知。
🖼️ 关键图片


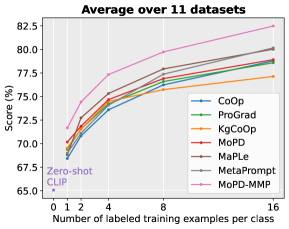
📊 实验亮点
实验结果表明,MoPD方法在未见类别上的性能显著优于现有的软提示学习方法。具体而言,MoPD在多个数据集上取得了state-of-the-art的结果,并且在未见类别上的准确率提升幅度明显高于已见类别,验证了其在提升泛化能力方面的有效性。具体数值未知。
🎯 应用场景
MoPD方法可以应用于各种视觉-语言任务,例如图像分类、图像检索、零样本学习等。该方法能够提升模型在未见类别上的泛化能力,使其在实际应用中更加鲁棒和可靠。例如,在医疗图像诊断中,可以利用MoPD方法提升模型对罕见疾病的识别能力。
📄 摘要(原文)
Soft prompt learning methods are effective for adapting vision-language models (VLMs) to downstream tasks. Nevertheless, empirical evidence reveals a tendency of existing methods that they overfit seen classes and exhibit degraded performance on unseen classes. This limitation is due to the inherent bias in the training data towards the seen classes. To address this issue, we propose a novel soft prompt learning method, named Mixture-of-Prompts Distillation (MoPD), which can effectively transfer useful knowledge from hard prompts manually hand-crafted (a.k.a. teacher prompts) to the learnable soft prompt (a.k.a. student prompt), thereby enhancing the generalization ability of soft prompts on unseen classes. Moreover, the proposed MoPD method utilizes a gating network that learns to select hard prompts used for prompt distillation. Extensive experiments demonstrate that the proposed MoPD method outperforms state-of-the-art baselines especially on on unseen classes.