ZeroHSI: Zero-Shot 4D Human-Scene Interaction by Video Generation
作者: Hongjie Li, Hong-Xing Yu, Jiaman Li, Jiajun Wu
分类: cs.CV, cs.GR
发布日期: 2024-12-24 (更新: 2025-03-21)
备注: Project website: https://awfuact.github.io/zerohsi/ The first two authors contribute equally
💡 一句话要点
ZeroHSI:基于视频生成实现零样本4D人-场景交互
🎯 匹配领域: 支柱五:交互与反应 (Interaction & Reaction) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 人-场景交互 视频生成 零样本学习 可微渲染 4D场景
📋 核心要点
- 现有的人-场景交互生成方法依赖于大量配对的3D场景和动作捕捉数据,难以泛化到未见过的场景。
- ZeroHSI的核心思想是从大规模视频生成模型中提取知识,利用可微渲染重建人-场景交互,无需额外训练。
- ZeroHSI在包含各种室内外场景的数据集上进行了评估,展示了其生成多样且符合上下文的人-场景交互的能力。
📝 摘要(中文)
人-场景交互(HSI)生成对于具身智能、虚拟现实和机器人等应用至关重要。然而,现有方法无法在未见过的环境中(如野外场景或重建场景)合成交互,因为它们依赖于配对的3D场景和捕获的人体运动数据进行训练,而这些数据在未见过的环境中是不可用的。我们提出了ZeroHSI,一种新颖的方法,能够实现零样本4D人-场景交互合成,无需在任何动作捕捉数据上进行训练。我们的关键见解是从最先进的视频生成模型中提取人-场景交互,这些模型已经在大量自然人类运动和交互上进行了训练,并使用可微渲染来重建人-场景交互。ZeroHSI可以在静态场景和具有动态对象的环境中合成逼真的人类运动,而无需任何地面实况运动数据。我们在一个包含不同类型室内和室外场景以及不同交互提示的精选数据集上评估了ZeroHSI,证明了其生成多样化和上下文相关的人-场景交互的能力。
🔬 方法详解
问题定义:现有的人-场景交互生成方法需要大量的配对3D场景和动作捕捉数据进行训练,这限制了它们在真实世界场景中的应用,因为获取这些数据成本高昂且耗时。因此,如何在没有动作捕捉数据的情况下,在未见过的场景中生成逼真的人-场景交互是一个关键问题。
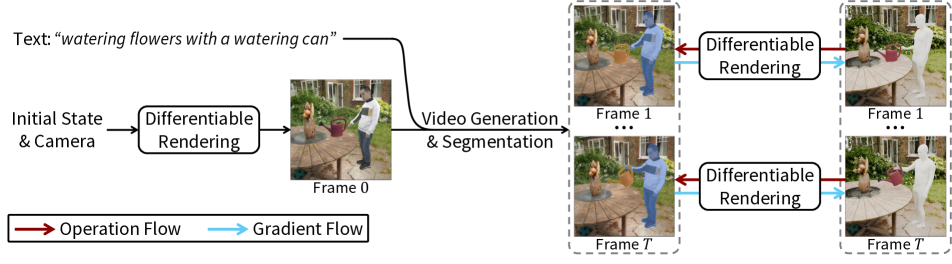
核心思路:ZeroHSI的核心思路是利用大规模视频生成模型中蕴含的丰富的人类运动和交互知识。这些模型已经在海量视频数据上进行了训练,学习到了自然的人类行为模式。通过从这些模型中提取知识,并结合可微渲染技术,ZeroHSI可以在新的场景中合成逼真的人-场景交互,而无需任何额外的训练数据。
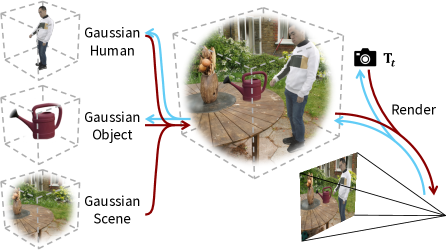
技术框架:ZeroHSI的整体框架包括以下几个主要模块:1) 使用预训练的视频生成模型(例如,基于扩散模型的视频生成器)生成包含人类运动的视频片段。2) 使用可微渲染引擎将生成的视频片段投影到3D场景中,从而创建4D的人-场景交互。3) 通过优化渲染参数,例如相机姿态和光照条件,来提高合成交互的真实感。
关键创新:ZeroHSI最重要的技术创新点在于它实现了零样本的人-场景交互生成。与现有方法不同,ZeroHSI不需要在任何动作捕捉数据上进行训练。它通过从预训练的视频生成模型中提取知识,并结合可微渲染技术,实现了在未见过的场景中合成逼真的人-场景交互。
关键设计:ZeroHSI的关键设计包括:1) 使用大规模视频生成模型作为知识来源,确保生成的人类运动具有自然性和多样性。2) 使用可微渲染引擎,使得可以对渲染参数进行优化,从而提高合成交互的真实感。3) 设计了一种损失函数,用于衡量合成交互的真实性和一致性,并指导渲染参数的优化。
🖼️ 关键图片

📊 实验亮点
ZeroHSI在各种室内和室外场景中进行了评估,结果表明,它能够生成多样化和上下文相关的人-场景交互。与现有的基于动作捕捉的方法相比,ZeroHSI在视觉质量和真实感方面具有竞争力,并且不需要任何训练数据。此外,ZeroHSI还能够处理具有动态对象的场景,这进一步扩展了其应用范围。
🎯 应用场景
ZeroHSI在虚拟现实、增强现实、机器人和游戏等领域具有广泛的应用前景。例如,它可以用于创建逼真的虚拟环境,用于训练机器人,或者用于生成交互式游戏内容。该研究的实际价值在于降低了人-场景交互生成的成本和难度,使得更多的人可以参与到虚拟世界的创造中。未来,ZeroHSI可以进一步扩展到更复杂的场景和交互类型,例如多人交互和物体操作。
📄 摘要(原文)
Human-scene interaction (HSI) generation is crucial for applications in embodied AI, virtual reality, and robotics. Yet, existing methods cannot synthesize interactions in unseen environments such as in-the-wild scenes or reconstructed scenes, as they rely on paired 3D scenes and captured human motion data for training, which are unavailable for unseen environments. We present ZeroHSI, a novel approach that enables zero-shot 4D human-scene interaction synthesis, eliminating the need for training on any MoCap data. Our key insight is to distill human-scene interactions from state-of-the-art video generation models, which have been trained on vast amounts of natural human movements and interactions, and use differentiable rendering to reconstruct human-scene interactions. ZeroHSI can synthesize realistic human motions in both static scenes and environments with dynamic objects, without requiring any ground-truth motion data. We evaluate ZeroHSI on a curated dataset of different types of various indoor and outdoor scenes with different interaction prompts, demonstrating its ability to generate diverse and contextually appropriate human-scene interactions.