Unveiling Visual Perception in Language Models: An Attention Head Analysis Approach
作者: Jing Bi, Junjia Guo, Yunlong Tang, Lianggong Bruce Wen, Zhang Liu, Chenliang Xu
分类: cs.CV
发布日期: 2024-12-24 (更新: 2025-11-11)
期刊: CVPR 2025 (IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025)
DOI: 10.1109/CVPR52734.2025.00391
💡 一句话要点
揭示语言模型中的视觉感知:一种基于注意力头的分析方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 大型语言模型 视觉感知 注意力机制 模型分析
📋 核心要点
- 现有语言模型在视觉理解方面存在局限性,缺乏对其内部机制的深入理解。
- 该研究通过分析注意力头,揭示了语言模型中专门负责视觉内容处理的特定模块。
- 实验结果表明,这些注意力头的行为与视觉token的关注度高度相关,验证了其视觉感知能力。
📝 摘要(中文)
多模态大型语言模型(MLLMs)在视觉理解方面取得了显著进展。本文旨在通过对4个模型家族和4个模型规模的系统研究,揭示语言模型如何有效地解释和处理视觉内容。研究发现了一类独特的注意力头,它们专门关注视觉内容。分析表明,这些注意力头的行为、注意力权重的分布以及它们对输入中视觉token的集中程度之间存在很强的相关性。这些发现加深了我们对LLM如何适应多模态任务的理解,展示了它们弥合文本和视觉理解之间差距的潜力。这项工作为开发能够处理多种模态的人工智能系统铺平了道路。
🔬 方法详解
问题定义:本文旨在解决多模态大型语言模型(MLLMs)如何理解和处理视觉信息的问题。现有的研究缺乏对语言模型内部视觉感知机制的深入理解,难以解释其在视觉任务中表现优异的原因。因此,需要一种方法来揭示语言模型中负责视觉信息处理的关键模块,并分析其工作原理。
核心思路:本文的核心思路是通过分析语言模型中的注意力头,寻找专门负责处理视觉信息的特定注意力头。通过观察这些注意力头的行为、注意力权重的分布以及它们对视觉token的关注程度,来推断其在视觉感知中的作用。这种方法基于注意力机制在Transformer模型中的重要性,认为关键的视觉信息处理过程会体现在注意力头的行为上。
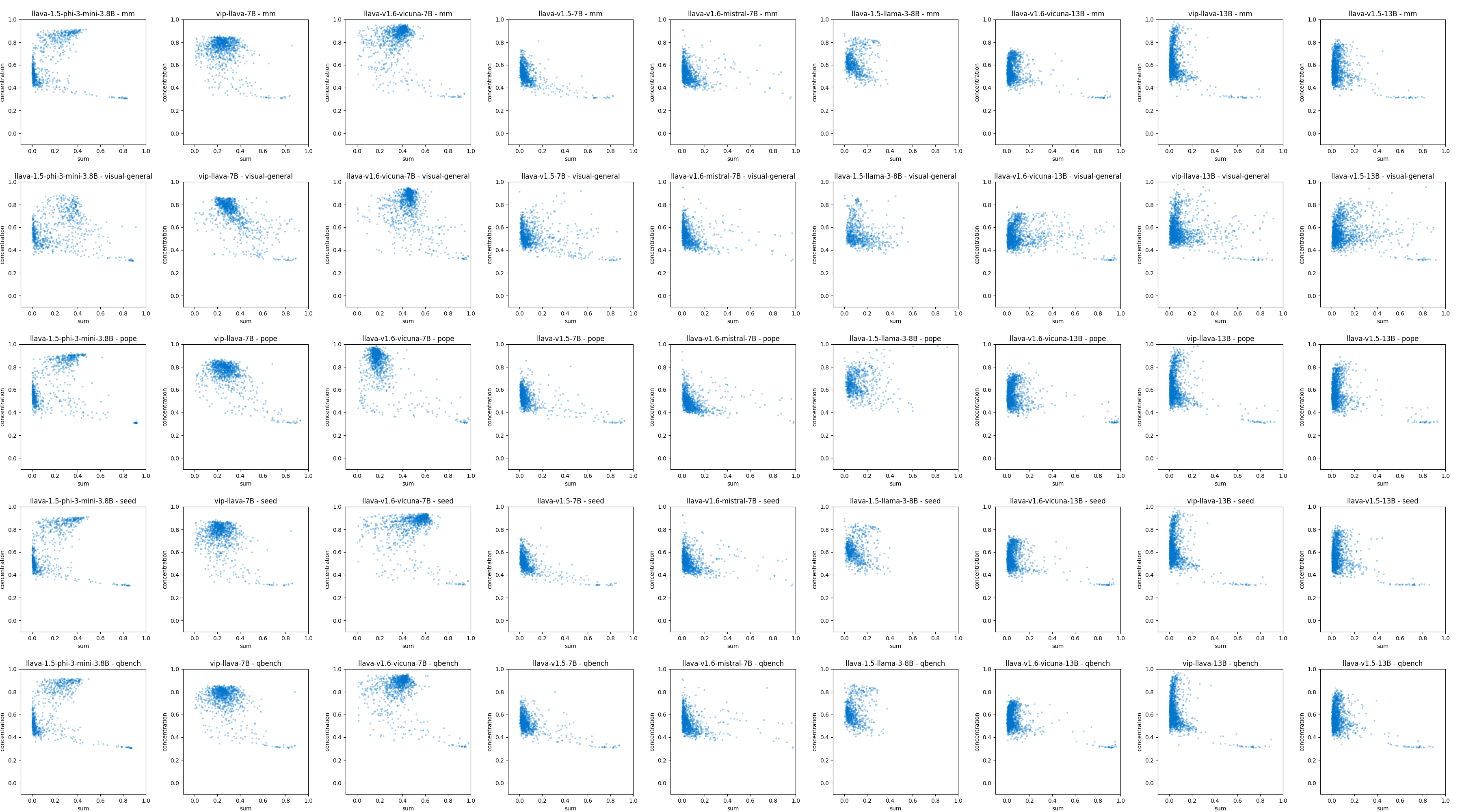
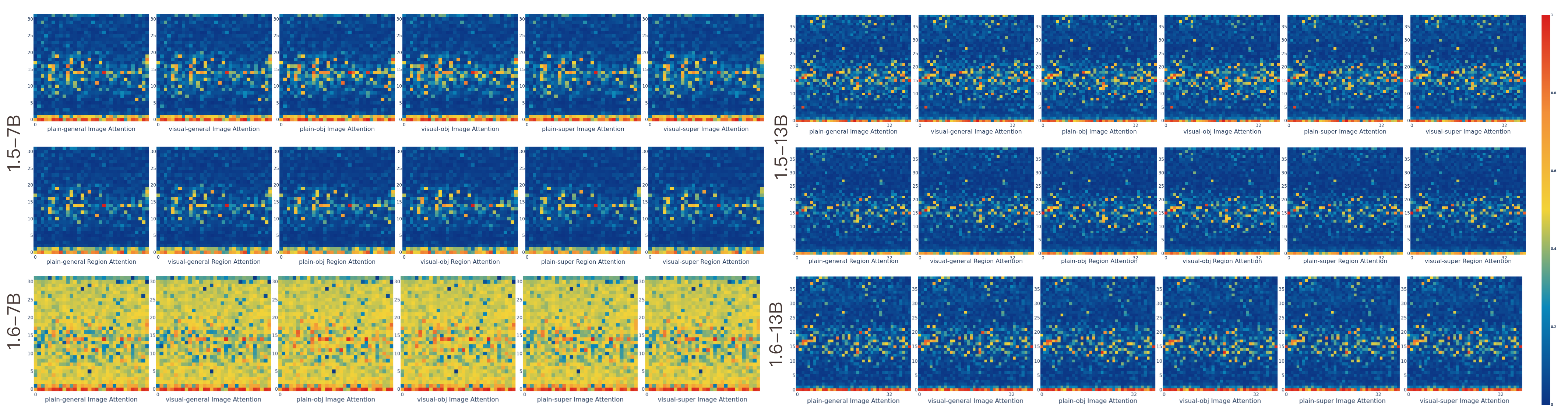
技术框架:本文的研究框架主要包括以下几个步骤:1) 选择多个不同规模和架构的MLLMs作为研究对象;2) 设计实验,输入包含视觉信息的文本提示,例如图像描述;3) 分析模型中所有注意力头的注意力权重分布,识别出对视觉token具有较高关注度的注意力头;4) 进一步分析这些注意力头的行为,例如与其他注意力头的交互、对不同视觉特征的响应等;5) 统计分析注意力头行为与模型性能之间的相关性。
关键创新:本文最重要的技术创新在于提出了一种基于注意力头分析的方法,用于揭示语言模型中的视觉感知机制。与以往主要关注模型输入输出的研究不同,本文深入到模型内部,通过分析注意力头的行为来理解其工作原理。这种方法为理解复杂模型的内部机制提供了一种新的视角。
关键设计:本文的关键设计包括:1) 选择具有代表性的MLLMs,覆盖不同的模型家族和规模,以保证研究结果的泛化性;2) 设计合适的实验输入,既要包含视觉信息,又要能够激发模型的视觉感知能力;3) 采用多种指标来量化注意力头的行为,例如注意力权重的熵、对不同视觉token的关注度等;4) 使用统计方法来分析注意力头行为与模型性能之间的相关性,例如相关系数、显著性检验等。
🖼️ 关键图片

📊 实验亮点
该研究通过对4个模型家族和4个模型规模的MLLM进行分析,发现了一类专门关注视觉内容的注意力头。研究表明,这些注意力头的行为与视觉token的关注度高度相关,证明了语言模型具备一定的视觉感知能力。这些发现为理解MLLM的内部机制提供了新的视角。
🎯 应用场景
该研究成果可应用于提升多模态大型语言模型的视觉理解能力,例如改进图像描述生成、视觉问答等任务的性能。此外,该研究方法也可用于分析其他模态信息的处理机制,为开发更通用的人工智能系统提供理论基础。未来,该研究有望促进人机交互、智能机器人等领域的发展。
📄 摘要(原文)
Recent advancements in Multimodal Large Language Models (MLLMs) have demonstrated remarkable progress in visual understanding. This impressive leap raises a compelling question: how can language models, initially trained solely on linguistic data, effectively interpret and process visual content? This paper aims to address this question with systematic investigation across 4 model families and 4 model scales, uncovering a unique class of attention heads that focus specifically on visual content. Our analysis reveals a strong correlation between the behavior of these attention heads, the distribution of attention weights, and their concentration on visual tokens within the input. These findings enhance our understanding of how LLMs adapt to multimodal tasks, demonstrating their potential to bridge the gap between textual and visual understanding. This work paves the way for the development of AI systems capable of engaging with diverse modalities.