HumanVBench: Exploring Human-Centric Video Understanding Capabilities of MLLMs with Synthetic Benchmark Data
作者: Ting Zhou, Daoyuan Chen, Qirui Jiao, Bolin Ding, Yaliang Li, Ying Shen
分类: cs.CV, cs.AI
发布日期: 2024-12-23 (更新: 2025-03-12)
备注: 22 pages, 23 figures, 7 tables
💡 一句话要点
HumanVBench:提出用于评估MLLM类人视频理解能力的合成基准数据集。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视频理解 多模态学习 大型语言模型 情感识别 行为分析
📋 核心要点
- 现有视频理解基准侧重于物体和动作识别,忽略了人类情感、行为和跨模态对齐等细微之处。
- HumanVBench通过16个任务,从情感和行为两个维度,评估MLLM的类人视频理解能力。
- 该基准采用自动化流程生成高质量数据,并对22个SOTA模型进行评估,发现现有模型在跨模态和情感理解方面存在不足。
📝 摘要(中文)
多模态大型语言模型(MLLM)领域中,实现以人为中心的视频理解仍然是一个巨大的挑战。现有的基准主要强调对象和动作识别,常常忽略视频内容中人类情感、行为以及语音-视觉对齐的复杂细微之处。我们提出了HumanVBench,这是一个精心设计的创新基准,旨在弥合视频MLLM评估中的这些差距。HumanVBench包含16个精心设计的任务,探索两个主要维度:内在情感和外在表现,涵盖静态和动态、基本和复杂,以及单模态和跨模态方面。借助两个先进的自动化流程,分别用于视频标注和包含干扰项的QA生成,HumanVBench利用各种最先进(SOTA)技术来简化基准数据的合成和质量评估,最大限度地减少对以人为中心的多模态属性的人工标注依赖。对22个SOTA视频MLLM的全面评估揭示了当前性能的显著局限性,尤其是在跨模态和情感感知方面,强调了进一步改进以实现更类人理解的必要性。HumanVBench已开源,以促进视频MLLM的未来发展和实际应用。
🔬 方法详解
问题定义:现有视频理解基准数据集主要关注物体和动作识别,缺乏对人类情感、行为以及语音-视觉对齐等更高级语义信息的评估。这使得评估多模态大语言模型(MLLM)在理解人类行为和情感方面的能力变得困难。现有方法依赖大量人工标注,成本高昂且难以扩展。
核心思路:HumanVBench的核心思路是构建一个合成的、以人为中心的视频理解基准数据集,该数据集能够自动生成高质量的标注和问答对,从而减少对人工标注的依赖。通过精心设计的任务,覆盖人类情感和行为的多个维度,全面评估MLLM的类人视频理解能力。
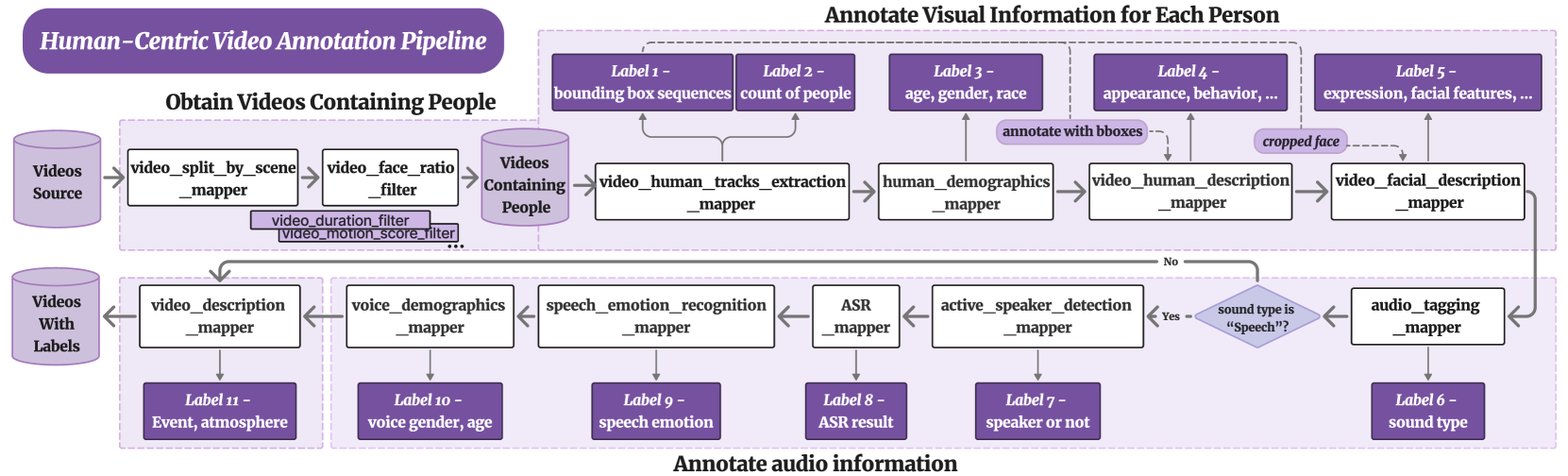
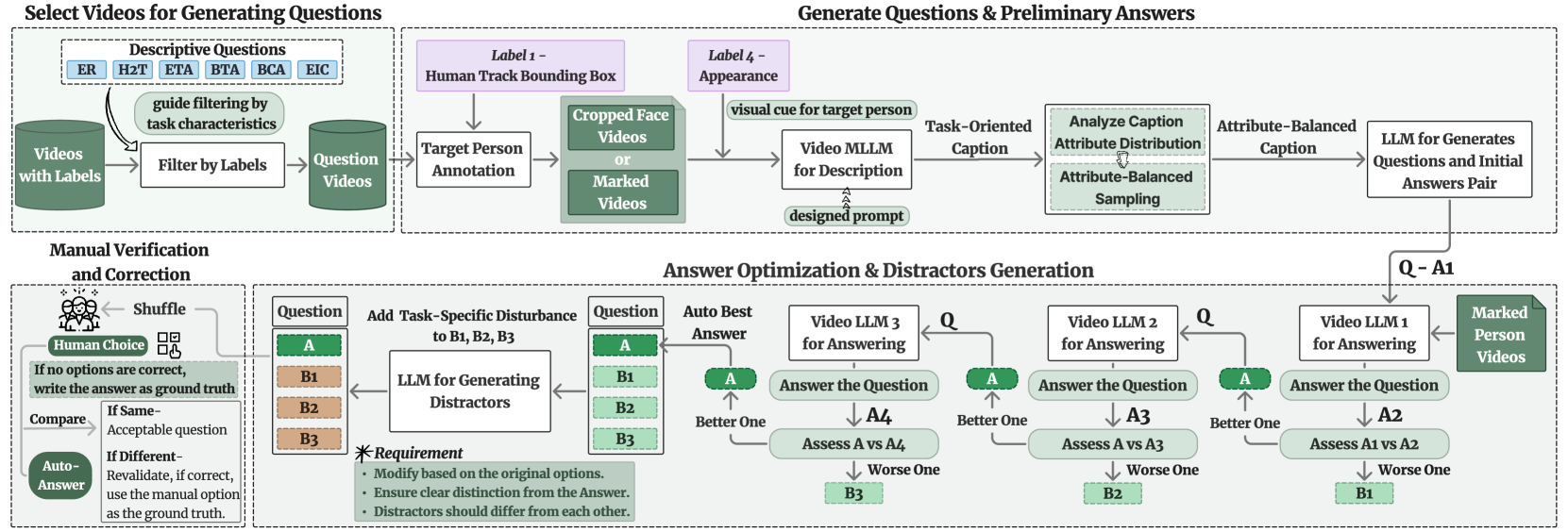
技术框架:HumanVBench的整体框架包括以下几个主要模块:1) 视频数据合成:利用现有的视频数据集和生成模型,生成包含人类行为和情感的视频片段。2) 视频标注:采用先进的自动化标注pipeline,对视频中的人类情感、行为、语音等信息进行标注。3) 问答对生成:设计包含干扰项的问答对生成pipeline,用于评估MLLM的理解能力。4) 评估指标:定义一系列评估指标,用于衡量MLLM在不同任务上的性能。
关键创新:HumanVBench的关键创新在于其自动化数据生成和标注pipeline,能够高效地生成高质量的、以人为中心的视频理解数据。此外,该基准数据集的任务设计涵盖了人类情感和行为的多个维度,能够更全面地评估MLLM的类人视频理解能力。与现有方法相比,HumanVBench显著减少了对人工标注的依赖,降低了数据收集和标注的成本。
关键设计:HumanVBench包含16个精心设计的任务,涵盖内在情感和外在表现两个维度,以及静态和动态、基本和复杂、单模态和跨模态等多个方面。自动化标注pipeline利用SOTA技术,如目标检测、情感识别和语音识别等,对视频进行标注。问答对生成pipeline采用对抗生成网络(GAN)生成包含干扰项的问答对,提高评估的鲁棒性。具体参数设置和网络结构细节在论文中有详细描述(未知)。
🖼️ 关键图片

📊 实验亮点
对22个SOTA视频MLLM的评估结果表明,现有模型在跨模态和情感感知方面存在显著局限性。例如,在情感识别任务上的准确率远低于人类水平。这些结果强调了进一步改进视频MLLM以实现更类人理解的必要性。HumanVBench的开源将促进相关研究的进展。
🎯 应用场景
HumanVBench可用于评估和提升视频MLLM在理解人类行为、情感和意图方面的能力,从而推动智能监控、人机交互、情感计算、心理健康分析等领域的发展。例如,可以应用于开发更智能的虚拟助手,能够理解用户的情感状态并做出相应的反应;也可以用于开发更有效的心理健康诊断工具,通过分析视频中的行为和情感来辅助诊断。
📄 摘要(原文)
In the domain of Multimodal Large Language Models (MLLMs), achieving human-centric video understanding remains a formidable challenge. Existing benchmarks primarily emphasize object and action recognition, often neglecting the intricate nuances of human emotions, behaviors, and speech-visual alignment within video content. We present HumanVBench, an innovative benchmark meticulously crafted to bridge these gaps in the evaluation of video MLLMs. HumanVBench comprises 16 carefully designed tasks that explore two primary dimensions: inner emotion and outer manifestations, spanning static and dynamic, basic and complex, as well as single-modal and cross-modal aspects. With two advanced automated pipelines for video annotation and distractor-included QA generation, HumanVBench utilizes diverse state-of-the-art (SOTA) techniques to streamline benchmark data synthesis and quality assessment, minimizing human annotation dependency tailored to human-centric multimodal attributes. A comprehensive evaluation across 22 SOTA video MLLMs reveals notable limitations in current performance, especially in cross-modal and emotion perception, underscoring the necessity for further refinement toward achieving more human-like understanding. HumanVBench is open-sourced to facilitate future advancements and real-world applications in video MLLMs.