MMFactory: A Universal Solution Search Engine for Vision-Language Tasks
作者: Wan-Cyuan Fan, Tanzila Rahman, Leonid Sigal
分类: cs.CV, cs.AI, cs.CL, cs.LG
发布日期: 2024-12-24
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
MMFactory:面向视觉-语言任务的通用解决方案搜索引擎
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言任务 解决方案搜索引擎 模型路由 多智能体LLM 程序合成 用户约束 自动化 通用框架
📋 核心要点
- 现有视觉-语言模型难以兼顾所有任务和用户需求,且忽略了用户对性能和计算资源的约束。
- MMFactory通过模型和指标路由,结合用户约束,从模型库中搜索并组合视觉-语言工具,生成定制化解决方案。
- MMFactory采用基于委员会的解决方案提议器,利用多智能体LLM对话生成更通用、鲁棒的解决方案,实验结果优于现有方法。
📝 摘要(中文)
随着基础模型和视觉-语言模型的进步,以及有效的微调技术,大量通用和专用模型被开发用于各种视觉任务。尽管这些模型具有灵活性和可访问性,但没有一个单一模型能够处理潜在用户设想的所有任务和/或应用。最近的方法,如视觉编程和具有集成工具的多模态LLM,旨在通过程序合成来解决复杂的视觉任务。然而,这些方法忽略了用户约束(例如,性能/计算需求),产生难以部署的测试时样本特定解决方案,并且有时需要可能超出普通用户能力的低级指令。为了解决这些限制,我们引入了MMFactory,一个通用框架,包括模型和指标路由组件,充当各种可用模型之间的解决方案搜索引擎。基于任务描述和少量样本输入-输出对以及(可选的)资源和/或性能约束,MMFactory可以通过实例化和组合来自其模型存储库的视觉-语言工具来建议各种程序化解决方案。除了合成这些解决方案之外,MMFactory还提出指标和基准性能/资源特征,允许用户选择满足其独特设计约束的解决方案。从技术角度来看,我们还引入了一种基于委员会的解决方案提议器,它利用多智能体LLM对话来为用户生成可执行、多样化、通用和强大的解决方案。实验结果表明,MMFactory通过提供根据用户问题规范量身定制的最先进的解决方案,优于现有方法。
🔬 方法详解
问题定义:现有视觉-语言模型虽然数量众多,但缺乏通用性,无法满足用户在性能、资源等方面的个性化需求。视觉编程等方法虽然可以解决复杂任务,但忽略了用户约束,且生成的解决方案难以部署,对用户技术水平要求高。
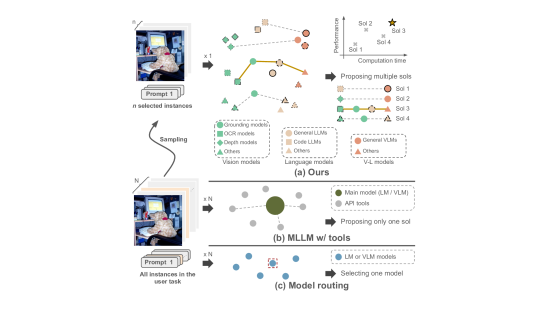
核心思路:MMFactory的核心思路是将各种视觉-语言模型和工具整合到一个统一的框架中,并根据用户提供的任务描述、示例以及资源/性能约束,自动搜索、组合这些模型和工具,生成满足用户需求的定制化解决方案。这种方法类似于一个解决方案搜索引擎,用户只需提供任务描述和约束,系统即可自动找到最佳解决方案。
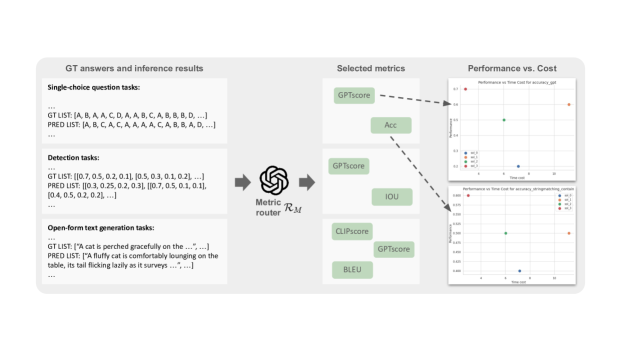
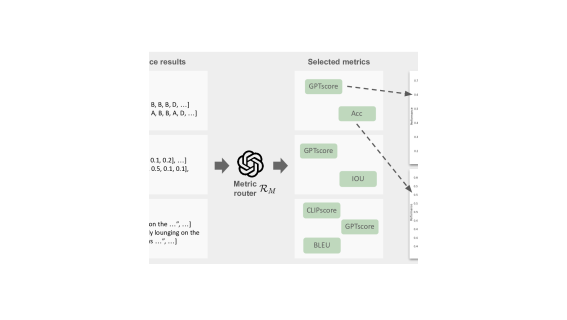
技术框架:MMFactory主要包含两个核心组件:模型和指标路由组件,以及基于委员会的解决方案提议器。模型和指标路由组件负责管理和索引各种视觉-语言模型和工具,并根据用户提供的任务描述和约束条件,筛选出合适的模型和工具。基于委员会的解决方案提议器则利用多智能体LLM对话,生成可执行的程序化解决方案,并评估其性能和资源消耗。整个流程包括:1) 接收用户任务描述和约束;2) 模型和指标路由组件筛选模型和工具;3) 解决方案提议器生成候选解决方案;4) 评估候选方案的性能和资源消耗;5) 向用户推荐最佳解决方案。
关键创新:MMFactory的关键创新在于其通用性和自动化程度。它不像传统方法那样需要人工选择和组合模型,而是可以根据用户需求自动搜索和组合模型,生成定制化解决方案。此外,基于委员会的解决方案提议器利用多智能体LLM对话,可以生成更通用、鲁棒的解决方案。
关键设计:MMFactory的关键设计包括:1) 如何有效地管理和索引大量的视觉-语言模型和工具;2) 如何根据用户提供的任务描述和约束条件,准确地筛选出合适的模型和工具;3) 如何利用多智能体LLM对话,生成可执行的程序化解决方案;4) 如何有效地评估候选方案的性能和资源消耗。具体的参数设置、损失函数、网络结构等技术细节在论文中未详细说明,属于未知内容。
🖼️ 关键图片
📊 实验亮点
实验结果表明,MMFactory在各种视觉-语言任务上都取得了优于现有方法的结果。它能够根据用户提供的任务描述和约束条件,自动生成定制化的解决方案,并显著提高任务的性能和效率。具体的性能数据和提升幅度在论文中进行了详细的展示。
🎯 应用场景
MMFactory具有广泛的应用前景,例如智能客服、自动驾驶、医疗诊断等领域。它可以帮助用户快速构建定制化的视觉-语言应用,降低开发成本和技术门槛。未来,MMFactory可以进一步扩展到更多领域,例如自然语言处理、语音识别等,成为一个通用的解决方案搜索引擎。
📄 摘要(原文)
With advances in foundational and vision-language models, and effective fine-tuning techniques, a large number of both general and special-purpose models have been developed for a variety of visual tasks. Despite the flexibility and accessibility of these models, no single model is able to handle all tasks and/or applications that may be envisioned by potential users. Recent approaches, such as visual programming and multimodal LLMs with integrated tools aim to tackle complex visual tasks, by way of program synthesis. However, such approaches overlook user constraints (e.g., performance / computational needs), produce test-time sample-specific solutions that are difficult to deploy, and, sometimes, require low-level instructions that maybe beyond the abilities of a naive user. To address these limitations, we introduce MMFactory, a universal framework that includes model and metrics routing components, acting like a solution search engine across various available models. Based on a task description and few sample input-output pairs and (optionally) resource and/or performance constraints, MMFactory can suggest a diverse pool of programmatic solutions by instantiating and combining visio-lingual tools from its model repository. In addition to synthesizing these solutions, MMFactory also proposes metrics and benchmarks performance / resource characteristics, allowing users to pick a solution that meets their unique design constraints. From the technical perspective, we also introduced a committee-based solution proposer that leverages multi-agent LLM conversation to generate executable, diverse, universal, and robust solutions for the user. Experimental results show that MMFactory outperforms existing methods by delivering state-of-the-art solutions tailored to user problem specifications. Project page is available at https://davidhalladay.github.io/mmfactory_demo.