UniPLV: Towards Label-Efficient Open-World 3D Scene Understanding by Regional Visual Language Supervision
作者: Yuru Wang, Pei Liu, Songtao Wang, Zehan Zhang, Xinyan Lu, Changwei Cai, Hao Li, Fu Liu, Peng Jia, Xianpeng Lang
分类: cs.CV
发布日期: 2024-12-24 (更新: 2025-09-17)
💡 一句话要点
UniPLV:通过区域视觉语言监督实现标签高效的开放世界3D场景理解
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱三:空间感知与语义 (Perception & Semantics) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 开放世界场景理解 3D语义分割 多模态融合 视觉语言监督 点云处理 特征蒸馏 跨模态对齐
📋 核心要点
- 现有开放世界3D场景理解方法依赖大量人工标注的点云-文本对,且难以有效融合多模态数据。
- UniPLV利用图像作为桥梁,将点云、图像和文本嵌入到共享特征空间,避免了人工标注点云-文本对的需求。
- 实验结果表明,UniPLV在语义分割任务上显著超越现有方法,在Base-Annotated和Annotation-Free任务上分别提升15.6%和14.8%。
📝 摘要(中文)
开放世界3D场景理解是一项关键挑战,它涉及从点云等3D数据中识别和区分各种对象和类别,而无需手动标注。传统方法难以应对此开放世界任务,尤其是在构建广泛的点云-文本对以及有效处理多模态数据方面存在局限性。为了应对这些挑战,我们提出了UniPLV,一个强大的框架,它在单个学习范式中统一了点云、图像和文本,以实现全面的3D场景理解。UniPLV利用图像作为桥梁,将3D点与预先对齐的图像和文本共同嵌入到共享特征空间中,从而消除了劳动密集型的点云-文本对制作需求。我们的框架通过两种创新策略实现精确的多模态对齐:(i)图像和点云之间的logit和特征蒸馏模块,以增强特征一致性;(ii)视觉-点匹配模块,隐式校正受点到像素的投影不准确性影响的3D语义预测。为了进一步提高性能,我们实施了四个特定于任务的损失以及两阶段训练策略。大量实验表明,UniPLV显着超越了最先进的方法,在基本标注和无标注任务的语义分割方面分别平均提高了15.6%和14.8%。这些结果突显了UniPLV在推动开放世界3D场景理解边界方面的有效性。我们将发布代码以支持未来的研究和开发。
🔬 方法详解
问题定义:开放世界3D场景理解旨在识别和区分3D数据(如点云)中的各种对象和类别,而无需大量人工标注。现有方法的主要痛点在于需要构建大量的点云-文本对,这非常耗时耗力。此外,如何有效地融合点云、图像和文本等多模态数据也是一个挑战。
核心思路:UniPLV的核心思路是利用图像作为桥梁,将点云、图像和文本嵌入到一个共享的特征空间中。由于图像数据更容易获取和标注,因此可以通过图像来指导点云的特征学习,从而避免直接标注点云-文本对。这种设计能够有效利用现有的图像和文本数据,降低了标注成本。
技术框架:UniPLV的整体框架包含以下几个主要模块:1) 特征提取模块:分别提取点云、图像和文本的特征。2) 多模态对齐模块:利用图像作为桥梁,将点云和文本的特征与图像特征对齐。3) 语义分割模块:基于对齐后的特征进行3D场景的语义分割。4) 训练模块:采用两阶段训练策略,首先进行预训练,然后进行微调。
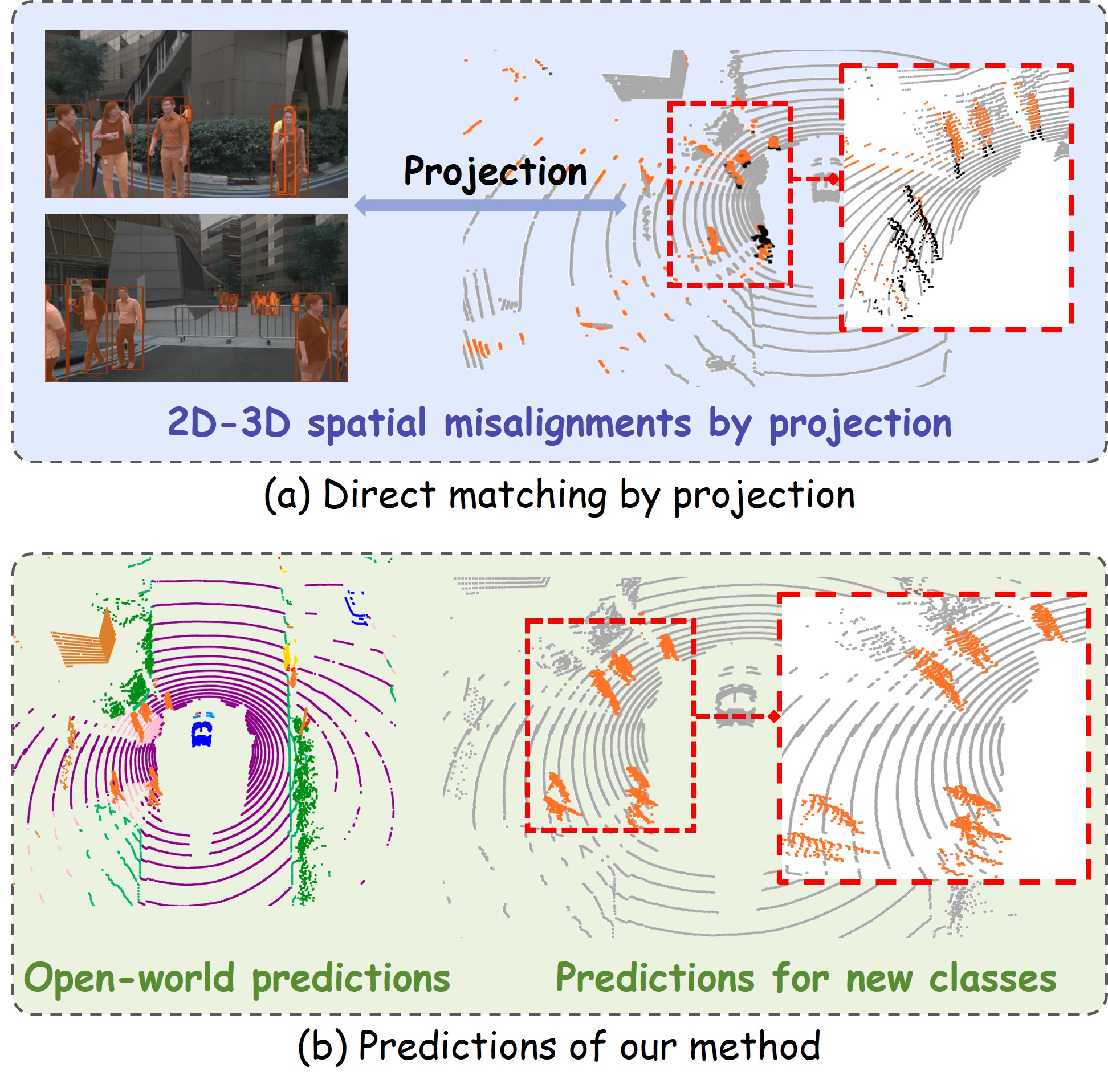
关键创新:UniPLV的关键创新在于其多模态对齐策略,具体包括:1) Logit和特征蒸馏模块:通过图像和点云之间的logit和特征蒸馏,增强特征的一致性。2) 视觉-点匹配模块:通过视觉-点匹配,隐式地校正由于点到像素的投影不准确性导致的3D语义预测误差。这种对齐策略能够有效地融合多模态信息,提高场景理解的准确性。
关键设计:UniPLV的关键设计包括:1) 两阶段训练策略:首先使用大量的图像和文本数据进行预训练,然后使用少量的点云数据进行微调。2) 任务特定的损失函数:除了标准的交叉熵损失外,还引入了四个特定于任务的损失函数,以进一步提高性能。3) 网络结构:采用了PointNet++作为点云特征提取器,ResNet作为图像特征提取器,BERT作为文本特征提取器。
🖼️ 关键图片


📊 实验亮点
UniPLV在开放世界3D场景理解任务上取得了显著的性能提升。在Base-Annotated任务上,UniPLV的语义分割性能平均提升了15.6%;在Annotation-Free任务上,平均提升了14.8%。这些结果表明,UniPLV能够有效地利用多模态信息,提高3D场景理解的准确性和鲁棒性,超越了现有的最先进方法。
🎯 应用场景
UniPLV在自动驾驶、机器人导航、虚拟现实和增强现实等领域具有广泛的应用前景。它可以帮助机器人更好地理解周围环境,从而实现更安全、更智能的交互。此外,该技术还可以应用于3D场景重建、城市规划和智能家居等领域,具有重要的实际价值和未来影响。
📄 摘要(原文)
Open-world 3D scene understanding is a critical challenge that involves recognizing and distinguishing diverse objects and categories from 3D data, such as point clouds, without relying on manual annotations. Traditional methods struggle with this open-world task, especially due to the limitations of constructing extensive point cloud-text pairs and handling multimodal data effectively. In response to these challenges, we present UniPLV, a robust framework that unifies point clouds, images, and text within a single learning paradigm for comprehensive 3D scene understanding. UniPLV leverages images as a bridge to co-embed 3D points with pre-aligned images and text in a shared feature space, eliminating the need for labor-intensive point cloud-text pair crafting. Our framework achieves precise multimodal alignment through two innovative strategies: (i) Logit and feature distillation modules between images and point clouds to enhance feature coherence; (ii) A vision-point matching module that implicitly corrects 3D semantic predictions affected by projection inaccuracies from points to pixels. To further boost performance, we implement four task-specific losses alongside a two-stage training strategy. Extensive experiments demonstrate that UniPLV significantly surpasses state-of-the-art methods, with average improvements of 15.6% and 14.8% in semantic segmentation for Base-Annotated and Annotation-Free tasks, respectively. These results underscore UniPLV's efficacy in pushing the boundaries of open-world 3D scene understanding. We will release the code to support future research and development.