V"Mean"ba: Visual State Space Models only need 1 hidden dimension
作者: Tien-Yu Chi, Hung-Yueh Chiang, Chi-Chih Chang, Ning-Chi Huang, Kai-Chiang Wu
分类: cs.CV, cs.AI
发布日期: 2024-12-21
备注: Accepted by NeurIPS 2024 Machine Learning for Systems workshop
💡 一句话要点
VMeanba:通过通道均值化压缩视觉状态空间模型,加速图像处理。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 状态空间模型 模型压缩 通道均值化 图像分类 语义分割 视觉Transformer 计算加速
📋 核心要点
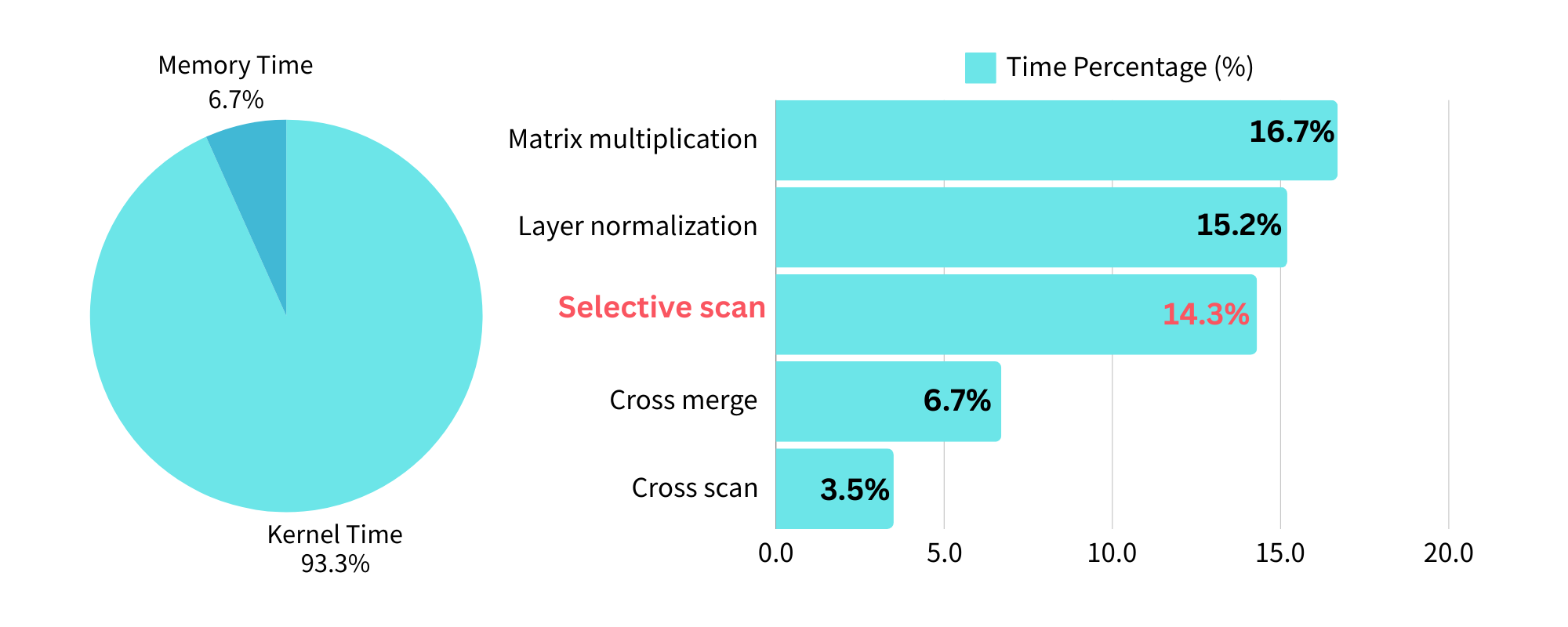
- 视觉Transformer计算复杂度高,难以在资源受限设备上部署,而状态空间模型(SSM)虽复杂度较低,但难以充分利用硬件。
- VMeanba通过观察SSM输出激活在通道上的低方差特性,采用通道均值化方法压缩模型,降低计算开销。
- 实验表明,VMeanba在图像分类和语义分割任务中实现了加速,且精度损失较小,结合剪枝后仍能保持良好性能。
📝 摘要(中文)
视觉Transformer在图像处理任务中表现出色,但自注意力的二次复杂度限制了其可扩展性和在资源受限设备上的部署。状态空间模型(SSM)通过引入线性递归机制提供了一种解决方案,将序列建模的复杂度从二次降低到线性。最近,SSM已被扩展到高分辨率视觉任务。然而,线性递归机制难以充分利用现代硬件上的矩阵乘法单元,导致计算瓶颈。本文提出VMeanba,一种免训练的压缩方法,通过均值操作消除SSM中的通道维度。关键观察是SSM块的输出激活在通道上表现出低方差。VMeanba利用这一特性,通过平均通道上的激活图来优化计算,从而在不影响准确性的前提下降低计算开销。在图像分类和语义分割任务上的评估表明,VMeanba实现了高达1.12倍的加速,而精度损失小于3%。与40%的非结构化剪枝相结合时,精度下降仍低于3%。
🔬 方法详解
问题定义:现有视觉Transformer模型计算复杂度高,难以部署在资源受限设备上。状态空间模型(SSM)虽然降低了计算复杂度,但其线性递归机制无法充分利用现代硬件的矩阵乘法单元,导致计算瓶颈。因此,需要一种方法来进一步降低SSM的计算开销,同时保持其性能。
核心思路:论文的核心思路是观察到SSM块的输出激活在通道维度上具有较低的方差。基于此,可以通过对通道维度进行均值化操作,从而消除通道维度,显著减少计算量。这种方法旨在通过牺牲少量精度来换取更高的计算效率。
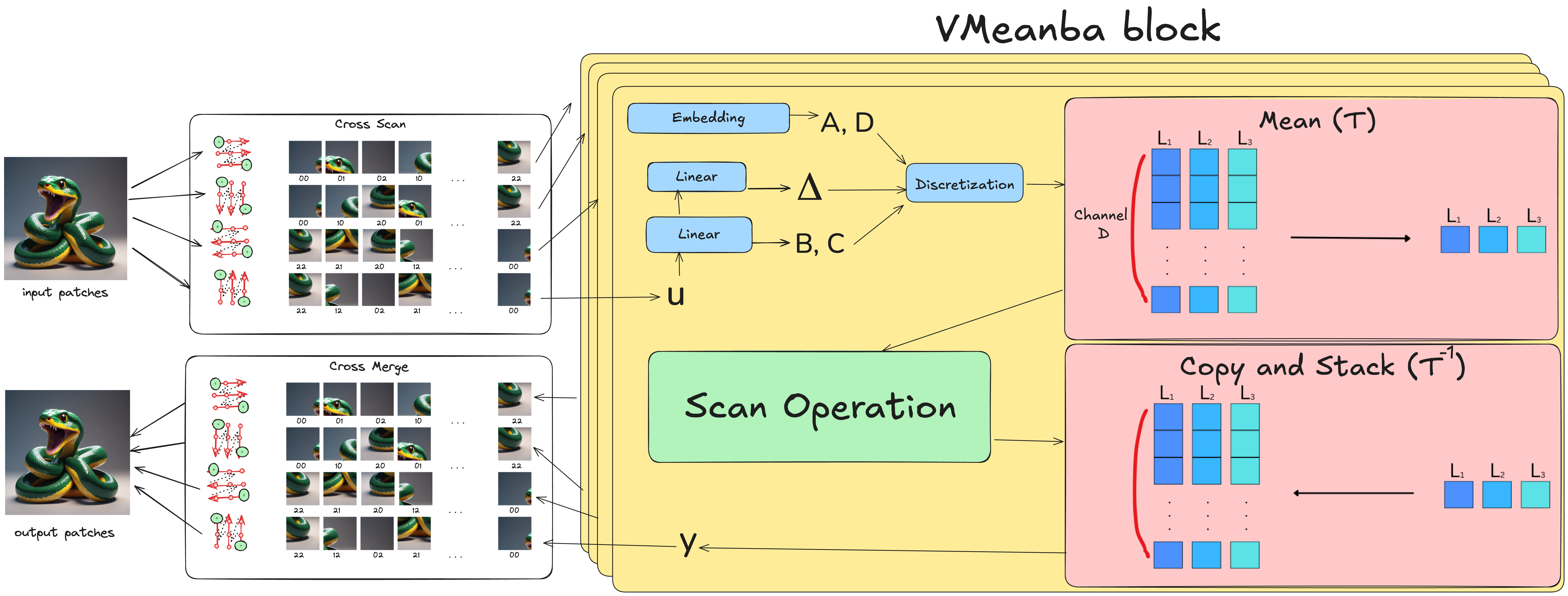
技术框架:VMeanba方法主要包含以下步骤:首先,对SSM块的输出激活图在通道维度上进行平均,得到一个单通道的激活图。然后,使用这个单通道的激活图进行后续的计算。整个过程无需训练,可以直接应用于现有的SSM模型。该方法可以嵌入到各种基于SSM的视觉模型中。
关键创新:VMeanba的关键创新在于发现并利用了SSM输出激活在通道维度上的低方差特性。通过通道均值化,有效地降低了计算复杂度,而无需重新训练模型。这种免训练的压缩方法具有很高的实用价值。
关键设计:VMeanba方法的关键设计在于通道均值化操作。具体来说,对于一个形状为(B, C, H, W)的激活图,其中B是batch size,C是通道数,H和W是高度和宽度,VMeanba将其转换为形状为(B, 1, H, W)的激活图,通过对C个通道的值进行平均。没有引入额外的参数或损失函数。该方法可以灵活地应用于不同的SSM架构。
🖼️ 关键图片

📊 实验亮点
实验结果表明,VMeanba在图像分类和语义分割任务中实现了显著的加速,最高可达1.12倍,而精度损失小于3%。即使与40%的非结构化剪枝相结合,精度下降仍然控制在3%以内。这些结果验证了VMeanba在降低计算复杂度的同时,能够保持良好的性能。
🎯 应用场景
VMeanba可应用于各种需要高性能和低功耗的图像处理场景,例如移动设备上的图像识别、自动驾驶中的实时感知、以及嵌入式系统中的视觉任务。该方法能够有效降低计算开销,提高模型运行速度,从而扩展了SSM在资源受限环境下的应用范围。
📄 摘要(原文)
Vision transformers dominate image processing tasks due to their superior performance. However, the quadratic complexity of self-attention limits the scalability of these systems and their deployment on resource-constrained devices. State Space Models (SSMs) have emerged as a solution by introducing a linear recurrence mechanism, which reduces the complexity of sequence modeling from quadratic to linear. Recently, SSMs have been extended to high-resolution vision tasks. Nonetheless, the linear recurrence mechanism struggles to fully utilize matrix multiplication units on modern hardware, resulting in a computational bottleneck. We address this issue by introducing \textit{VMeanba}, a training-free compression method that eliminates the channel dimension in SSMs using mean operations. Our key observation is that the output activations of SSM blocks exhibit low variances across channels. Our \textit{VMeanba} leverages this property to optimize computation by averaging activation maps across the channel to reduce the computational overhead without compromising accuracy. Evaluations on image classification and semantic segmentation tasks demonstrate that \textit{VMeanba} achieves up to a 1.12x speedup with less than a 3\% accuracy loss. When combined with 40\% unstructured pruning, the accuracy drop remains under 3\%.