Expand VSR Benchmark for VLLM to Expertize in Spatial Rules
作者: Peijin Xie, Lin Sun, Bingquan Liu, Dexin Wang, Xiangzheng Zhang, Chengjie Sun, Jiajia Zhang
分类: cs.CV, cs.AI
发布日期: 2024-12-24
🔗 代码/项目: GITHUB
💡 一句话要点
扩展VSR基准以提升VLLM在空间规则上的能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉空间推理 视觉大语言模型 数据扩展 模型集成 空间定位图像
📋 核心要点
- 现有的视觉大语言模型在视觉位置推理方面存在过度依赖语言指令而忽视视觉信息的问题。
- 本文提出通过扩展数据集和改进模型结构来提升VLLM在视觉空间推理中的表现,特别是对视觉位置信息的敏感性。
- 实验结果表明,扩展后的模型VSRE在VSR测试集上的准确率提高了27%,并在多个评估基准上表现出色。
📝 摘要(中文)
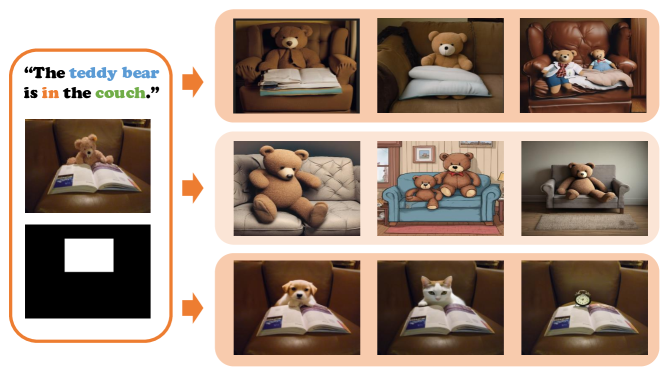
区分空间关系是人类认知的基本部分,需要对跨实例进行细致的感知。尽管现有基准如MME、MMBench和SEED已评估了多种能力,包括视觉空间推理(VSR),但针对视觉位置推理的评估和优化数据集仍然不足。为此,本文首先对现有的视觉大语言模型(VLLMs)进行了诊断,并提出了统一的测试集。研究发现,当前的VLLMs在语言指令上过于敏感,而对视觉位置信息的敏感性不足。通过从调优数据和模型结构两个方面扩展原始基准,缓解了这一现象。我们首次使用扩散模型可控地扩展了空间定位图像数据,并将原始视觉编码(CLIP)与其他三种强大的视觉编码器(SigLIP、SAM和DINO)集成。经过组合实验,我们获得了一个在不同指令上更具泛化能力的VLLM VSR专家(VSRE),其在VSR测试集上的准确率提高了27%以上。
🔬 方法详解
问题定义:本文旨在解决当前视觉大语言模型在视觉空间推理(VSR)中的不足,尤其是对视觉位置信息的敏感性不足,导致模型在实际应用中的表现不佳。
核心思路:通过扩展数据集和改进模型结构,增强模型对视觉信息的理解能力,减少其对语言指令的过度依赖,从而提升视觉空间推理的准确性。
技术框架:整体架构包括数据扩展模块和模型集成模块。数据扩展模块使用扩散模型生成空间定位图像数据,模型集成模块将CLIP与SigLIP、SAM和DINO等视觉编码器结合,以增强特征提取能力。
关键创新:首次使用扩散模型可控地扩展空间定位图像数据,并将多种视觉编码器集成,显著提升了模型对视觉位置信息的敏感性和推理能力。
关键设计:在参数设置上,优化了模型的学习率和损失函数,采用了多层次的特征融合策略,以确保不同视觉编码器的优势能够得到充分发挥。
🖼️ 关键图片


📊 实验亮点
实验结果显示,扩展后的VLLM VSR专家(VSRE)在VSR测试集上的准确率提高了27%以上,显著优于现有基线模型,展示了其在视觉位置推理任务中的卓越性能。
🎯 应用场景
该研究的潜在应用领域包括智能视觉系统、自动驾驶、机器人导航等,能够提升这些系统在复杂环境中的空间推理能力,具有重要的实际价值和广泛的应用前景。未来,随着VLLM技术的不断进步,预计将推动更多智能应用的发展。
📄 摘要(原文)
Distinguishing spatial relations is a basic part of human cognition which requires fine-grained perception on cross-instance. Although benchmarks like MME, MMBench and SEED comprehensively have evaluated various capabilities which already include visual spatial reasoning(VSR). There is still a lack of sufficient quantity and quality evaluation and optimization datasets for Vision Large Language Models(VLLMs) specifically targeting visual positional reasoning. To handle this, we first diagnosed current VLLMs with the VSR dataset and proposed a unified test set. We found current VLLMs to exhibit a contradiction of over-sensitivity to language instructions and under-sensitivity to visual positional information. By expanding the original benchmark from two aspects of tunning data and model structure, we mitigated this phenomenon. To our knowledge, we expanded spatially positioned image data controllably using diffusion models for the first time and integrated original visual encoding(CLIP) with other 3 powerful visual encoders(SigLIP, SAM and DINO). After conducting combination experiments on scaling data and models, we obtained a VLLM VSR Expert(VSRE) that not only generalizes better to different instructions but also accurately distinguishes differences in visual positional information. VSRE achieved over a 27\% increase in accuracy on the VSR test set. It becomes a performant VLLM on the position reasoning of both the VSR dataset and relevant subsets of other evaluation benchmarks. We open-sourced the expanded model with data and Appendix at \url{https://github.com/peijin360/vsre} and hope it will accelerate advancements in VLLM on VSR learning.