RDPM: Solve Diffusion Probabilistic Models via Recurrent Token Prediction
作者: Xiaoping Wu, Jie Hu, Xiaoming Wei
分类: cs.CV, cs.AI, cs.LG, cs.MM
发布日期: 2024-12-24 (更新: 2024-12-25)
备注: 8 pages
💡 一句话要点
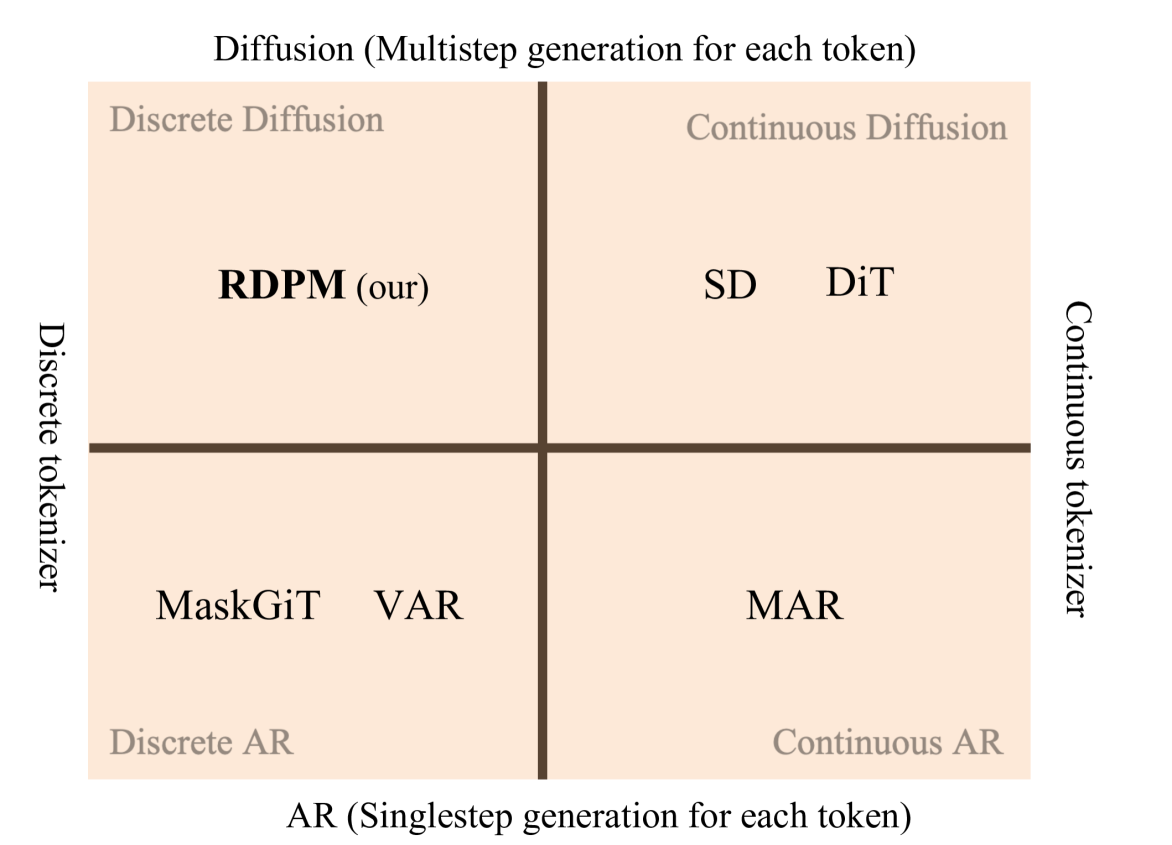
提出RDPM:通过循环token预测解决扩散概率模型,实现离散扩散。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散概率模型 离散扩散 循环token预测 图像生成 多模态生成
📋 核心要点
- 现有DPMs主要在连续潜在空间进行扩散,与LLMs的离散token生成方式差异大,限制了多模态统一建模。
- RDPM通过循环token预测机制,将连续信号转换为离散token,实现了离散扩散,并与GPT风格模型保持一致的优化策略。
- RDPM在图像生成任务上表现出优越性能,同时仅需少量推理步骤,具有速度优势,为多模态统一建模奠定基础。
📝 摘要(中文)
扩散概率模型(DPMs)已成为高保真图像合成的事实标准,它在连续VAE潜在空间上运行扩散过程,这与大型语言模型(LLMs)采用的文本生成方法显著不同。本文提出了一种新的生成框架——循环扩散概率模型(RDPM),通过循环token预测机制增强扩散过程,从而开创了离散扩散领域。RDPM通过逐步将高斯噪声引入图像的潜在表示,并以循环方式将其编码为矢量量化token,从而促进了离散值域上的独特扩散过程。该过程迭代地预测后续时间步的token代码,将初始标准高斯噪声转换为源数据分布,在损失函数方面与GPT风格的模型保持一致。RDPM展示了卓越的性能,同时受益于仅需少量推理步骤的速度优势。该模型不仅利用扩散过程来确保高质量生成,还将连续信号转换为一系列高保真离散token,从而与其他离散token(如文本)保持统一的优化策略。我们预计这项工作将有助于开发用于多模态生成的统一模型,特别是将图像、视频和音频等连续信号域与文本集成。我们将向开源社区发布代码和模型权重。
🔬 方法详解
问题定义:现有扩散概率模型主要在连续的潜在空间上进行操作,这与大型语言模型在离散token上的操作方式存在显著差异。这种差异使得将图像、视频和音频等连续信号与文本等离散信号进行统一建模变得困难。现有方法难以兼顾生成质量和推理速度,并且缺乏与现有离散token模型(如GPT)的统一优化策略。
核心思路:RDPM的核心思路是将连续的图像信号转换为离散的token序列,然后在这些离散token上进行扩散过程。通过循环token预测机制,模型能够逐步预测后续时间步的token代码,从而将初始的高斯噪声转换为源数据分布。这种方式使得RDPM能够利用扩散过程生成高质量的图像,同时保持与离散token模型(如GPT)的优化策略一致。
技术框架:RDPM的整体框架包括以下几个主要步骤:1) 将图像编码为潜在表示;2) 将潜在表示矢量量化为离散token;3) 在离散token上进行扩散过程,逐步添加高斯噪声;4) 通过循环token预测机制,迭代预测后续时间步的token代码,从而实现从噪声到图像的生成过程。该框架的关键在于循环token预测机制,它允许模型逐步细化生成的图像,并保持与离散token模型的兼容性。
关键创新:RDPM最重要的创新点在于它实现了离散扩散。通过将连续信号转换为离散token,RDPM能够在离散值域上进行扩散过程,这与传统的在连续潜在空间上进行扩散的方法有本质区别。这种离散扩散的方式使得RDPM能够与现有的离散token模型(如GPT)进行统一建模,从而为多模态生成提供了一种新的可能性。
关键设计:RDPM的关键设计包括:1) 使用矢量量化(VQ)将连续的潜在表示转换为离散token;2) 使用循环神经网络(RNN)进行token预测,从而实现循环token预测机制;3) 使用与GPT风格模型类似的损失函数,以保持与离散token模型的优化策略一致;4) 通过调整循环预测的步数,可以控制生成图像的质量和推理速度。
🖼️ 关键图片


📊 实验亮点
RDPM在图像生成任务上表现出优越的性能,并且仅需少量推理步骤即可生成高质量的图像。具体性能数据和对比基线在论文中给出,表明RDPM在生成质量和推理速度方面都优于现有方法。此外,RDPM与GPT风格模型保持一致的优化策略,为多模态统一建模奠定了基础。
🎯 应用场景
RDPM的潜在应用领域包括图像生成、视频生成、音频生成以及多模态内容生成。该研究的实际价值在于提供了一种将连续信号与离散信号进行统一建模的方法,从而为多模态生成提供了一种新的可能性。未来,RDPM可以应用于开发更强大的多模态生成模型,例如可以根据文本描述生成图像或视频,或者根据图像生成相应的文本描述。
📄 摘要(原文)
Diffusion Probabilistic Models (DPMs) have emerged as the de facto approach for high-fidelity image synthesis, operating diffusion processes on continuous VAE latent, which significantly differ from the text generation methods employed by Large Language Models (LLMs). In this paper, we introduce a novel generative framework, the Recurrent Diffusion Probabilistic Model (RDPM), which enhances the diffusion process through a recurrent token prediction mechanism, thereby pioneering the field of Discrete Diffusion. By progressively introducing Gaussian noise into the latent representations of images and encoding them into vector-quantized tokens in a recurrent manner, RDPM facilitates a unique diffusion process on discrete-value domains. This process iteratively predicts the token codes for subsequent timesteps, transforming the initial standard Gaussian noise into the source data distribution, aligning with GPT-style models in terms of the loss function. RDPM demonstrates superior performance while benefiting from the speed advantage of requiring only a few inference steps. This model not only leverages the diffusion process to ensure high-quality generation but also converts continuous signals into a series of high-fidelity discrete tokens, thereby maintaining a unified optimization strategy with other discrete tokens, such as text. We anticipate that this work will contribute to the development of a unified model for multimodal generation, specifically by integrating continuous signal domains such as images, videos, and audio with text. We will release the code and model weights to the open-source community.