LLaVA-SLT: Visual Language Tuning for Sign Language Translation
作者: Han Liang, Chengyu Huang, Yuecheng Xu, Cheng Tang, Weicai Ye, Juze Zhang, Xin Chen, Jingyi Yu, Lan Xu
分类: cs.CV
发布日期: 2024-12-21
💡 一句话要点
提出LLaVA-SLT,利用视觉语言微调提升无gloss标注的手语翻译性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 手语翻译 视觉语言模型 多模态学习 无Gloss标注 对比学习
📋 核心要点
- 手语翻译依赖昂贵的gloss标注数据,限制了发展,无gloss方法精度仍有差距。
- LLaVA-SLT通过语言持续预训练、视觉对比预训练和视觉语言微调,有效利用LLM能力。
- 实验表明LLaVA-SLT超越现有方法,利用额外无标注数据甚至接近gloss标注方法的精度。
📝 摘要(中文)
手语翻译(SLT)领域一直受限于需要大量gloss标注的数据集。最近无gloss的SLT方法展现出潜力,但在翻译准确率上通常落后于基于gloss的方法。为了缩小这一差距,我们提出了LLaVA-SLT,一个开创性的大型多模态模型(LMM)框架,旨在通过有效学习的视觉语言嵌入来利用大型语言模型(LLM)的能力。我们的模型通过三个阶段训练。首先,我们提出语言持续预训练,扩大LLM规模,并使用大型语料库数据集将其适应于手语领域,从而有效增强其关于手语的文本语言知识。然后,我们采用视觉对比预训练,将视觉编码器与大规模预训练的文本编码器对齐。我们提出了分层视觉编码器,学习与LLM token嵌入兼容的鲁棒的词级中间表示。最后,我们提出视觉语言微调,冻结预训练模型,并采用轻量级可训练的MLP连接器,有效地将预训练的视觉语言嵌入映射到LLM token嵌入空间,从而实现下游SLT任务。我们的综合实验表明,LLaVA-SLT优于最先进的方法。通过使用额外的无标注数据,它甚至接近于基于gloss的准确率。
🔬 方法详解
问题定义:手语翻译任务中,依赖大量gloss标注数据成本高昂,限制了模型的发展和泛化能力。虽然现有的无gloss手语翻译方法取得了一定进展,但其翻译精度与基于gloss的方法相比仍有显著差距,无法满足实际应用的需求。
核心思路:LLaVA-SLT的核心思路是利用大型语言模型(LLM)强大的语言理解和生成能力,通过有效的视觉语言嵌入学习,将视觉信息(手语视频)与文本信息(目标语言)对齐,从而实现高质量的无gloss手语翻译。该方法旨在弥合视觉和语言之间的语义鸿沟,使LLM能够理解手语视频的含义并生成准确的翻译。
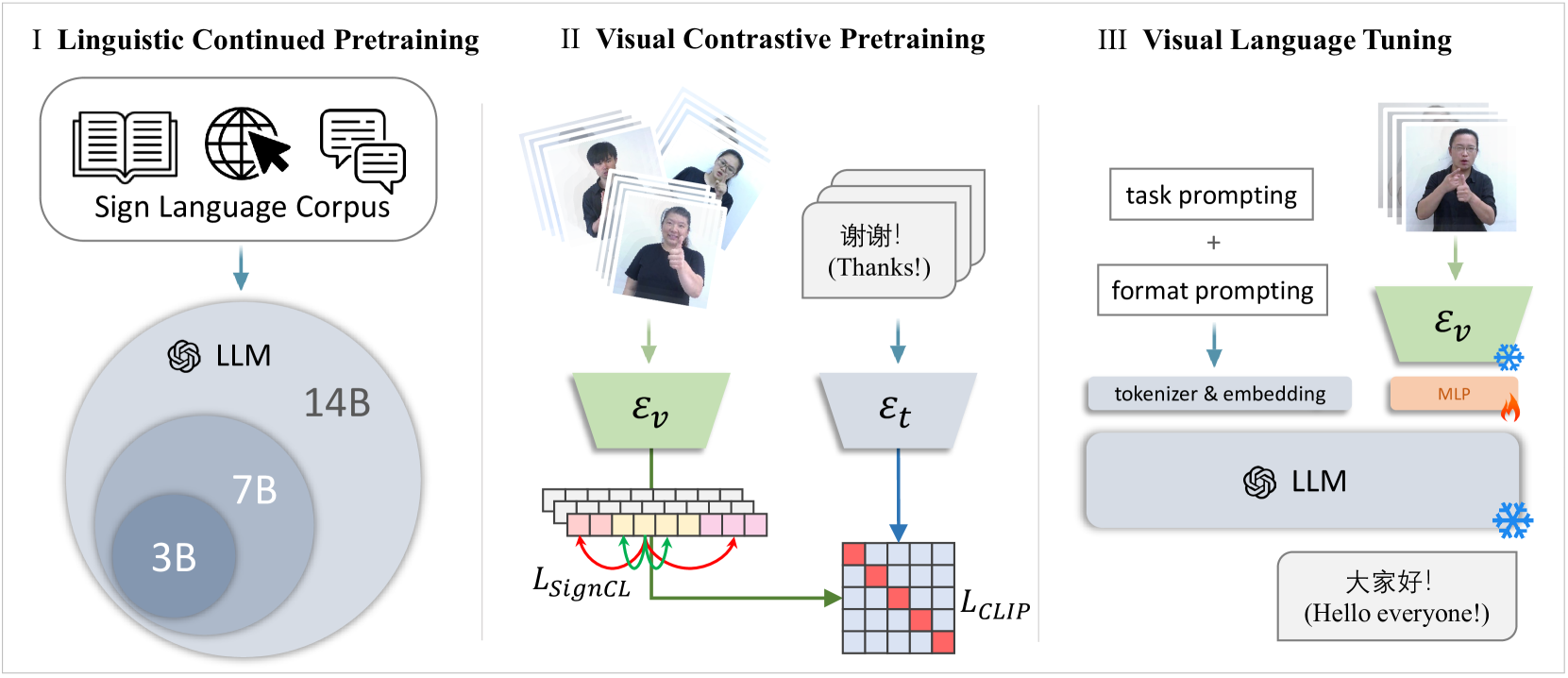
技术框架:LLaVA-SLT的整体框架包含三个主要阶段:1) 语言持续预训练:扩展LLM规模,并使用大规模手语相关文本数据进行预训练,增强LLM对手语领域的语言知识。2) 视觉对比预训练:将视觉编码器与预训练的文本编码器对齐,学习视觉特征与文本特征之间的对应关系。3) 视觉语言微调:冻结预训练的LLM和视觉编码器,使用轻量级的MLP连接器将视觉特征映射到LLM的token嵌入空间,并在手语翻译任务上进行微调。
关键创新:LLaVA-SLT的关键创新在于其三阶段训练策略,特别是视觉语言微调阶段。通过冻结预训练模型并使用轻量级MLP连接器,该方法能够高效地将视觉信息融入到LLM中,避免了对整个LLM进行微调的计算成本。此外,分层视觉编码器的设计,学习鲁棒的词级中间表示,也提升了模型性能。
关键设计:在语言持续预训练阶段,使用了大规模的手语相关文本语料库。在视觉对比预训练阶段,采用了对比学习损失函数,以最大化视觉特征和文本特征之间的相似性。在视觉语言微调阶段,MLP连接器的结构和参数数量经过精心设计,以平衡模型性能和计算效率。分层视觉编码器提取不同层次的视觉特征,以更好地捕捉手语视频中的语义信息。
🖼️ 关键图片


📊 实验亮点
LLaVA-SLT在无gloss手语翻译任务上取得了显著的性能提升,超越了现有的state-of-the-art方法。通过利用额外的无标注数据,LLaVA-SLT的性能甚至接近于基于gloss的方法,证明了其在降低标注成本方面的潜力。具体的性能数据需要在论文中查找。
🎯 应用场景
LLaVA-SLT在手语翻译领域具有广泛的应用前景,可用于辅助听障人士的交流,例如实时手语翻译、手语教学、手语内容生成等。该研究的成功将促进无障碍交流的发展,提高听障人士的生活质量,并推动多模态人工智能技术的进步。
📄 摘要(原文)
In the realm of Sign Language Translation (SLT), reliance on costly gloss-annotated datasets has posed a significant barrier. Recent advancements in gloss-free SLT methods have shown promise, yet they often largely lag behind gloss-based approaches in terms of translation accuracy. To narrow this performance gap, we introduce LLaVA-SLT, a pioneering Large Multimodal Model (LMM) framework designed to leverage the power of Large Language Models (LLMs) through effectively learned visual language embeddings. Our model is trained through a trilogy. First, we propose linguistic continued pretraining. We scale up the LLM and adapt it to the sign language domain using an extensive corpus dataset, effectively enhancing its textual linguistic knowledge about sign language. Then, we adopt visual contrastive pretraining to align the visual encoder with a large-scale pretrained text encoder. We propose hierarchical visual encoder that learns a robust word-level intermediate representation that is compatible with LLM token embeddings. Finally, we propose visual language tuning. We freeze pretrained models and employ a lightweight trainable MLP connector. It efficiently maps the pretrained visual language embeddings into the LLM token embedding space, enabling downstream SLT task. Our comprehensive experiments demonstrate that LLaVA-SLT outperforms the state-of-the-art methods. By using extra annotation-free data, it even closes to the gloss-based accuracy.