The Dynamic Duo of Collaborative Masking and Target for Advanced Masked Autoencoder Learning
作者: Shentong Mo
分类: cs.CV, cs.AI, cs.LG, eess.IV, eess.SP
发布日期: 2024-12-23
💡 一句话要点
提出 CMT-MAE,通过协同掩码和目标提升掩码自编码器性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 掩码自编码器 自监督学习 协同学习 注意力机制 图像表示
📋 核心要点
- 现有MAE方法忽略了学生模型对教师模型在掩码和目标选择上的反馈作用,限制了自监督学习的潜力。
- CMT-MAE通过协同掩码机制,聚合教师和学生模型的注意力,并利用二者的输出特征作为解码器的协同目标。
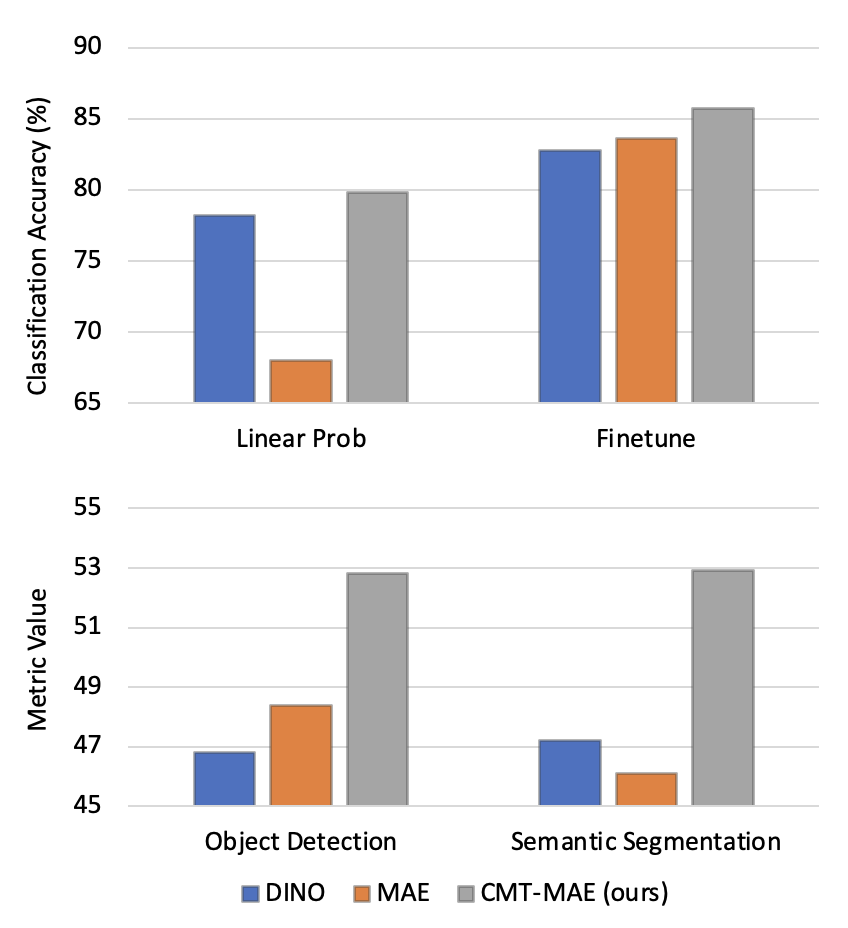
- 实验表明,CMT-MAE在ImageNet-1K上预训练后,线性探测和微调性能均达到SOTA,ViT-base微调结果提升至85.7%。
📝 摘要(中文)
本文提出了一种名为 CMT-MAE 的方法,旨在通过协同掩码和目标来提升掩码自编码器(MAE)的性能。先前的工作主要采用自定义(例如,随机、块状)掩码或教师模型(例如,CLIP)引导的掩码和目标,忽略了自训练(学生)模型在为教师模型提供掩码和目标反馈方面的潜在作用。CMT-MAE 利用一个简单的协同掩码机制,通过线性聚合教师和学生模型的注意力。此外,本文还提出使用这两个模型的输出特征作为解码器的协同目标。在 ImageNet-1K 上预训练的 CMT-MAE 框架,实现了最先进的线性探测和微调性能。特别是,使用 ViT-base,微调结果从原始 MAE 的 83.6% 提高到 85.7%。
🔬 方法详解
问题定义:现有的掩码自编码器(MAE)方法在掩码策略和目标选择上,通常依赖于预定义的规则(如随机掩码、块状掩码)或外部知识(如CLIP模型的指导)。这些方法忽略了自训练过程中学生模型所学习到的信息,未能充分利用学生模型对图像特征的理解来指导教师模型的掩码和目标选择,从而限制了模型的表示学习能力。
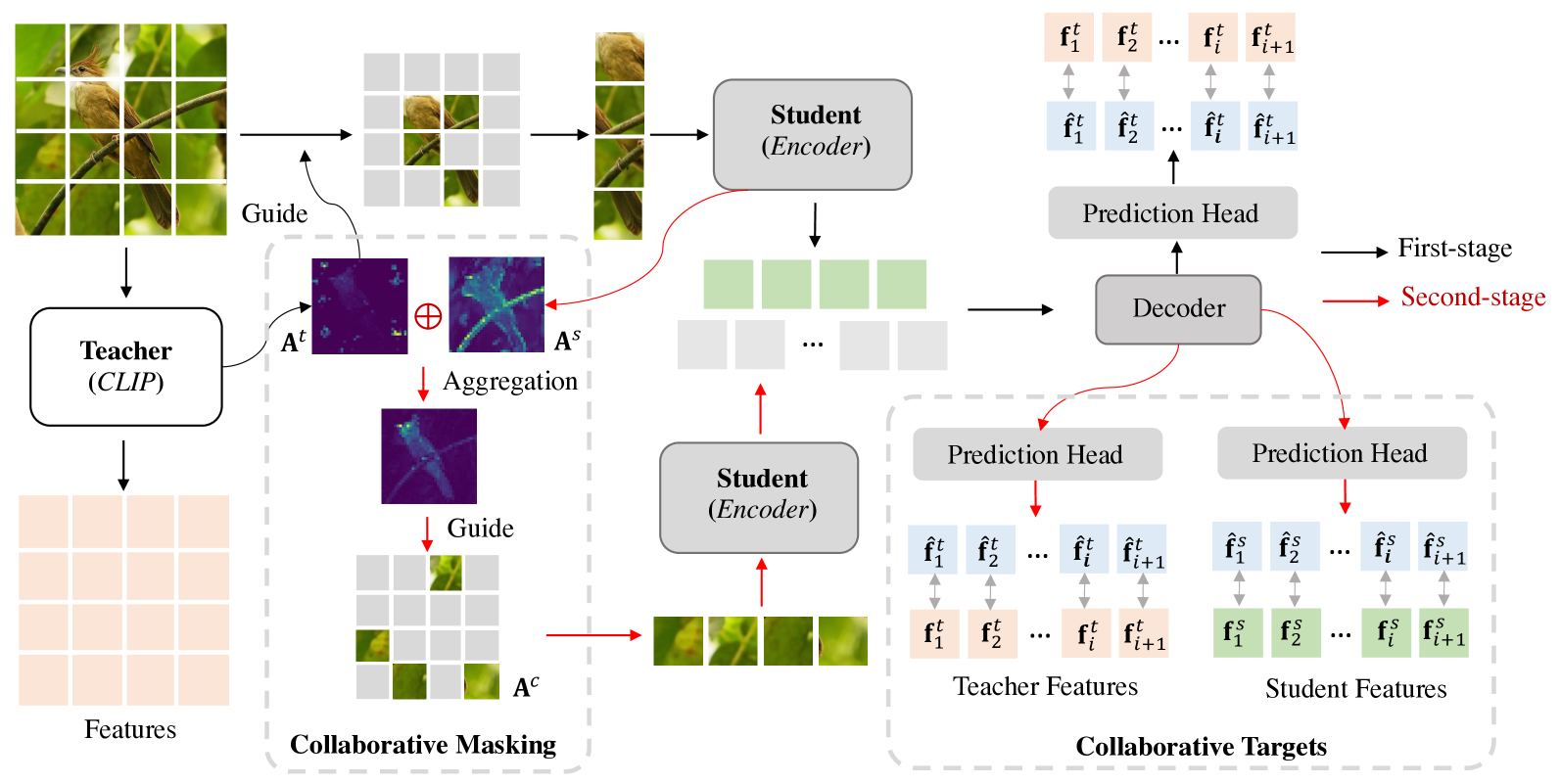
核心思路:CMT-MAE的核心思路是建立一个教师-学生模型的协同学习框架,让学生模型参与到掩码和目标的选择过程中。具体来说,通过聚合教师和学生模型的注意力信息,动态地调整掩码策略,使得模型能够更加关注重要的图像区域。同时,利用教师和学生模型的输出特征作为解码器的协同目标,从而提高解码器的重建质量和特征表达能力。
技术框架:CMT-MAE的整体框架包括一个教师模型和一个学生模型。首先,输入图像经过教师和学生模型的前向传播,得到各自的注意力图。然后,通过线性聚合教师和学生模型的注意力图,生成最终的掩码。接下来,被掩码的图像输入到学生模型的编码器中,得到编码后的特征表示。最后,解码器以教师和学生模型的输出特征作为协同目标,重建原始图像。
关键创新:CMT-MAE的关键创新在于引入了协同掩码和协同目标的概念。协同掩码通过聚合教师和学生模型的注意力信息,实现了动态的掩码策略,能够更加关注重要的图像区域。协同目标则利用教师和学生模型的输出特征,提高了解码器的重建质量和特征表达能力。与现有方法相比,CMT-MAE能够更好地利用自训练过程中的信息,从而提升模型的表示学习能力。
关键设计:在协同掩码方面,采用了简单的线性聚合方式,将教师和学生模型的注意力图进行加权平均。在协同目标方面,直接将教师和学生模型的输出特征拼接在一起,作为解码器的输入。损失函数采用常用的均方误差(MSE)损失函数,用于衡量重建图像与原始图像之间的差异。具体的权重参数和网络结构等超参数需要根据具体的实验进行调整。
🖼️ 关键图片
📊 实验亮点
CMT-MAE 在 ImageNet-1K 数据集上进行了预训练,并在多个下游任务上进行了评估。实验结果表明,CMT-MAE 在线性探测和微调性能上均达到了最先进水平。特别是,使用 ViT-base 作为骨干网络时,CMT-MAE 的微调结果从原始 MAE 的 83.6% 提高到 85.7%,提升了 2.1 个百分点。
🎯 应用场景
CMT-MAE 的潜在应用领域包括图像分类、目标检测、图像分割等计算机视觉任务。通过在大型数据集上进行预训练,CMT-MAE 可以学习到通用的图像表示,从而提高下游任务的性能。此外,该方法还可以应用于其他自监督学习场景,例如视频理解、自然语言处理等。
📄 摘要(原文)
Masked autoencoders (MAE) have recently succeeded in self-supervised vision representation learning. Previous work mainly applied custom-designed (e.g., random, block-wise) masking or teacher (e.g., CLIP)-guided masking and targets. However, they ignore the potential role of the self-training (student) model in giving feedback to the teacher for masking and targets. In this work, we present to integrate Collaborative Masking and Targets for boosting Masked AutoEncoders, namely CMT-MAE. Specifically, CMT-MAE leverages a simple collaborative masking mechanism through linear aggregation across attentions from both teacher and student models. We further propose using the output features from those two models as the collaborative target of the decoder. Our simple and effective framework pre-trained on ImageNet-1K achieves state-of-the-art linear probing and fine-tuning performance. In particular, using ViT-base, we improve the fine-tuning results of the vanilla MAE from 83.6% to 85.7%.