An Attentive Dual-Encoder Framework Leveraging Multimodal Visual and Semantic Information for Automatic OSAHS Diagnosis
作者: Yingchen Wei, Xihe Qiu, Xiaoyu Tan, Jingjing Huang, Wei Chu, Yinghui Xu, Yuan Qi
分类: cs.CV, cs.LG
发布日期: 2024-12-25
备注: 5 pages, 2 figures, Published as a conference paper at ICASSP 2025
💡 一句话要点
提出基于多模态视觉和语义信息的注意力双编码器框架,用于自动OSAHS诊断。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: OSAHS诊断 多模态融合 深度学习 注意力机制 双编码器 视觉特征 语义特征
📋 核心要点
- 传统OSAHS诊断依赖PSG,存在成本高、耗时、不适感强等问题,亟需更便捷的诊断方法。
- 论文提出多模态双编码器模型,融合视觉和语言信息,利用注意力机制提取关键特征,提升诊断准确性。
- 实验结果表明,该方法在四分类OSAHS严重程度诊断中达到91.3%的top-1准确率,优于现有方法。
📝 摘要(中文)
阻塞性睡眠呼吸暂停低通气综合征(OSAHS)是一种常见的睡眠障碍,由上呼吸道阻塞引起,导致缺氧和睡眠中断。传统的PSG诊断方法昂贵、耗时且不舒适。现有的基于面部图像分析的深度学习方法由于面部特征捕获不佳和样本量有限而缺乏准确性。为了解决这个问题,我们提出了一种多模态双编码器模型,该模型集成了视觉和语言输入,用于自动OSAHS诊断。该模型使用randomOverSampler平衡数据,使用注意力网格提取关键面部特征,并将生理数据转换为有意义的文本。交叉注意力结合图像和文本数据以实现更好的特征提取,有序回归损失确保稳定的学习。我们的方法提高了诊断效率和准确性,在四类严重程度分类任务中实现了91.3%的top-1准确率,展示了最先进的性能。代码将在接收后发布。
🔬 方法详解
问题定义:论文旨在解决OSAHS自动诊断问题。现有方法,特别是基于面部图像分析的深度学习方法,存在面部特征捕获不佳和样本量有限的问题,导致诊断准确率不高。传统的金标准PSG方法则存在成本高昂、耗时过长以及患者体验不佳等痛点。
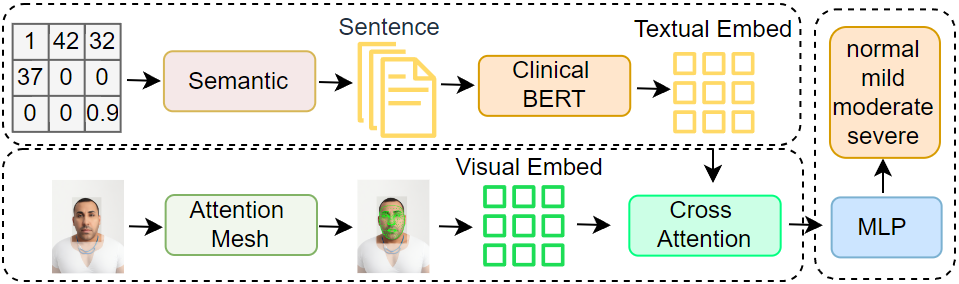
核心思路:论文的核心思路是利用多模态信息融合,结合面部图像的视觉特征和生理数据的语义信息,通过双编码器结构分别提取特征,并利用注意力机制进行特征融合,从而更全面、准确地进行OSAHS诊断。这种方法旨在弥补单一模态信息的不足,提高诊断的鲁棒性和准确性。
技术框架:整体框架包含以下几个主要模块:1) 数据预处理:使用randomOverSampler平衡数据;2) 特征提取:视觉编码器使用注意力网格提取面部图像的关键特征,文本编码器将生理数据转换为文本并提取语义特征;3) 特征融合:使用交叉注意力机制融合视觉和文本特征;4) 分类:使用分类器进行OSAHS严重程度分类。
关键创新:论文的关键创新在于多模态信息的融合以及注意力机制的应用。与现有方法相比,该方法不仅利用了面部图像信息,还结合了生理数据信息,从而更全面地反映了OSAHS的特征。同时,注意力机制能够帮助模型关注关键的面部区域和生理指标,提高特征提取的效率和准确性。
关键设计:论文的关键设计包括:1) 使用注意力网格提取面部特征,能够更有效地关注关键面部区域;2) 将生理数据转换为文本,便于与视觉特征进行融合;3) 使用交叉注意力机制融合视觉和文本特征,实现模态间的有效交互;4) 使用有序回归损失函数,确保模型学习的稳定性,并更好地处理OSAHS严重程度的有序关系。
🖼️ 关键图片

📊 实验亮点
该研究在四类OSAHS严重程度分类任务中取得了91.3%的top-1准确率,显著优于现有的基于面部图像分析的深度学习方法。实验结果表明,多模态信息融合和注意力机制的应用能够有效提高OSAHS诊断的准确性和鲁棒性。
🎯 应用场景
该研究成果可应用于OSAHS的初步筛查和诊断,降低诊断成本,提高诊断效率,尤其适用于医疗资源匮乏的地区。未来可进一步集成到智能睡眠监测设备或移动医疗应用中,实现OSAHS的居家监测和管理,提升患者的生活质量。
📄 摘要(原文)
Obstructive sleep apnea-hypopnea syndrome (OSAHS) is a common sleep disorder caused by upper airway blockage, leading to oxygen deprivation and disrupted sleep. Traditional diagnosis using polysomnography (PSG) is expensive, time-consuming, and uncomfortable. Existing deep learning methods using facial image analysis lack accuracy due to poor facial feature capture and limited sample sizes. To address this, we propose a multimodal dual encoder model that integrates visual and language inputs for automated OSAHS diagnosis. The model balances data using randomOverSampler, extracts key facial features with attention grids, and converts physiological data into meaningful text. Cross-attention combines image and text data for better feature extraction, and ordered regression loss ensures stable learning. Our approach improves diagnostic efficiency and accuracy, achieving 91.3% top-1 accuracy in a four-class severity classification task, demonstrating state-of-the-art performance. Code will be released upon acceptance.