Cross-View Consistency Regularisation for Knowledge Distillation
作者: Weijia Zhang, Dongnan Liu, Weidong Cai, Chao Ma
分类: cs.CV
发布日期: 2024-12-21
备注: Accepted by ACM Multimedia 2024
💡 一句话要点
提出基于跨视角一致性正则化的知识蒸馏方法,提升logit蒸馏性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 知识蒸馏 跨视角学习 一致性正则化 模型压缩 深度学习
📋 核心要点
- 基于logit的知识蒸馏受限于教师模型的过度自信和确认偏差,影响学生模型的学习效果。
- 引入内视角和跨视角正则化,并结合置信度软标签挖掘,以提升蒸馏信号质量并缓解确认偏差。
- CRLD在多个数据集和模型架构上取得了SOTA结果,且无需引入额外的网络参数,泛化性能优秀。
📝 摘要(中文)
知识蒸馏(KD)是一种成熟的范式,用于将复杂模型的知识迁移到轻量级高效模型。近年来,基于logit的KD方法在性能上迅速赶上基于特征的方法。然而,之前的研究表明,基于logit的方法在训练过程中仍然受到两个主要问题的限制,即过度自信的教师和确认偏差。受到跨视角学习在半监督学习等领域成功的启发,本文将内视角和跨视角正则化引入到标准的基于logit的蒸馏框架中,以解决上述问题。我们还进行了基于置信度的软标签挖掘,以提高从教师处提取的蒸馏信号的质量,从而进一步缓解确认偏差问题。尽管其表面上很简单,但所提出的基于一致性正则化的Logit蒸馏(CRLD)显着提升了学生模型的学习能力,在标准的CIFAR-100、Tiny-ImageNet和ImageNet数据集上,跨多种教师和学生架构,创造了新的state-of-the-art结果,且没有引入额外的网络参数。与正在进行的基于logit的蒸馏研究正交,我们的方法具有出色的泛化性能,并且无需任何花哨的技巧,即可将各种现有方法的性能提升相当大的幅度。
🔬 方法详解
问题定义:现有基于logit的知识蒸馏方法受限于教师模型的过度自信和确认偏差。教师模型倾向于对错误类别给出过高的置信度,导致学生模型学习到错误的知识。确认偏差是指学生模型倾向于相信教师模型的预测,即使这些预测是错误的,从而阻碍了学生模型探索更优解的能力。
核心思路:论文的核心思路是通过引入跨视角一致性正则化来缓解教师模型的过度自信和确认偏差。具体来说,论文通过在学生模型的不同视角之间施加一致性约束,鼓励学生模型学习到更加鲁棒和泛化的知识。同时,论文还采用置信度软标签挖掘,选择教师模型置信度较高的样本进行蒸馏,从而提高蒸馏信号的质量。
技术框架:CRLD (Consistency-Regularisation-based Logit Distillation) 的整体框架是在标准的logit-based知识蒸馏框架的基础上,增加了内视角和跨视角正则化模块以及置信度软标签挖掘模块。首先,教师模型和学生模型对输入样本进行预测,得到各自的logit输出。然后,通过置信度软标签挖掘模块,选择教师模型置信度较高的样本。接下来,计算学生模型在不同视角下logit输出的一致性损失,并将其作为正则化项添加到总损失函数中。最后,通过优化总损失函数,训练学生模型。
关键创新:论文的关键创新在于引入了跨视角一致性正则化来缓解教师模型的过度自信和确认偏差。与现有的基于logit的知识蒸馏方法相比,CRLD能够更好地利用教师模型的知识,并提高学生模型的泛化能力。此外,置信度软标签挖掘也进一步提高了蒸馏信号的质量。
关键设计:CRLD的关键设计包括:1) 内视角一致性正则化:对学生模型自身的预测结果进行扰动,例如添加高斯噪声,然后要求扰动前后的预测结果保持一致。2) 跨视角一致性正则化:使用不同的数据增强方法生成不同的视角,然后要求学生模型在不同视角下的预测结果保持一致。3) 置信度软标签挖掘:根据教师模型对每个类别的置信度,选择置信度较高的样本进行蒸馏。损失函数由蒸馏损失、内视角一致性损失和跨视角一致性损失三部分组成。
🖼️ 关键图片


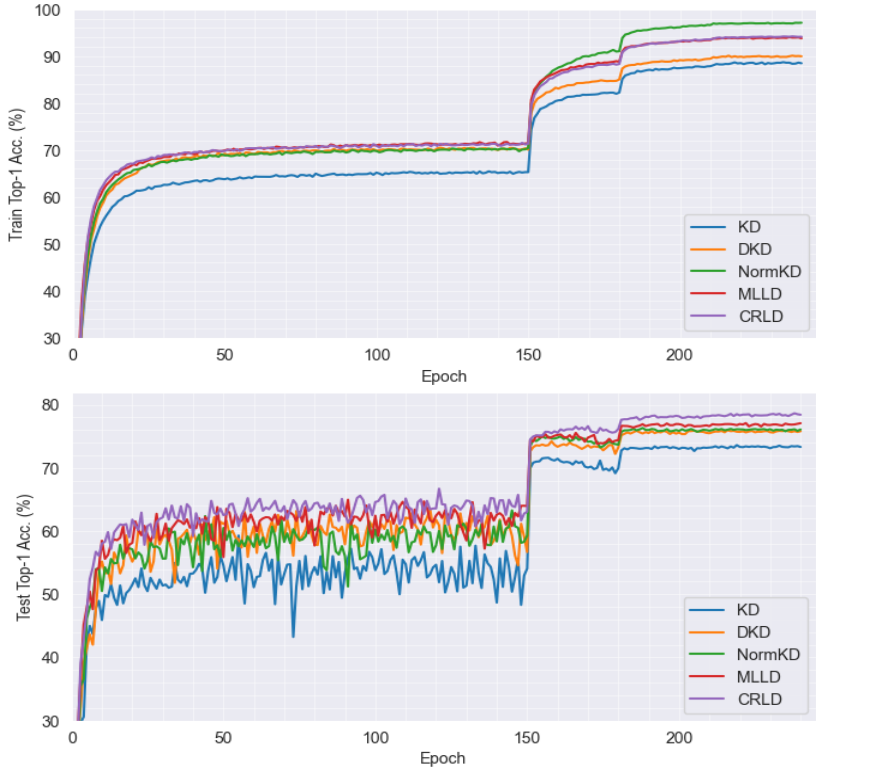
📊 实验亮点
CRLD在CIFAR-100、Tiny-ImageNet和ImageNet数据集上取得了显著的性能提升,创造了新的state-of-the-art结果。例如,在ImageNet数据集上,使用ResNet50作为教师模型,MobileNetV2作为学生模型,CRLD将学生模型的Top-1准确率提升了超过3个百分点。此外,CRLD还能够提升各种现有logit-based蒸馏方法的性能。
🎯 应用场景
该研究成果可广泛应用于模型压缩和加速领域,尤其是在资源受限的设备上部署高性能模型。例如,可以将大型预训练模型蒸馏到小型移动端模型,从而在移动设备上实现高效的图像识别、目标检测等任务。此外,该方法还可以应用于半监督学习和领域自适应等领域,提升模型的鲁棒性和泛化能力。
📄 摘要(原文)
Knowledge distillation (KD) is an established paradigm for transferring privileged knowledge from a cumbersome model to a lightweight and efficient one. In recent years, logit-based KD methods are quickly catching up in performance with their feature-based counterparts. However, previous research has pointed out that logit-based methods are still fundamentally limited by two major issues in their training process, namely overconfident teacher and confirmation bias. Inspired by the success of cross-view learning in fields such as semi-supervised learning, in this work we introduce within-view and cross-view regularisations to standard logit-based distillation frameworks to combat the above cruxes. We also perform confidence-based soft label mining to improve the quality of distilling signals from the teacher, which further mitigates the confirmation bias problem. Despite its apparent simplicity, the proposed Consistency-Regularisation-based Logit Distillation (CRLD) significantly boosts student learning, setting new state-of-the-art results on the standard CIFAR-100, Tiny-ImageNet, and ImageNet datasets across a diversity of teacher and student architectures, whilst introducing no extra network parameters. Orthogonal to on-going logit-based distillation research, our method enjoys excellent generalisation properties and, without bells and whistles, boosts the performance of various existing approaches by considerable margins.