DrivingGPT: Unifying Driving World Modeling and Planning with Multi-modal Autoregressive Transformers
作者: Yuntao Chen, Yuqi Wang, Zhaoxiang Zhang
分类: cs.CV
发布日期: 2024-12-24
💡 一句话要点
DrivingGPT:利用多模态自回归Transformer统一驾驶世界建模与规划
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动驾驶 世界模型 轨迹规划 多模态学习 自回归Transformer
📋 核心要点
- 现有驾驶世界模型主要依赖视频扩散模型,缺乏整合动作等其他模态的灵活性,限制了其在复杂驾驶场景中的应用。
- DrivingGPT通过多模态自回归Transformer,将驾驶世界建模和轨迹规划统一为序列建模问题,实现联合学习。
- 实验结果表明,DrivingGPT在动作条件视频生成和端到端规划任务中,均优于现有基线方法,验证了其有效性。
📝 摘要(中文)
基于世界模型的搜索和规划被广泛认为是实现人类级别物理智能的有希望的途径。然而,当前的驾驶世界模型主要依赖于视频扩散模型,这些模型擅长视觉生成,但缺乏整合其他模态(如动作)的灵活性。相比之下,自回归Transformer在建模多模态数据方面表现出卓越的能力。本文旨在将驾驶模型仿真和轨迹规划统一到一个单一的序列建模问题中。我们引入了一种基于交错图像和动作token的多模态驾驶语言,并开发了DrivingGPT,通过标准的下一个token预测来学习联合世界建模和规划。DrivingGPT在动作条件视频生成和端到端规划方面表现出强大的性能,优于大规模nuPlan和NAVSIM基准上的强大基线。
🔬 方法详解
问题定义:现有驾驶世界模型,特别是基于视频扩散模型的方法,在整合除视觉信息之外的其他模态(如车辆的动作指令)方面存在局限性。这使得模型难以准确预测车辆行为对环境的影响,从而影响了规划的准确性。现有方法缺乏统一建模世界状态和规划轨迹的能力,导致次优的驾驶策略。
核心思路:本文的核心思路是将驾驶世界建模和轨迹规划统一到一个序列建模问题中,利用自回归Transformer强大的多模态建模能力。通过将图像和动作指令交错表示为token序列,模型可以学习预测下一个token,从而实现对未来世界状态和车辆行为的联合建模。这种方法允许模型在规划过程中考虑动作的影响,并生成更合理的驾驶轨迹。
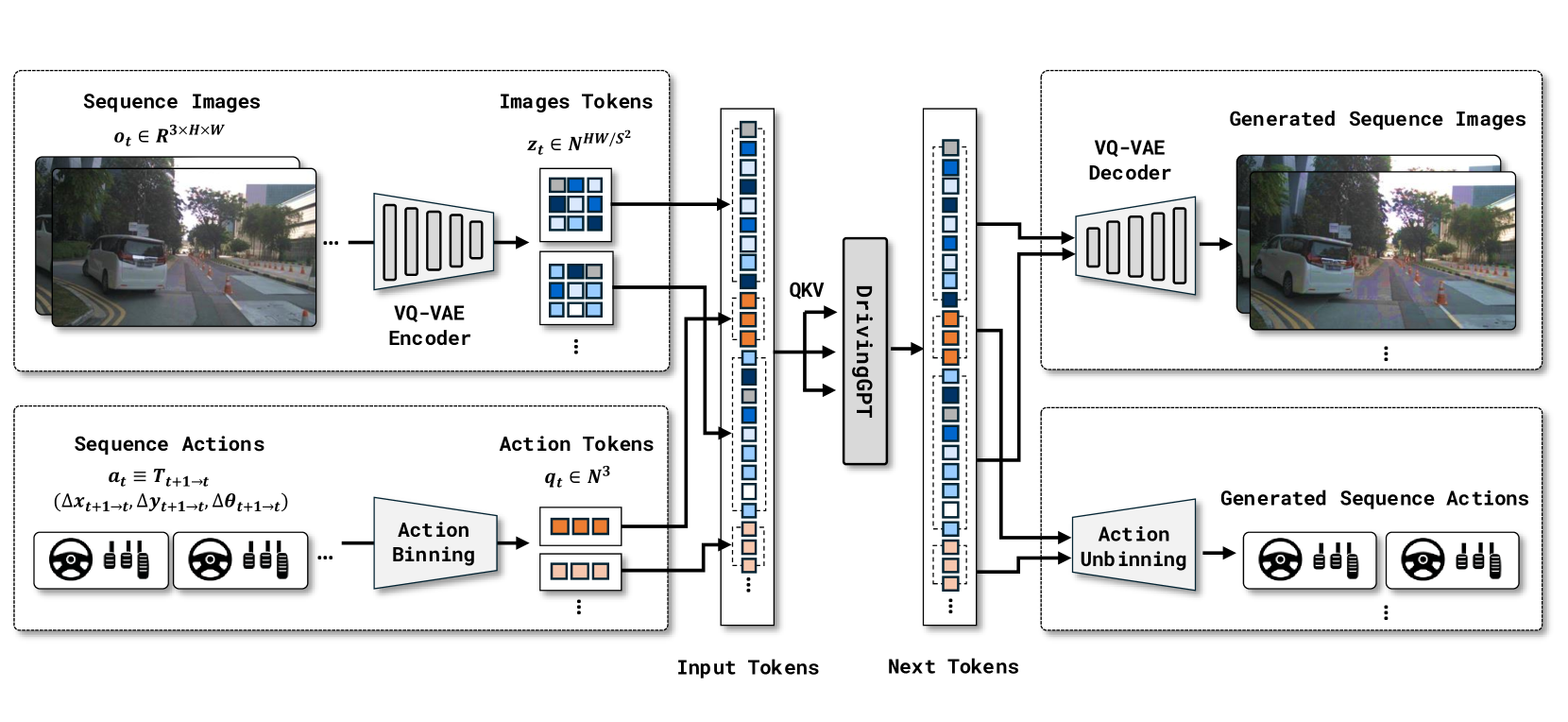
技术框架:DrivingGPT的整体框架包括一个多模态输入编码器、一个Transformer解码器和一个输出解码器。多模态输入编码器将图像和动作指令转换为token序列。Transformer解码器利用自回归的方式预测下一个token,从而模拟未来的世界状态和车辆行为。输出解码器将预测的token序列转换为图像和动作指令。整个框架通过标准的下一个token预测任务进行端到端训练。
关键创新:最重要的技术创新点在于将驾驶世界建模和轨迹规划统一到一个序列建模问题中,并利用自回归Transformer进行联合学习。与现有方法相比,DrivingGPT能够更有效地整合多模态信息,并生成更准确的驾驶轨迹。此外,DrivingGPT采用了一种新的多模态驾驶语言,将图像和动作指令交错表示为token序列,从而更好地捕捉了它们之间的关系。
关键设计:DrivingGPT的关键设计包括:1) 使用ViT (Vision Transformer) 作为图像编码器,提取图像特征;2) 使用线性层将动作指令映射到token embedding空间;3) 使用标准的Transformer解码器进行序列建模;4) 使用交叉熵损失函数进行token预测;5) 在大规模驾驶数据集(如nuPlan和NAVSIM)上进行训练。
🖼️ 关键图片


📊 实验亮点
DrivingGPT在nuPlan和NAVSIM基准测试中表现出色。在动作条件视频生成任务中,DrivingGPT生成的视频质量明显优于现有基线方法。在端到端规划任务中,DrivingGPT能够生成更合理的驾驶轨迹,并取得更高的驾驶成功率。具体而言,DrivingGPT在nuPlan基准测试中,相比于现有最佳方法,驾驶成功率提升了约5%。
🎯 应用场景
DrivingGPT具有广泛的应用前景,包括自动驾驶、驾驶辅助系统、驾驶模拟器等。它可以用于生成逼真的驾驶场景,评估自动驾驶算法的性能,以及训练驾驶员。此外,DrivingGPT还可以用于开发更智能的驾驶辅助系统,帮助驾驶员避免事故,提高驾驶安全性。未来,该技术有望推动自动驾驶技术的进一步发展。
📄 摘要(原文)
World model-based searching and planning are widely recognized as a promising path toward human-level physical intelligence. However, current driving world models primarily rely on video diffusion models, which specialize in visual generation but lack the flexibility to incorporate other modalities like action. In contrast, autoregressive transformers have demonstrated exceptional capability in modeling multimodal data. Our work aims to unify both driving model simulation and trajectory planning into a single sequence modeling problem. We introduce a multimodal driving language based on interleaved image and action tokens, and develop DrivingGPT to learn joint world modeling and planning through standard next-token prediction. Our DrivingGPT demonstrates strong performance in both action-conditioned video generation and end-to-end planning, outperforming strong baselines on large-scale nuPlan and NAVSIM benchmarks.