Two-in-One: Unified Multi-Person Interactive Motion Generation by Latent Diffusion Transformer
作者: Boyuan Li, Xihua Wang, Ruihua Song, Wenbing Huang
分类: cs.CV, cs.GR
发布日期: 2024-12-21
💡 一句话要点
提出基于潜在扩散Transformer的统一框架,解决多人交互运动生成难题。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion) 支柱八:物理动画 (Physics-based Animation)
关键词: 多人交互运动生成 扩散模型 变分自编码器 潜在空间 Transformer 自然语言条件 统一建模
📋 核心要点
- 现有方法通常使用独立模块分支处理个体运动,忽略了交互信息,增加了计算负担。
- 论文提出统一框架,将多人运动及其交互视为整体,在统一潜在空间中建模和生成。
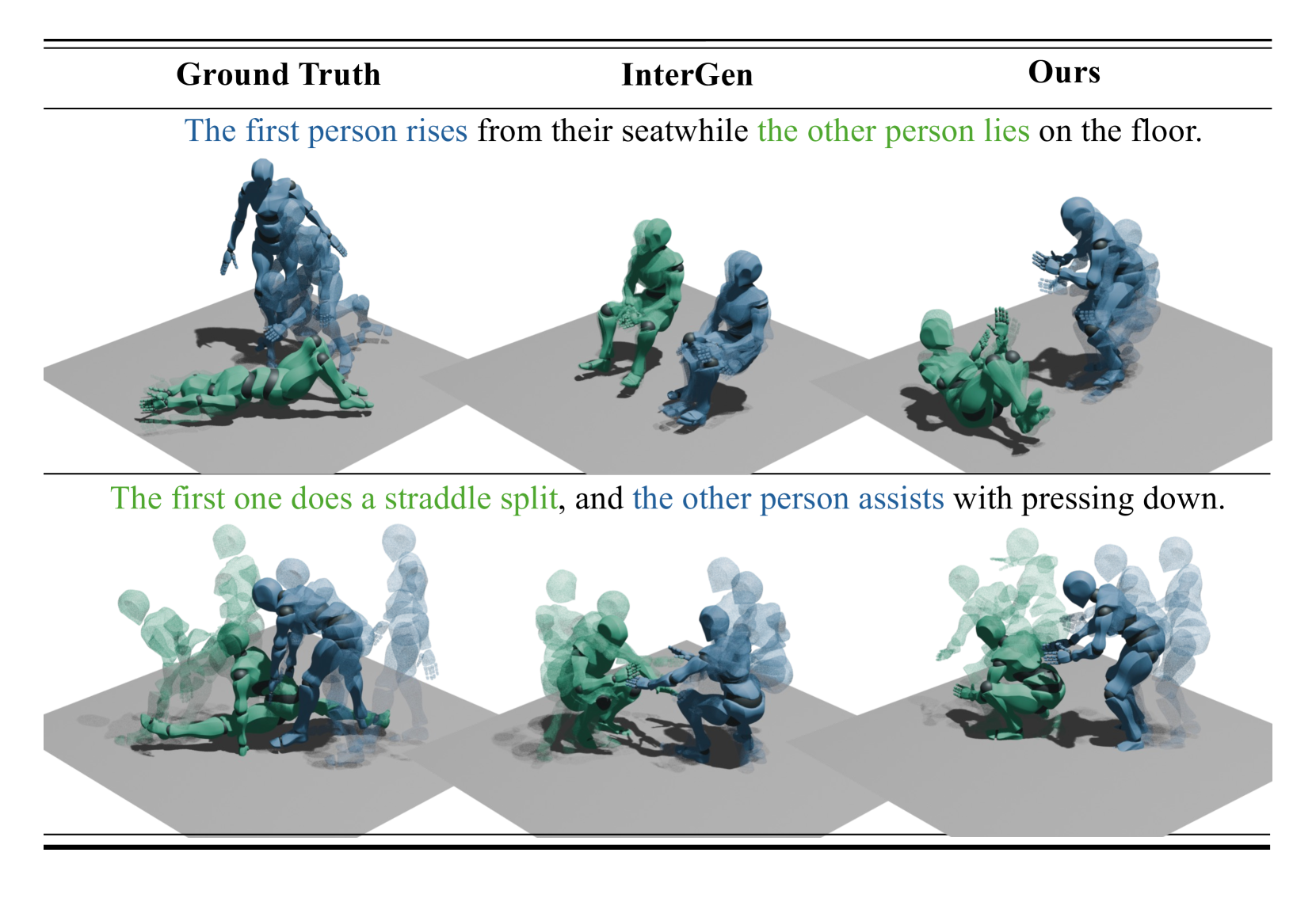
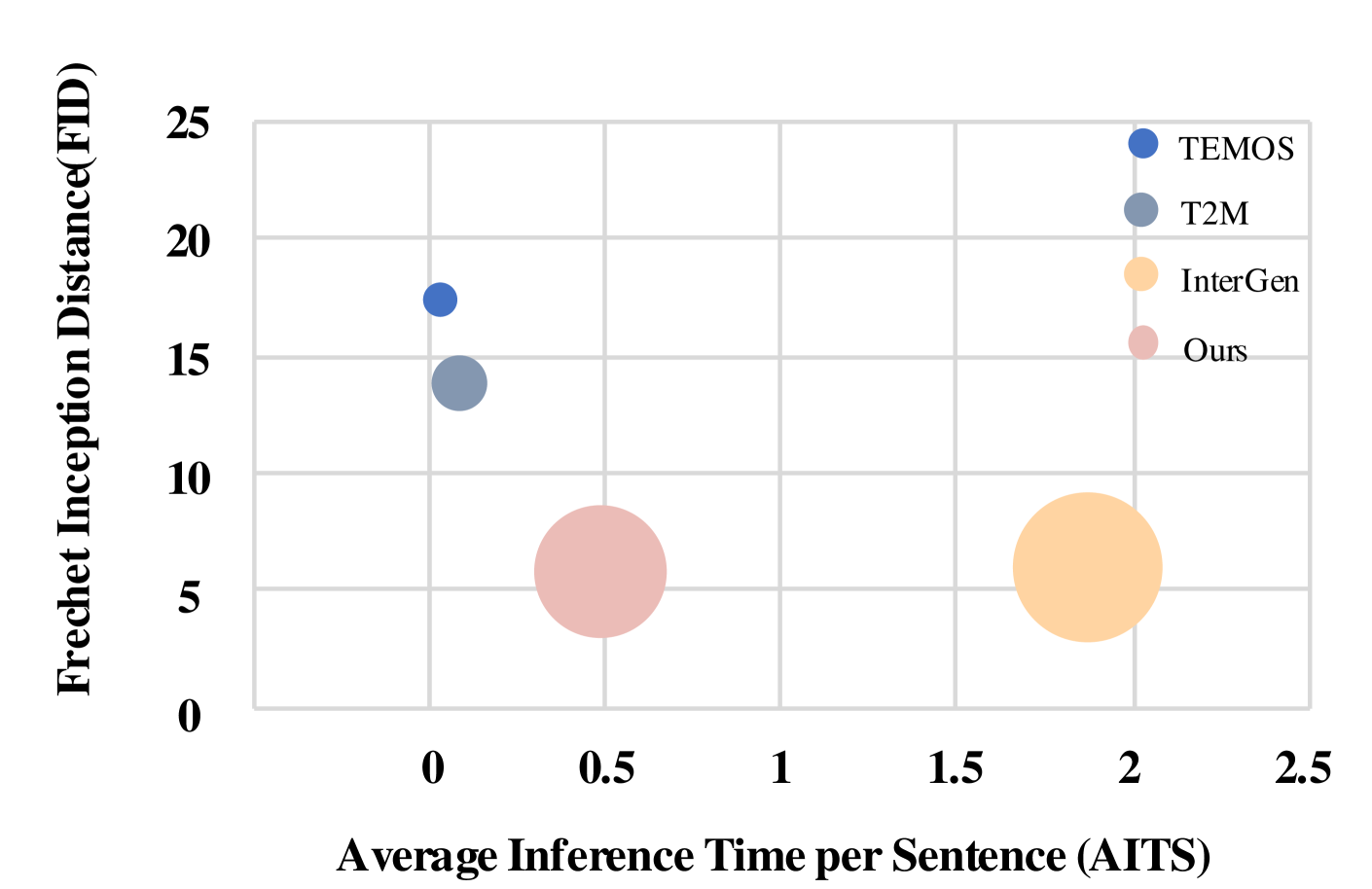
- 实验表明,该方法在生成质量、文本条件执行和生成效率方面均优于现有方法。
📝 摘要(中文)
本文提出了一种新颖的统一方法,用于多人交互运动生成,旨在解决现有方法在建模人际互动和生成差异巨大的运动时面临的挑战。该方法将多人运动及其交互建模在一个统一的潜在空间中,通过变分自编码器(VAE)将交互运动压缩到该空间,并在自然语言条件的引导下,在该空间内执行扩散过程。实验结果表明,该方法在生成质量方面优于现有方法,尤其是在运动具有显著不对称性时,能够更好地执行文本条件,并在保持高质量的同时提高生成效率。
🔬 方法详解
问题定义:论文旨在解决多人交互运动生成问题,现有方法通常采用分离的模块来处理每个人的运动,这导致了交互信息的丢失,并且增加了计算复杂度。此外,现有方法难以根据同一文本描述生成差异巨大的多人运动。
核心思路:论文的核心思路是将多人交互运动视为一个整体,而不是多个独立的个体运动的组合。通过将所有运动信息压缩到一个统一的潜在空间中,可以更好地捕捉人与人之间的交互关系,并更容易生成协调一致的运动。
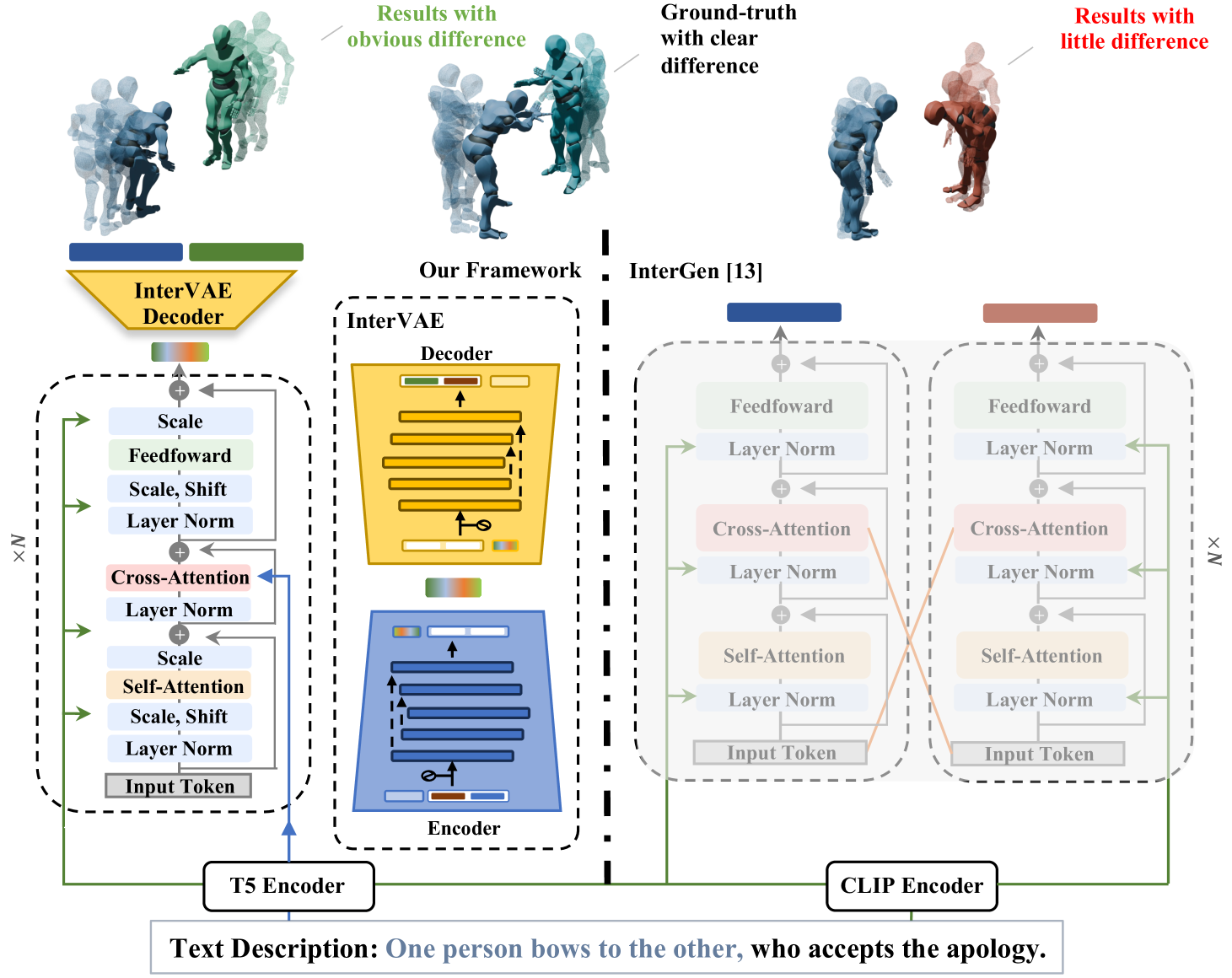
技术框架:该方法主要包含三个阶段:1) 使用变分自编码器(VAE)将多人交互运动数据压缩到一个统一的潜在空间中。2) 在该潜在空间中,使用扩散模型进行运动生成,扩散模型以自然语言描述作为条件。3) 使用VAE的解码器将潜在空间中的运动表示解码为实际的运动序列。
关键创新:该方法最重要的创新在于其统一的建模方式,它将多人运动及其交互信息整合到一个潜在空间中,避免了信息割裂。此外,使用扩散模型进行运动生成,可以生成更加多样化和高质量的运动。
关键设计:VAE采用标准结构,扩散模型采用Transformer架构,损失函数包括VAE的重构损失和扩散模型的噪声预测损失。具体的参数设置和网络结构细节在论文中有详细描述(未知)。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在生成质量方面优于现有方法,尤其是在运动具有显著不对称性时,能够更好地执行文本条件。此外,该方法在保持高质量的同时,提高了生成效率。具体的性能数据和对比基线在论文中有详细描述(未知)。
🎯 应用场景
该研究成果可应用于虚拟现实、游戏开发、电影制作等领域,能够根据文本描述自动生成逼真自然的多人交互动画,极大地提高内容创作的效率和质量。未来,该技术有望应用于机器人控制,使机器人能够更好地与人类进行协作。
📄 摘要(原文)
Multi-person interactive motion generation, a critical yet under-explored domain in computer character animation, poses significant challenges such as intricate modeling of inter-human interactions beyond individual motions and generating two motions with huge differences from one text condition. Current research often employs separate module branches for individual motions, leading to a loss of interaction information and increased computational demands. To address these challenges, we propose a novel, unified approach that models multi-person motions and their interactions within a single latent space. Our approach streamlines the process by treating interactive motions as an integrated data point, utilizing a Variational AutoEncoder (VAE) for compression into a unified latent space, and performing a diffusion process within this space, guided by the natural language conditions. Experimental results demonstrate our method's superiority over existing approaches in generation quality, performing text condition in particular when motions have significant asymmetry, and accelerating the generation efficiency while preserving high quality.